Поисковая система Google (www.google.com) предоставляет множество возможностей для поиска. Все эти возможности – неоценимый инструмент поиска для пользователя впервые попавшего в Интернет и в то же время еще более мощное оружие вторжения и разрушения в руках людей с злыми намерениями, включая не только хакеров, но и некомпьютерных преступников и даже террористов.
(9475 просмотров за 1 неделю)
Денис Батранков
denisNOSPAMixi.ru
Внимание: Эта статья не руководство к действию. Эта статья написана для Вас, администраторы WEB серверов, чтобы у Вас пропало ложное ощущение, что Вы в безопасности, и Вы, наконец, поняли коварность этого метода получения информации и взялись за защиту своего сайта.
Введение
Я, например, за 0.14 секунд нашел 1670 страниц!
2. Введем другую строку, например:
inurl:"auth_user_file.txt"немного меньше, но этого уже достаточно для свободного скачивания и для подбора паролей (при помощи того же John The Ripper). Ниже я приведу еще ряд примеров.
Итак, Вам надо осознать, что поисковая машина Google посетила большинство из сайтов Интернет и сохранила в кэше информацию, содержащуюся на них. Эта кэшированная информация позволяет получить информацию о сайте и о содержимом сайта без прямого подключения к сайту, лишь копаясь в той информации, которая хранится внутри Google. Причем, если информация на сайте уже недоступна, то информация в кэше еще, возможно, сохранилась. Все что нужно для этого метода: знать некоторые ключевые слова Google. Этот технический прием называется Google Hacking.
Впервые информация о Google Hacking появилась на рассылке Bugtruck еще 3 года назад. В 2001 году эта тема была поднята одним французским студентом. Вот ссылка на это письмо http://www.cotse.com/mailing-lists/bugtraq/2001/Nov/0129.html . В нем приведены первые примеры таких запросов:
1) Index of /admin
2) Index of /password
3) Index of /mail
4) Index of / +banques +filetype:xls (for france...)
5) Index of / +passwd
6) Index of / password.txt
Нашумела эта тема в англо-читающей части Интернета совершенно недавно: после статьи Johnny Long вышедшей 7 мая 2004 года. Для более полного изучения Google Hacking советую зайти на сайт этого автора http://johnny.ihackstuff.com . В этой статье я лишь хочу ввести вас в курс дела.
Кем это может быть использовано:
- Журналисты, шпионы и все те люди, кто любит совать нос не в свои дела, могут использовать это для поиска компромата.
- Хакеры, разыскивающие подходящие цели для взлома.
Как работает Google.
Для продолжения разговора напомню некоторые из ключевых слов, используемых в запросах Google.
Поиск при помощи знака +
Google исключает из поиска неважные, по его мнению, слова. Например вопросительные слова, предлоги и артикли в английском языке: например are, of, where. В русском языке Google, похоже, все слова считает важными. Если слово исключается из поиска, то Google пишет об этом. Чтобы Google начал искать страницы с этими словами перед ними нужно добавить знак + без пробела перед словом. Например:
ace +of base
Поиск при помощи знака –
Если Google находит большое количество станиц, из которых необходимо исключить страницы с определенной тематикой, то можно заставить Google искать только страницы, на которых нет определенных слов. Для этого надо указать эти слова, поставив перед каждым знак – без пробела перед словом. Например:
рыбалка -водка
Поиск при помощи знака ~
Возможно, что вы захотите найти не только указанное слово, но также и его синонимы. Для этого перед словом укажите символ ~.
Поиск точной фразы при помощи двойных кавычек
Google ищет на каждой странице все вхождения слов, которые вы написали в строке запроса, причем ему неважно взаимное расположение слов, главное чтобы все указанные слова были на странице одновременно (это действие по умолчанию). Чтобы найти точную фразу – ее нужно взять в кавычки. Например:
"подставка для книг"
Чтобы было хоть одно из указанных слов нужно указать логическую операцию явно: OR. Например:
книга безопасность OR защита
Кроме того в строке поиска можно использовать знак * для обозначения любого слова и. для обозначения любого символа.
Поиск слов при помощи дополнительных операторов
Существуют поисковые операторы, которые указываются в строке поиска в формате:
operator:search_term
Пробелы рядом с двоеточием не нужны. Если вы вставите пробел после двоеточия, то увидите сообщение об ошибке, а перед ним, то Google будет использовать их как обычную строку для поиска.
Существуют группы дополнительных операторов поиска: языки - указывают на каком языке вы хотите увидеть результат, дата - ограничивают результаты за прошедшие три, шесть или 12 месяцев, вхождения - указывают в каком месте документа нужно искать строку: везде, в заголовке, в URL, домены - производить поиск по указанному сайту или наоборот исключить его из поиска, безопасный поиск - блокируют сайты содержащие указанный тип информации и удаляют их со страниц результатов поиска.
При этом некоторые операторы не нуждаются в дополнительном параметре, например запрос "cache:www.google.com
" может быть вызван, как полноценная строка для поиска, а некоторые ключевые слова, наоборот, требуют наличия слова для поиска, например " site:www.google.com help
". В свете нашей тематики посмотрим на следующие операторы:
Оператор |
Описание |
Требует дополнительного параметра? |
поиск только по указанному в search_term сайту |
||
поиск только в документах с типом search_term |
||
найти страницы, содержащие search_term в заголовке |
||
найти страницы, содержащие все слова search_term в заголовке |
||
найти страницы, содержащие слово search_term в своем адресе |
||
найти страницы, содержащие все слова search_term в своем адресе |
Оператор site: ограничивает поиск только по указанному сайту, причем можно указать не только доменное имя, но и IP адрес. Например, введите:
Оператор filetype: ограничивает поиск в файлах определенного типа. Например:
На дату выхода статьи Googlе может искать внутри 13 различных форматов файлов:
- Adobe Portable Document Format (pdf)
- Adobe PostScript (ps)
- Lotus 1-2-3 (wk1, wk2, wk3, wk4, wk5, wki, wks, wku)
- Lotus WordPro (lwp)
- MacWrite (mw)
- Microsoft Excel (xls)
- Microsoft PowerPoint (ppt)
- Microsoft Word (doc)
- Microsoft Works (wks, wps, wdb)
- Microsoft Write (wri)
- Rich Text Format (rtf)
- Shockwave Flash (swf)
- Text (ans, txt)
Оператор link:
показывает все страницы, которые указывают на указанную страницу.
Наверно всегда интересно посмотреть, как много мест в Интернете знают о тебе. Пробуем:
Оператор cache: показывает версию сайта в кеше Google, как она выглядела, когда Google последний раз посещал эту страницу. Берем любой, часто меняющийся сайт и смотрим:
Оператор intitle: ищет указанное слово в заголовке страницы. Оператор allintitle: является расширением – он ищет все указанные несколько слов в заголовке страницы. Сравните:
intitle:полет на марс
intitle:полет intitle:на intitle:марс
allintitle:полет на марс
Оператор inurl: заставляет Google показать все страницы содержащие в URL указанную строку. Оператор allinurl: ищет все слова в URL. Например:
allinurl:acid acid_stat_alerts.php
Эта команда особенно полезна для тех, у кого нет SNORT – хоть смогут посмотреть, как он работает на реальной системе.
Методы взлома при помощи Google
Итак, мы выяснили что, используя комбинацию вышеперечисленных операторов и ключевых слов, любой человек может заняться сбором нужной информации и поиском уязвимостей. Эти технические приемы часто называют Google Hacking.
Карта сайта
Можно использовать оператор site: для просмотра всех ссылок, которые Google нашел на сайте. Обычно страницы, которые динамически создаются скриптами, при помощи параметров не индексируются, поэтому некоторые сайты используют ISAPI фильтры, чтобы ссылки были не в виде /article.asp?num=10&dst=5 , а со слешами /article/abc/num/10/dst/5 . Это сделано для того, чтобы сайт вообще индексировался поисковиками.
Попробуем:
site:www.whitehouse.gov whitehouse
Google думает, что каждая страница сайта содержит слово whitehouse. Этим мы и пользуемся, чтобы получить все страницы.
Есть и упрощенный вариант:
site:whitehouse.gov
И что самое приятное - товарищи с whitehouse.gov даже не узнали, что мы посмотрели на структуру их сайта и даже заглянули в кэшированные странички, которые скачал себе Google. Это может быть использовано для изучения структуры сайтов и просмотра содержимого, оставаясь незамеченным до поры до времени.
Просмотр списка файлов в директориях
WEB серверы могут показывать списки директорий сервера вместо обычных HTML страниц. Обычно это делается для того, чтобы пользователи выбирали и скачивали определенные файлы. Однако во многих случаях у администраторов нет цели показать содержимое директории. Это возникает вследствие неправильной конфигурации сервера или отсутствия главной страницы в директории. В результате у хакера появляется шанс найти что-нибудь интересное в директории и воспользоваться этим для своих целей. Чтобы найти все такие страницы, достаточно заметить, что все они содержат в своем заголовке слова: index of. Но поскольку слова index of содержат не только такие страницы, то нужно уточнить запрос и учесть ключевые слова на самой странице, поэтому нам подойдут запросы вида:
intitle:index.of parent directory
intitle:index.of name size
Поскольку в основном листинги директорий сделаны намеренно, то вам, возможно, трудно будет найти ошибочно выведенные листинги с первого раза. Но, по крайней мере, вы уже сможете использовать листинги для определения версии WEB сервера, как описано ниже.
Получение версии WEB сервера.
Знание версии WEB сервера всегда полезно перед началом любой атака хакера. Опять же благодаря Google можно получить эту информацию без подключения к серверу. Если внимательно посмотреть на листинг директории, то можно увидеть, что там выводится имя WEB сервера и его версия.
Apache1.3.29 - ProXad Server at trf296.free.fr Port 80
Опытный администратор может подменить эту информацию, но, как правило, она соответствует истине. Таким образом, чтобы получить эту информацию достаточно послать запрос:
intitle:index.of server.at
Чтобы получить информацию для конкретного сервера уточняем запрос:
intitle:index.of server.at site:ibm.com
Или наоборот ищем сервера работающие на определенной версии сервера:
intitle:index.of Apache/2.0.40 Server at
Эта техника может быть использована хакером для поиска жертвы. Если у него, к примеру, есть эксплойт для определенной версии WEB сервера, то он может найти его и попробовать имеющийся эксплойт.
Также можно получить версию сервера, просматривая страницы, которые по умолчанию устанавливаются при установке свежей версии WEB сервера. Например, чтобы увидеть тестовую страницу Apache 1.2.6 достаточно набрать
intitle:Test.Page.for.Apache it.worked!
Мало того, некоторые операционные системы при установке сразу ставят и запускают WEB сервер. При этом некоторые пользователи даже об этом не подозревают. Естественно если вы увидите, что кто-то не удалил страницу по умолчанию, то логично предположить, что компьютер вообще не подвергался какой-либо настройке и, вероятно, уязвим для атак.
Попробуйте найти страницы IIS 5.0
allintitle:Welcome to Windows 2000 Internet Services
В случае с IIS можно определить не только версию сервера, но и версию Windows и Service Pack.
Еще одним способом определения версии WEB сервера является поиск руководств (страниц подсказок) и примеров, которые могут быть установлены на сайте по умолчанию. Хакеры нашли достаточно много способов использовать эти компоненты, чтобы получить привилегированный доступ к сайту. Именно поэтому нужно на боевом сайте удалить эти компоненты. Не говоря уже о том, что по наличию этих компонентов можно получить информацию о типе сервера и его версии. Например, найдем руководство по apache:
inurl:manual apache directives modules
Использование Google как CGI сканера.
CGI сканер или WEB сканер – утилита для поиска уязвимых скриптов и программ на сервере жертвы. Эти утилиты должны знать что искать, для этого у них есть целый список уязвимых файлов, например:
/cgi-bin/cgiemail/uargg.txt
/random_banner/index.cgi
/random_banner/index.cgi
/cgi-bin/mailview.cgi
/cgi-bin/maillist.cgi
/cgi-bin/userreg.cgi
/iissamples/ISSamples/SQLQHit.asp
/SiteServer/admin/findvserver.asp
/scripts/cphost.dll
/cgi-bin/finger.cgi
Мы может найти каждый из этих файлов с помощью Google, используя дополнительно с именем файла в строке поиска слова index of или inurl: мы можем найти сайты с уязвимыми скриптами, например:
allinurl:/random_banner/index.cgi
Пользуясь дополнительными знаниями, хакер может использовать уязвимость скрипта и с помощью этой уязвимости заставить скрипт выдать любой файл, хранящийся на сервере. Например файл паролей.
Как защитить себя от взлома через Google.
1. Не выкладывайте важные данные на WEB сервер.
Даже если вы выложили данные временно, то вы можете забыть об этом или кто-то успеет найти и забрать эти данные пока вы их не стерли. Не делайте так. Есть много других способов передачи данных, защищающих их от кражи.
2. Проверьте свой сайт.
Используйте описанные методы, для исследования своего сайта. Проверяйте периодически свой сайт новыми методами, которые появляются на сайте http://johnny.ihackstuff.com . Помните, что если вы хотите автоматизировать свои действия, то нужно получить специальное разрешение от Google. Если внимательно прочитать http://www.google.com/terms_of_service.html , то вы увидите фразу: You may not send automated queries of any sort to Google"s system without express permission in advance from Google.
3. Возможно, вам не нужно чтобы Google индексировал ваш сайт или его часть.
Google позволяет удалить ссылку на свой сайт или его часть из своей базы, а также удалить страницы из кэша. Кроме того вы можете запретить поиск изображений на вашем сайте, запретить показывать короткие фрагменты страниц в результатах поиска Все возможности по удалению сайта описаны на сранице http://www.google.com/remove.html . Для этого вы должны подтвердить, что вы действительно владелец этого сайта или вставить на страницу теги или
4. Используйте robots.txt
Известно, что поисковые машины заглядывают в файл robots.txt лежащий в корне сайта и не индексируют те части, которые помечены словом Disallow . Вы можете воспользоваться этим, для того чтобы часть сайта не индексировалась. Например, чтобы не индексировался весь сайт, создайте файл robots.txt содержащий две строчки:
User-agent: *
Disallow: /
Что еще бывает
Чтобы жизнь вам медом не казалась, скажу напоследок, что существуют сайты, которые следят за теми людьми, которые, используя вышеизложенные выше методы, разыскивают дыры в скриптах и WEB серверах. Примером такой страницы является
Приложение.
Немного сладкого. Попробуйте сами что-нибудь из следующего списка:
1. #mysql dump filetype:sql - поиск дампов баз данных mySQL
2. Host Vulnerability Summary Report - покажет вам какие уязвимости нашли другие люди
3. phpMyAdmin running on inurl:main.php - это заставит закрыть управление через панель phpmyadmin
4. not for distribution confidential
5. Request Details Control Tree Server Variables
6. Running in Child mode
7. This report was generated by WebLog
8. intitle:index.of cgiirc.config
9. filetype:conf inurl:firewall -intitle:cvs – может кому нужны кофигурационные файлы файрволов? :)
10. intitle:index.of finances.xls – мда....
11. intitle:Index of dbconvert.exe chats – логи icq чата
12. intext:Tobias Oetiker traffic analysis
13. intitle:Usage Statistics for Generated by Webalizer
14. intitle:statistics of advanced web statistics
15. intitle:index.of ws_ftp.ini – конфиг ws ftp
16. inurl:ipsec.secrets holds shared secrets – секретный ключ – хорошая находка
17. inurl:main.php Welcome to phpMyAdmin
18. inurl:server-info Apache Server Information
19. site:edu admin grades
20. ORA-00921: unexpected end of SQL command – получаем пути
21. intitle:index.of trillian.ini
22. intitle:Index of pwd.db
23. intitle:index.of people.lst
24. intitle:index.of master.passwd
25. inurl:passlist.txt
26. intitle:Index of .mysql_history
27. intitle:index of intext:globals.inc
28. intitle:index.of administrators.pwd
29. intitle:Index.of etc shadow
30. intitle:index.of secring.pgp
31. inurl:config.php dbuname dbpass
32. inurl:perform filetype:ini
Учебный центр "Информзащита" http://www.itsecurity.ru - ведущий специализированный центр в области обучения информационной безопасности (Лицензия Московского Комитета образования № 015470, Государственная аккредитация № 004251). Единственный авторизованный учебный центр компаний Internet Security Systems и Clearswift на территории России и стран СНГ. Авторизованный учебный центр компании Microsoft (специализация Security). Программы обучения согласованы с Гостехкомиссией России, ФСБ (ФАПСИ). Свидетельства об обучении и государственные документы о повышении квалификации.
Компания SoftKey – это уникальный сервис для покупателей, разработчиков, дилеров и аффилиат–партнеров. Кроме того, это один из лучших Интернет-магазинов ПО в России, Украине, Казахстане, который предлагает покупателям широкий ассортимент, множество способов оплаты, оперативную (часто мгновенную) обработку заказа, отслеживание процесса выполнения заказа в персональном разделе, различные скидки от магазина и производителей ПО.
В статье про я рассмотрел примеры и коды для вывода некоторых дополнительных информационных элементов на страницах постов: связных заметок, названий тегов/категорий и т.п. Похожей фишкой также являются ссылки на предыдущие и следующие WordPress записи. Данные линки будут полезны при навигации посетителей сайта, а также являются еще одним способом . Именно поэтому стараюсь добавлять их в каждый свой проект.
В реализации задачи нам помогут 4 функции, о которых расскажу ниже:
Поскольку речь идет о странице постов (Post), то в 99% случаев вам нужно будет редактировать файл шаблона single.php (либо тот, где в вашей теме задается формат вывода единичных статей). Функции используются в цикле Loop. Если же требуется убрать следующие / предыдущие записи в WordPress, то ищите соответствующий код в этом же файле шаблона и удаляйте (или закомментируйте) его.
Функция next_post_link
По умолчанию формируется линк на заметку, имеющую более новую дату создания сразу после текущей (т.к. все посты располагаются в хронологическом порядке). Вот как он выглядит в коде и на сайте:
Синтаксис функции:
- format (строка) — определяет общий формат генерируемой ссылки, где с помощью переменной %link можете задавать какой-то текст до и после нее. По умолчанию это просто линк со стрелочкой: ‘%link »’
- link (строка) — анкор ссылки на следующую запись в WordPress, параметр %title подставляет ее заголовок.
- in_same_term (boolean) — определяет будут ли рассматриваться в работе только элементы из текущей категории. Допустимые значения true / false (1 / 0), по умолчанию второй вариант.
- excluded_terms (строка или массив) — укажите ID категорий блога, заметки из которых будут исключены из выборки. Допускается либо массив array(2, 5, 4) либо написание в строку через запятую. Полезно при работе с GoGetLinks , когда нужно запретить показ рекламных постов в данном блоке.
- taxonomy (строка) — содержит название таксономии, из которой берутся следующие записи, если переменная $in_same_term = true.
Судя из скриншота выше, понятно, что все эти параметры не являются обязательными. Вот пример использования функции на одном из моих сайтов:
(следующая статья) %link →","%title", FALSE, 152) ?>
Здесь я задаю свой формат для отображения линка + исключаю из выборки все элементы, принадлежащие разделу ID = 152.
Если вам нужно вывести в WordPress следующий пост из той же категории, то пригодится код ниже (при этом игнорируется раздел ID = 33):
Когда хотите работать только с текущей конкретной таксономией, указывайте ее название в параметрах (например, testimonial):
>", TRUE, " ", "testimonial"); ?>
Функция previous_post_link
Принцип работы с предыдущими записями WordPress аналогичен приведенному выше описанию, как и синтаксис. Выглядит так:
Соответствующий код:
- format (строка) — задает формат , за которую отвечает переменная %link (добавляйте текст/теги до и после нее). По умолчанию — ‘« %link’.
- link (строка) — анкор линка, для вставки заголовка пишите %title.
- in_same_term (boolean) — если значение true, то будут выводиться только объекты из того же раздела блога.
- excluded_terms — убираем ненужные категории, указывайте ID через запятую (как строку) или массивом.
- taxonomy (строка) — определяет таксономию выборки предыдущей записи в WordPress, если активен параметр $in_same_term.
В одном из блогов использую:
%link", "<< Предыдущая", TRUE, "33"); ?>
Здесь делаем жирный шрифт + вместо заголовка элемента пишется определенная фраза (хотя лучше в перелинковке использовать тайтл). Выводятся объекты только текущей категории кроме той, у которой ID = 33.
Функция the_post_navigation
Данное решение объединяет обе ссылки на предыдущие и следующие записи WordPress. Это сделано для удобства, заменяет вызов двух функций одной. Если вам нужно получить на выходе HTML код без отображения, применяйте get_the_post_navigation() .
Синтаксис the_post_navigation максимально простой:
Где $args — набор разных не обязательных параметров:
- $prev_text — анкор предыдущей ссылки (по умолчанию %title).
- $next_text — аналогично текст линка но уже на следующий пост (изначально %title).
- $in_same_term (true/false) — позволяет показывать статьи только из текущей таксономии.
- $excluded_terms — исключаемые ID через запятую.
- $taxonomy — название таксономии для выборки, если in_same_term = true.
- $screen_reader_text — заголовок всего блока (по умолчанию — Post navigation).
Таким образом, мы видим, что здесь имеются такие же переменные, как и в прошлых «единичных» функциях previous_post_link, next_post_link: анкоры, выборка по таксономиям и т.п. Использование решения просто сделает ваш код более компактным, да и нет смысла повторять одни и те же параметры два раза.
Рассмотрим самую простую ситуацию, когда нужно вывести по элементам из той же категории:
"следующий: %title", "next_text" => "предыдущий: %title", "in_same_term" => true, "taxonomy" => "category", "screen_reader_text" => "Еще почитать",)); ?>
Функция posts_nav_link
Если я правильно понимаю, то ее можно использовать не только для отображения в единичной записи, но и в категорий, заметках по месяцам, и т.п. То есть в single.php она будет отвечать за ссылки на предыдущие/следующие WordPress статьи, а в архивных — за навигацию по страницам.
Синтаксис posts_nav_link:
- $sep — разделитель, отображаемый между ссылками (раньше был::, сейчас -).
- $prelabel — текст линка предыдущих элементов (по умолчанию: « Previous Page).
- $nxtlabel — текст для следующей страницы/постов (Next Page »).
Вот интересный пример с картинками вместо текстовых линков:
| "
,
" |
", ""); ?>
Только не забудьте загрузить изображения prev-img.png и next-img.png в директорию images в вашем . Думаю, аналогично добавляется и другой HTML код, если, допустим, нужно использовать какие-то DIV или class при выравнивании.
Итого. По навигации там еще есть несколько других разных функций, которые вы можете найти в кодексе. Надеюсь, с этими все более-менее понятно. Насчет posts_nav_link, если честно, не уверен, позволяет ли выводить предыдущие и следующие записи на единичной странице, т.к. не тестировал, хотя в описании это упоминается. Думаю, в таком случае более эффективно и желательно использовать the_post_navigation, что поновее и с куда бОльшим числом параметров.
Если есть какие-то вопросы по навигации между постами или дополнения, пишите ниже.
Получение частных данных не всегда означает взлом - иногда они опубликованы в общем доступе. Знание настроек Google и немного смекалки позволят найти массу интересного - от номеров кредиток до документов ФБР.
WARNING
Вся информация предоставлена исключительно в ознакомительных целях. Ни редакция, ни автор не несут ответственности за любой возможный вред, причиненный материалами данной статьи.К интернету сегодня подключают всё подряд, мало заботясь об ограничении доступа. Поэтому многие приватные данные становятся добычей поисковиков. Роботы-«пауки» уже не ограничиваются веб-страницами, а индексируют весь доступный в Сети контент и постоянно добавляют в свои базы не предназначенную для разглашения информацию. Узнать эти секреты просто - нужно лишь знать, как именно спросить о них.
Ищем файлы
В умелых руках Google быстро найдет все, что плохо лежит в Сети, - например, личную информацию и файлы для служебного использования. Их частенько прячут, как ключ под половиком: настоящих ограничений доступа нет, данные просто лежат на задворках сайта, куда не ведут ссылки. Стандартный веб-интерфейс Google предоставляет лишь базовые настройки расширенного поиска, но даже их будет достаточно.
Ограничить поиск по файлам определенного вида в Google можно с помощью двух операторов: filetype и ext . Первый задает формат, который поисковик определил по заголовку файла, второй - расширение файла, независимо от его внутреннего содержимого. При поиске в обоих случаях нужно указывать лишь расширение. Изначально оператор ext было удобно использовать в тех случаях, когда специфические признаки формата у файла отсутствовали (например, для поиска конфигурационных файлов ini и cfg, внутри которых может быть все что угодно). Сейчас алгоритмы Google изменились, и видимой разницы между операторами нет - результаты в большинстве случаев выходят одинаковые.

Фильтруем выдачу
По умолчанию слова и вообще любые введенные символы Google ищет по всем файлам на проиндексированных страницах. Ограничить область поиска можно по домену верхнего уровня, конкретному сайту или по месту расположения искомой последовательности в самих файлах. Для первых двух вариантов используется оператор site, после которого вводится имя домена или выбранного сайта. В третьем случае целый набор операторов позволяет искать информацию в служебных полях и метаданных. Например, allinurl отыщет заданное в теле самих ссылок, allinanchor - в тексте, снабженном тегом , allintitle - в заголовках страниц, allintext - в теле страниц.
Для каждого оператора есть облегченная версия с более коротким названием (без приставки all). Разница в том, что allinurl отыщет ссылки со всеми словами, а inurl - только с первым из них. Второе и последующие слова из запроса могут встречаться на веб-страницах где угодно. Оператор inurl тоже имеет отличия от другого схожего по смыслу - site . Первый также позволяет находить любую последовательность символов в ссылке на искомый документ (например, /cgi-bin/), что широко используется для поиска компонентов с известными уязвимостями.
Попробуем на практике. Берем фильтр allintext и делаем так, чтобы запрос выдал список номеров и проверочных кодов кредиток, срок действия которых истечет только через два года (или когда их владельцам надоест кормить всех подряд).
Allintext: card number expiration date /2017 cvv

Когда читаешь в новостях, что юный хакер «взломал серверы» Пентагона или NASA, украв секретные сведения, то в большинстве случаев речь идет именно о такой элементарной технике использования Google. Предположим, нас интересует список сотрудников NASA и их контактные данные. Наверняка такой перечень есть в электронном виде. Для удобства или по недосмотру он может лежать и на самом сайте организации. Логично, что в этом случае на него не будет ссылок, поскольку предназначен он для внутреннего использования. Какие слова могут быть в таком файле? Как минимум - поле «адрес». Проверить все эти предположения проще простого.

Inurl:nasa.gov filetype:xlsx "address"

Пользуемся бюрократией
Подобные находки - приятная мелочь. По-настоящему же солидный улов обеспечивает более детальное знание операторов Google для веб-мастеров, самой Сети и особенностей структуры искомого. Зная детали, можно легко отфильтровать выдачу и уточнить свойства нужных файлов, чтобы в остатке получить действительно ценные данные. Забавно, что здесь на помощь приходит бюрократия. Она плодит типовые формулировки, по которым удобно искать случайно просочившиеся в Сеть секретные сведения.
Например, обязательный в канцелярии министерства обороны США штамп Distribution statement означает стандартизированные ограничения на распространение документа. Литерой A отмечаются публичные релизы, в которых нет ничего секретного; B - предназначенные только для внутреннего использования, C - строго конфиденциальные и так далее до F. Отдельно стоит литера X, которой отмечены особо ценные сведения, представляющие государственную тайну высшего уровня. Пускай такие документы ищут те, кому это положено делать по долгу службы, а мы ограничимся файлами с литерой С. Согласно директиве DoDI 5230.24, такая маркировка присваивается документам, содержащим описание критически важных технологий, попадающих под экспортный контроль. Обнаружить столь тщательно охраняемые сведения можно на сайтах в домене верхнего уровня.mil, выделенного для армии США.
"DISTRIBUTION STATEMENT C" inurl:navy.mil

Очень удобно, что в домене.mil собраны только сайты из ведомства МО США и его контрактных организаций. Поисковая выдача с ограничением по домену получается исключительно чистой, а заголовки - говорящими сами за себя. Искать подобным образом российские секреты практически бесполезно: в доменах.ru и.рф царит хаос, да и названия многих систем вооружения звучат как ботанические (ПП «Кипарис», САУ «Акация») или вовсе сказочные (ТОС «Буратино»).

Внимательно изучив любой документ с сайта в домене.mil, можно увидеть и другие маркеры для уточнения поиска. Например, отсылку к экспортным ограничениям «Sec 2751», по которой также удобно искать интересную техническую информацию. Время от времени ее изымают с официальных сайтов, где она однажды засветилась, поэтому, если в поисковой выдаче не удается перейти по интересной ссылке, воспользуйся кешем Гугла (оператор cache) или сайтом Internet Archive.
Забираемся в облака
Помимо случайно рассекреченных документов правительственных ведомств, в кеше Гугла временами всплывают ссылки на личные файлы из Dropbox и других сервисов хранения данных, которые создают «приватные» ссылки на публично опубликованные данные. С альтернативными и самодельными сервисами еще хуже. Например, следующий запрос находит данные всех клиентов Verizon, у которых на роутере установлен и активно используется FTP-сервер.
Allinurl:ftp:// verizon.net
Таких умников сейчас нашлось больше сорока тысяч, а весной 2015-го их было на порядок больше. Вместо Verizon.net можно подставить имя любого известного провайдера, и чем он будет известнее, тем крупнее может быть улов. Через встроенный FTP-сервер видно файлы на подключенном к маршрутизатору внешнем накопителе. Обычно это NAS для удаленной работы, персональное облако или какая-нибудь пиринговая качалка файлов. Все содержимое таких носителей оказывается проиндексировано Google и другими поисковиками, поэтому получить доступ к хранящимся на внешних дисках файлам можно по прямой ссылке.

Подсматриваем конфиги
До повальной миграции в облака в качестве удаленных хранилищ рулили простые FTP-серверы, в которых тоже хватало уязвимостей. Многие из них актуальны до сих пор. Например, у популярной программы WS_FTP Professional данные о конфигурации, пользовательских аккаунтах и паролях хранятся в файле ws_ftp.ini . Его просто найти и прочитать, поскольку все записи сохраняются в текстовом формате, а пароли шифруются алгоритмом Triple DES после минимальной обфускации. В большинстве версий достаточно просто отбросить первый байт.

Расшифровать такие пароли легко с помощью утилиты WS_FTP Password Decryptor или бесплатного веб-сервиса .

Говоря о взломе произвольного сайта, обычно подразумевают получение пароля из логов и бэкапов конфигурационных файлов CMS или приложений для электронной коммерции. Если знаешь их типовую структуру, то легко сможешь указать ключевые слова. Строки, подобные встречающимся в ws_ftp.ini , крайне распространены. Например, в Drupal и PrestaShop обязательно есть идентификатор пользователя (UID) и соответствующий ему пароль (pwd), а хранится вся информация в файлах с расширением.inc. Искать их можно следующим образом:
"pwd=" "UID=" ext:inc
Раскрываем пароли от СУБД
В конфигурационных файлах SQL-серверов имена и адреса электронной почты пользователей хранятся в открытом виде, а вместо паролей записаны их хеши MD5. Расшифровать их, строго говоря, невозможно, однако можно найти соответствие среди известных пар хеш - пароль.

До сих пор встречаются СУБД, в которых не используется даже хеширование паролей. Конфигурационные файлы любой из них можно просто посмотреть в браузере.
Intext:DB_PASSWORD filetype:env

С появлением на серверах Windows место конфигурационных файлов отчасти занял реестр. Искать по его веткам можно точно таким же образом, используя reg в качестве типа файла. Например, вот так:
Filetype:reg HKEY_CURRENT_USER "Password"=
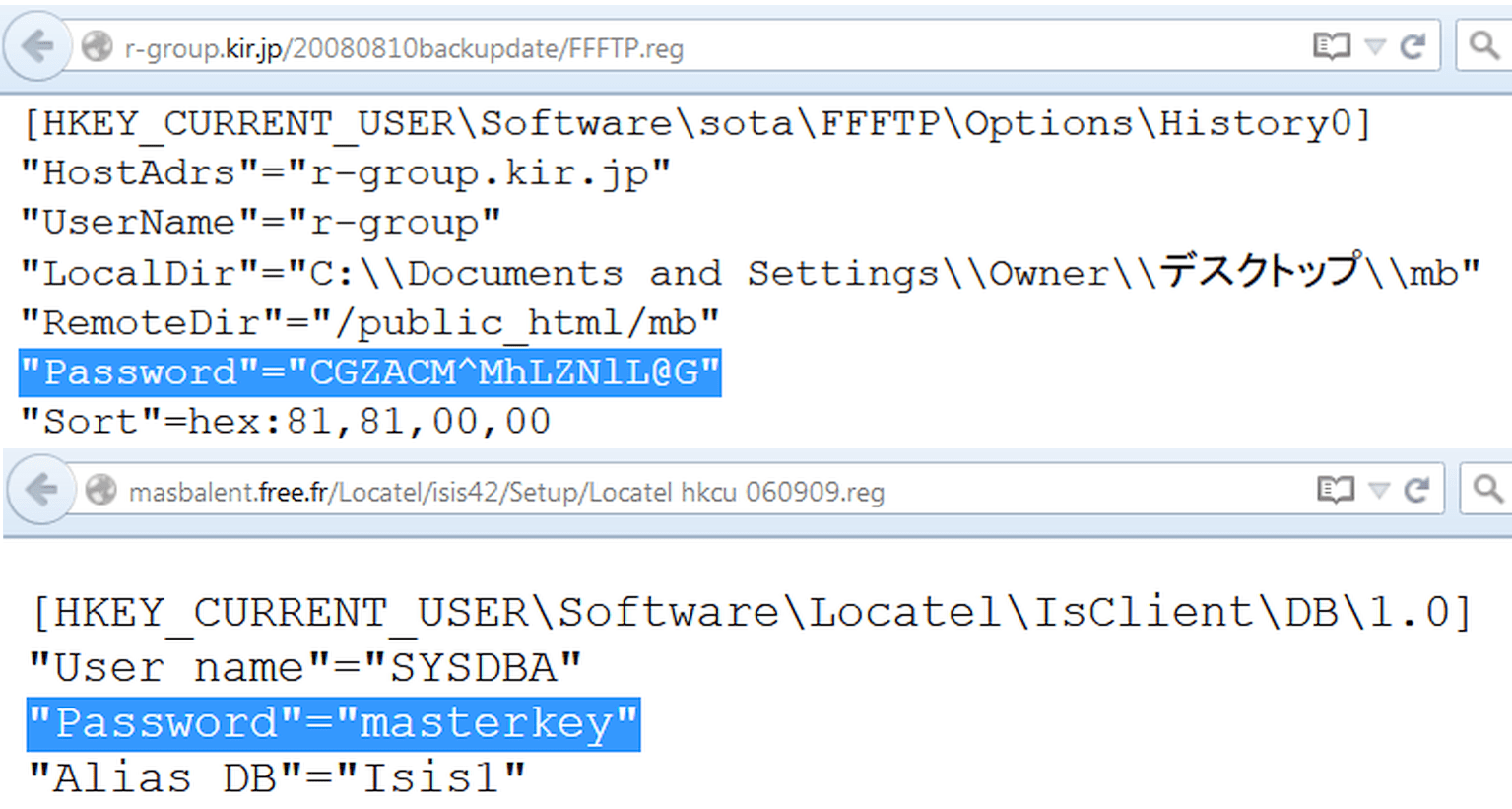
Не забываем про очевидное
Иногда добраться до закрытой информации удается с помощью случайно открытых и попавших в поле зрения Google данных. Идеальный вариант - найти список паролей в каком-нибудь распространенном формате. Хранить сведения аккаунтов в текстовом файле, документе Word или электронной таблице Excel могут только отчаянные люди, но как раз их всегда хватает.
Filetype:xls inurl:password

С одной стороны, есть масса средств для предотвращения подобных инцидентов. Необходимо указывать адекватные права доступа в htaccess, патчить CMS, не использовать левые скрипты и закрывать прочие дыры. Существует также файл со списком исключений robots.txt, запрещающий поисковикам индексировать указанные в нем файлы и каталоги. С другой стороны, если структура robots.txt на каком-то сервере отличается от стандартной, то сразу становится видно, что на нем пытаются скрыть.

Список каталогов и файлов на любом сайте предваряется стандартной надписью index of. Поскольку для служебных целей она должна встречаться в заголовке, то имеет смысл ограничить ее поиск оператором intitle . Интересные вещи находятся в каталогах /admin/, /personal/, /etc/ и даже /secret/.

Следим за обновлениями
Актуальность тут крайне важна: старые уязвимости закрывают очень медленно, но Google и его поисковая выдача меняются постоянно. Есть разница даже между фильтром «за последнюю секунду» (&tbs=qdr:s в конце урла запроса) и «в реальном времени» (&tbs=qdr:1).
Временной интервал даты последнего обновления файла у Google тоже указывается неявно. Через графический веб-интерфейс можно выбрать один из типовых периодов (час, день, неделя и так далее) либо задать диапазон дат, но такой способ не годится для автоматизации.
По виду адресной строки можно догадаться только о способе ограничить вывод результатов с помощью конструкции &tbs=qdr: . Буква y после нее задает лимит в один год (&tbs=qdr:y), m показывает результаты за последний месяц, w - за неделю, d - за прошедший день, h - за последний час, n - за минуту, а s - за секунду. Самые свежие результаты, только что ставшие известными Google, находится при помощи фильтра &tbs=qdr:1 .
Если требуется написать хитрый скрипт, то будет полезно знать, что диапазон дат задается в Google в юлианском формате через оператор daterange . Например, вот так можно найти список документов PDF со словом confidential, загруженных c 1 января по 1 июля 2015 года.
Confidential filetype:pdf daterange:2457024-2457205
Диапазон указывается в формате юлианских дат без учета дробной части. Переводить их вручную с григорианского календаря неудобно. Проще воспользоваться конвертером дат .
Таргетируемся и снова фильтруем
Помимо указания дополнительных операторов в поисковом запросе их можно отправлять прямо в теле ссылки. Например, уточнению filetype:pdf соответствует конструкция as_filetype=pdf . Таким образом удобно задавать любые уточнения. Допустим, выдача результатов только из Республики Гондурас задается добавлением в поисковый URL конструкции cr=countryHN , а только из города Бобруйск - gcs=Bobruisk . В разделе для разработчиков можно найти полный список .
Средства автоматизации Google призваны облегчить жизнь, но часто добавляют проблем. Например, по IP пользователя через WHOIS определяется его город. На основании этой информации в Google не только балансируется нагрузка между серверами, но и меняются результаты поисковой выдачи. В зависимости от региона при одном и том же запросе на первую страницу попадут разные результаты, а часть из них может вовсе оказаться скрытой. Почувствовать себя космополитом и искать информацию из любой страны поможет ее двухбуквенный код после директивы gl=country . Например, код Нидерландов - NL, а Ватикану и Северной Корее в Google свой код не положен.
Часто поисковая выдача оказывается замусоренной даже после использования нескольких продвинутых фильтров. В таком случае легко уточнить запрос, добавив к нему несколько слов-исключений (перед каждым из них ставится знак минус). Например, со словом Personal часто употребляются banking , names и tutorial . Поэтому более чистые поисковые результаты покажет не хрестоматийный пример запроса, а уточненный:
Intitle:"Index of /Personal/" -names -tutorial -banking
Пример напоследок
Искушенный хакер отличается тем, что обеспечивает себя всем необходимым самостоятельно. Например, VPN - штука удобная, но либо дорогая, либо временная и с ограничениями. Оформлять подписку для себя одного слишком накладно. Хорошо, что есть групповые подписки, а с помощью Google легко стать частью какой-нибудь группы. Для этого достаточно найти файл конфигурации Cisco VPN, у которого довольно нестандартное расширение PCF и узнаваемый путь: Program Files\Cisco Systems\VPN Client\Profiles . Один запрос, и ты вливаешься, к примеру, в дружный коллектив Боннского университета.
Filetype:pcf vpn OR Group

INFO
Google находит конфигурационные файлы с паролями, но многие из них записаны в зашифрованном виде или заменены хешами. Если видишь строки фиксированной длины, то сразу ищи сервис расшифровки.Пароли хранятся в зашифрованном виде, но Морис Массар уже написал программу для их расшифровки и предоставляет ее бесплатно через thecampusgeeks.com .
При помощи Google выполняются сотни разных типов атак и тестов на проникновение. Есть множество вариантов, затрагивающих популярные программы, основные форматы баз данных, многочисленные уязвимости PHP, облаков и так далее. Если точно представлять то, что ищешь, это сильно упростит получение нужной информации (особенно той, которую не планировали делать всеобщим достоянием). Не Shodan единый питает интересными идеями, но всякая база проиндексированных сетевых ресурсов!
Интерфейс Facebook странный и местами совершенно не логичный. Но так уж получилось, что почти все, с кем я общаюсь, оказались там, так что приходится терпеть.
Многое в Facebook неочевидно. Я постарался собрать в этом посте то, что я нашёл не сразу, а многие наверняка не нашли до сих пор.
Лента
По умолчанию Facebook формирует ленту популярных записей. При этом на разных компьютерах она может быть совершенно разной. Чтобы заставить Facebook формировать "обычную" ленту по времени щёлкните в галочку справа от слова "Лента новостей" и выберите там "Последние".К сожалению, в мобильном приложении для Android лента формируется только по популярности.
Чистка ленты
На Facebook я всегда добавляю в друзья всех, кто просится, но читать всякую ерунду в ленте я совсем не хочу. Для того, чтобы убрать из своей ленты ненужные публикации нет неоходимости никого убирать из друзей, достаточно отключить подписку. Как только вы видите в ленте что-то то ненужное, щёлкаете в галочку справа и выбираете "Отменить подписку на...". После этого публикации этого пользователя больше никогда не появятся в вашей ленте.
Уведомления
Когда вы оставляете любой комментарий к любой записи или фотографии, Facebook начинает уведомлять вас о всех новых комментариях. Чтобы от этого отказаться, нужно выключить уведомления. Для разных объектов это делается в разных местах. Со статусом всё просто - жмём галочку справа от статуса и выбираем "Не получать уведомления".


Увы, в мобильном приложении для Android отменять подписку на комментарии нельзя.
Поиск по сообщениям
В Facebook есть поиск по личным сообщениям, но мало кто знает, куда он запрятан. Нажмите на кнопку сообщений, затем нажмите "показать все" внизу открывшегося окна.
Откроется интерфейс сообщений, в котором сверху появится вторая строка поиска.

Там можно искать любые слова во всех личных сообщениях, написанных за всё время использования Facebook.
Борьба с Messenger
Facebook требует, чтобы на мобильных устройствах стояло отдельное приложение для обмена сообщениями - Facebook Messenger. Многим он очень не нравится. Пока что есть способ продолжать обмениваться сообщениями на самом Facebook. Когда Facebook в очередной раз откажется показывать сообщения, требуя установить Messenger, зайдите в диспетчер приложений (в Android - Настройки системы - Приложения), найдите там Facebook и нажмите кнопку "Стереть данные". После этого запустите Facebook и заново введите логин и пароль. Некоторое время после этого сообщения будут работать, хотя Facebook периодически будет выводить окошко с предложением установить Messenger.Журнал действий
Часто в Facebook очень сложно что-то найти. Немного помогает следующая схема. Если вы видите что-то, что может пригодиться потом, поставьте лайк. В будущем по этому лайку можно будет найти публикацию в журнале действий. Чтобы открыть журнал нажмите маленькую галочку в правом верхнем углу интерфейса и в открывшемся меню выберите "Журнал действий".
Вставка публикации
У каждой публикации в Facebook есть ссылка "Вставить публикацию". Она выдаёт код, который можно вставить на любой сайт, где можно вставлять html (в том числе и ЖЖ). К сожалению возможность вставки видео похоже закрыли. Ещё неделю назад это работало, а сейчас на любые виде пишет "Эта публикация Facebook больше не доступна. Возможно, она была удалена или были изменены ее настройки конфиденциальности".Отключение автовоспроизведения видео
По умолчанию Facebook автоматически запускает воспроизведение всех видео в ленте без звука. На мобильных устройствах это может быть проблемой, так как потребляет много трафика.В браузере автовоспроизведение видео отключается так: щёлкаем в галочку в правом верхнем углу, там настройки, дальше - видео.

В Android - нажимаем три полоски справа в строке иконок, там "Настройки приложения" - "Автозапуск видео" - ставим "Выкл." или "Только Wi-fi". В последнем случае видео будут автозапускаться только при подключении по wi-fi.
Переход на публикацию
Для того, чтобы перейти из ленты на конкретную публикацию достаточно нажать на дату публикации, а ссылку на публикацию можно получить, просто щёлкнв правой кнопкой мыши в дату и выбрать там "Копировать ссылку". Спасибо за этот совет samon , zz_z_z , borhomey .
Наверняка, у загадочного Facebook ещё много секретов, до которых я пока не добрался.
Если вы знаете о других секретах Facebook- пишите в комментарии, добавлю в пост.
Сохранено
Доброго времени суток. Сегодня поговорим о защите и доступе к камерам видеонаблюдения. Их достаточно много и используются они для разных целей. Как всегда будем использоваться стандартную базу, которая позволит нам находить такие камеры и подбирать к ним пароли. Теория Большинство устройств после установки никто не настраивает или обновляет. Поэтому наша целевая аудитория находиться под популярными портам 8000, 8080 и 554. Если нужно провести сканирование сети, то лучше сразу выделять эти порты. Способ№1 Для наглядного примера можно посмотреть интересные запросы в поисковиках Shodan и Сensys. Рассмотрим несколько наглядных примеров с простыми запросами. has_screenshot:true port:8000 // 183 результата; has_screenshot:true port:8080 // 1025 результатов; has_screenshot:true port:554 // 694 результата; Вот таким простым способом можно получить доступ к большому количеству открытых камер, которые размещены в интересных местах: магазинах, больницах, заправках и т.д. Рассмотрим для наглядности несколько интересных вариантов. Приемная у врача Частный где-то в глубине Европы Класс где-то в Челябинске Магазин женской одежды Таким простым способом можно найти достаточно много интересных объектов, к которым открыт доступ. Не забывайте, что можно применять фильтр country для получения данных по странам. has_screenshot:true port:8000 country:ru has_screenshot:true port:8080 country:ru has_screenshot:true port:554 country:ru Способ №2 Можно воспользоваться поиском стандартных социальных сетей. Для этого лучше использовать заголовки страниц при просмотре изображений с камер, вот такая подборка среди самых интересных вариантов: inurl:/view.shtml inurl:ViewerFrame?Mode= inurl:ViewerFrame?Mode=Refresh inurl:view/index.shtml inurl:view/view.shtml intitle:”live view” intitle:axis intitle:liveapplet all in title:”Network Camera Network Camera” intitle:axis intitle:”video server” intitle:liveapplet inurl:LvAppl intitle:”EvoCam” inurl:”webcam.html” intitle:”Live NetSnap Cam-Server feed” intitle:”Live View / - AXIS 206M” intitle:”Live View / - AXIS 206W” intitle:”Live View / - AXIS 210″ inurl:indexFrame.shtml Axis intitle:start inurl:cgistart intitle:”WJ-NT104 Main Page” intitle:snc-z20 inurl:home/ intitle:snc-cs3 inurl:home/ intitle:snc-rz30 inurl:home/ intitle:”sony network camera snc-p1″ intitle:”sony network camera snc-m1″ intitle:”Toshiba Network Camera” user login intitle:”i-Catcher Console - Web Monitor” Пожинаем плоды и находим аэропорт Офис компании Добавим в коллекцию еще порт и можно завершать Способ №3 Этот способ является целевым. Он применяется когда у нас есть либо одна точка и нужно подобрать пароль или мы хотим прогнать базу по стандартным паролям и найти валидные результаты. Для этих целей отлично подойдет Hydra. Для этого необходимо подготовить словар. Можно пробежаться и поискать стандартные пароли для роутеров. Давайте рассмотрим на конкретном примере. Есть модель камеры, DCS-2103. Она достаточно часто встречается. Работает она через порт 80. Давайте воспользуемся соответствующими данными и найдем необходимую информацию в shadan. Далее собираем все IP потенциальных целей, которые нам интересны. Далее формируем список. Собираем список паролей и будем все это использовать это с помощью утилиты hydra. Для этого нам необходимо добавить в папку словарь, список IP и выполнить вот такую команду: hydra -l admin -P pass.txt -o good.txt -t 16 -vV -M targets.txt http-get В корневой папке должен быть файл pass.txt с паролями, логин мы используем один admin с параметром -l, если нужно задать словарь для логинов, то необходимо добавит в корневую директорию файл и прописать его с параметром -L. Подобранные результаты будут сохраняться в файле good.txt. Список IP адресов нужно добавить в корневой каталог с файлом targets.txt. Последняя фраза в команде http-get отвечает за соединение через порт 80. Пример работы программы Ввод команды и начало работы В конце хочу добавит немного информации о сканировании. Чтобы получить номера сетей можно воспользоваться отличным сервисом. Далее эти сетки нужно проверить на наличие необходимых нам портов. Сканеров рекомендовать не буду, но скажу что стоить двигать в сторону таких и подобных сканеров, как masscan, vnc scanner и другие. Можно написать на основе известной утилиты nmap. Главное задача - просканировать диапазон и найти активные IP с необходимыми портами. Заключение Помните, что помимо стандартного просмотра можно делать еще фото, записывать видео и скачивать его себе. Также можно управлять камерой и поворачивать в нужные направления. А самое интересное - это возможность включать звуки и говорить на некоторых камерах. Что можно тут посоветовать? Ставить надежный пароль доступа и обязательно перебрасывать порты.