Americký národní normalizační institut(Angličtina) A americký n národní s tandardy iústav, ANSI) je sdružení amerických průmyslových a obchodních skupin, které vyvíjí obchodní a komunikační standardy. Je členem ISO a IEC a zastupuje tam zájmy USA.
Příběh
ANSI byla původně založena v roce 1918, kdy pět inženýrských společností a tři vládní agentury založily „American Engineering Standards Committee“ ( AESC- Angličtina. Americký výbor pro technické standardy). V roce 1928 se výbor stal známým jako American Standards Association. JAKO- Angličtina. American Standards Association). V roce 1966 byla ASA reorganizována a stala se „Standardním institutem Spojených států amerických“ ( USASI- Angličtina. United States of America Standards Institute). Současný název byl přijat v roce 1969.
Do roku 1918 existovalo pět inženýrských společností zapojených do vývoje technických norem:
- Americký institut elektrických inženýrů (AIEE, nyní IEEE)
- Americká společnost strojních inženýrů (ASME)
- Americká společnost stavebních inženýrů (ASCE)
- Americký institut důlních inženýrů (AIME, nyní Americký institut důlních, metalurgických a ropných inženýrů)
- Americká společnost pro testování a materiály (nyní ASTM)
V roce 1916 se Americký institut elektrických inženýrů (nyní IEEE) chopil iniciativy, aby tyto organizace spojil a vytvořil nezávislý národní orgán pro koordinaci vývoje norem, harmonizaci a schvalování národních norem. Výše uvedených pět organizací se stalo hlavními členy United Engineering Society (United Engineering Society - UES), následně bylo k účasti v ní přizváno jako zakladatelé Ministerstvo války USA, námořnictvo(sloučeny v roce 1947, aby se staly americkým ministerstvem obrany) a obchodu.
V roce 1931 se organizace (v roce 1928 přejmenovaná na ASA) stala součástí amerického národního výboru Mezinárodní elektrotechnické komise (IEC), která byla založena v roce 1904 za účelem vývoje standardů v elektrotechnice a elektrotechnice.
členové
Mezi členy ANSI patří vládní agentury, organizace, akademické a mezinárodní organizace a jednotlivci. Celkem Institut zastupuje zájmy více než 270 000 společností a organizací a 30 milionů odborníků po celém světě /
Aktivita
Ačkoli ANSI sama nevyvíjí normy, Institut dohlíží na vývoj a používání norem prostřednictvím akreditace postupů organizací pro vývoj norem. Akreditace ANSI znamená, že postupy používané organizacemi vyvíjejícími normy splňují požadavky institutu na otevřenost, vyváženost, konsensus a řádný proces.
ANSI také označuje konkrétní standardy jako americké národní standardy nebo ANS, když institut určí, že standardy byly vyvinuty v prostředí, které je spravedlivé, dostupné a reagující na potřeby různých zúčastněných stran.
Mezinárodní aktivita
Kromě normalizačních aktivit v USA ANSI prosazuje mezinárodní používání amerických norem, obhajuje politické a technické postavení USA v mezinárodních a regionálních normalizačních organizacích a podporuje přijetí mezinárodních norem jako národních norem.
Institut je oficiálním zástupcem USA ve dvou hlavních mezinárodních normalizačních organizacích, v Mezinárodní organizaci pro normalizaci (ISO) jako zakládajícím členem a v Mezinárodní elektrotechnické komisi (IEC) prostřednictvím Národního výboru USA (USNC). ANSI je zapojena téměř do všech technický program ISO a IEC a řídí mnoho klíčových výborů a podskupin. V mnoha případech jsou americké normy předkládány ISO a IEC prostřednictvím ANSI nebo USNC, kde jsou přijímány zcela nebo částečně jako mezinárodní normy.
Přijetí norem ISO a IEC jako amerických norem se zvýšilo z 0,2 % v roce 1986 na 15,5 % v květnu 2012.
Směry standardizace
Ústav spravuje devět normalizačních skupin:
- ANSI Homeland Defense and Security Standardization Collaborative (HDSSC)
- Panel standardů ANSI nanotechnologií (ANSI-NSP – Panel standardů nanotechnologií ANSI)
- Panel standardů prevence krádeží ID a správy ID (IDSP – panel standardů prevence proti krádeži ID a správy ID)
- ANSI Energy Efficiency Standardization Coordination Collaborative (EESCC)
- Koordinace norem pro jadernou energii (NESCC-Nuclear Energy Standards Coordination Collaborative)
- Panel standardů elektrických vozidel (EVSP)
- Síť ANSI-NAM pro regulaci chemikálií
- Koordinační panel norem ANSI pro biopaliva
- Panel standardů zdravotnické informační technologie (HITSP)
- Americká certifikační agentura pro potrubí a stroje
Každá ze skupin se zabývá identifikací, koordinací a harmonizací dobrovolných norem souvisejících s těmito oblastmi. V roce 2009, ANSI a (NIST) vytvořily Nuclear Energy Standards Coordination Collaboration (NESCC). NESCC je společná iniciativa k identifikaci a splnění současné potřeby norem v jaderném průmyslu.
Normy
Z norem přijatých ústavem jsou známy tyto:
Na rozdíl od populární mylné představy ANSI nepřijala standardy 8bitových kódových stránek, ačkoli se podílela na vývoji kódování ISO-8859-1 a možná i některých dalších.
Poznámky
- O ANSI
- RFC
- ANSI: Historický přehled (neurčitý) . ansi.org. Staženo 31. října 2016.
- Historie ANSI
Za zmínku stojí, že všechna označení tlakových tříd ANSI mají určitý význam, a to hodnotu tlaku, ale pouze v jiných jednotkách, než jsme zvyklí. Všechna čísla za ANSI označují hodnotu nominálního (nominálního) tlaku: ANSI 150, ANSI 300, ANSI 600, ANSI 900, ANSI 1500, ANSI 2500 a ANSI 4500. Například ANSI 150 znamená, že jmenovitý tlak je 1150 psi. V angličtině se to píše jako Pound-force per Square Inch nebo zkráceně PSI.
V souladu s tím je tímto způsobem možné provést nezávislý převod z liber na čtvereční palec na bar (100 kPa) nebo MPa. Pro nezávislý výpočet toho přesného budete muset vědět, že 1 PSI \u003d 6894,76 Pa. Všechny výpočty tlaku ANSI v barech a Pascalech lze provádět, když je čas a potřeba přesných údajů, zároveň většina standardních hodnot tlakové třídy ANSI již má standardní hodnoty v barech a MPa. Pro zjednodušení jsme pro vás sestavili krátkou tabulku:
Tabulka tlakových tříd ANSI s přepočtem na Bar a MPa
|
ANSI tlaková třída |
||
Někdy vám ani poměrně zkušený specialista hned neřekne, jaká konkrétní hodnota tlaku nebo délky v jednom systému odpovídá hodnotám v jiném systému veličin.
Na zmírnit vám tento úkol, nabízíme tabulky vztahu mezi tlakem a délkou v evropských a amerických systémech s malými vysvětlení. Nejprve však pár slov o samotných standardech.
RÁMUS je německý standard (zkratka pro Deutsches Institut für Normung, tedy vyvinutý Německým institutem pro normalizaci), který je vyvíjen striktně v rámci ustanovení Mezinárodní organizace pro normalizaci - ISO (International Organization for Standardization).
ANSI je standard přijatý ve Spojených státech amerických. znamená Americký národní normalizační institut, což je standard American National Standards Institute.
V souladu s tím jsou standardy ANSI určeny právě touto institucí a daleko ne vždy mezi standardy RÁMUS a ANSI lze přesně dohledat dodržování v různých oborech.
Převod jednotek tlaku z ANSI na DIN
Všechno je zde jednoduché: pokud podle normy ANSI naproti tlaku je číslo 150 - to znamená, že jmenovitý (pro který je ventil určen) tlak je 20 bar, 300 - 50 bar atd. Maximální hodnota pro třída ANSI– 2500 se bude rovnat 420 barům podle evropské normy RÁMUS.
Pomocí této tabulky, není těžký převést hodnoty tlaku a naopak: od RÁMUS v ANSI, ačkoli naši inženýři potřebují mnohem více méně často.
Převod jednotek délky z amerického systému na evropský (ruský)
jak je známo, Američané vše se měří v palcích a stopách a my Evropané- milimetry, centimetry a metry, tedy jako naprostá většina zemí světa žijeme v metrický soustava jednotek.
Jak převést palce na milimetry? Ve skutečnosti na tom také není nic složitého, jen nezapomeňte, že 1 palec se rovná 25,4 mm. Často však číslice za desetinnou čárkou zanedbání a pro jistotu to uveďte 1 palec = 25 mm.
Je-li tedy např. průřez vtoku 2 palce podle amerického systému měr, pak převodem této hodnoty do našeho systému měr podle výše uvedeného pravidla dostaneme 50 mm, resp. 51 mm (zaokrouhlení 50,8 dle pravidel) .
Zbývá dodat, že průměr in technický vlastnosti jsou označeny latinkou DN a je často indikován v palce, a tlak je označen písmeny PN a je nejčastěji indikován v bary- každopádně přesně toto značení používáme nejvíce komfortní.
A následující tabulka pomůže nejen počítáte přesný počet milimetrů v jednom palci (s přesností na tisícinu milimetru), ale také vám pomůže zjistit, kolik milimetrů obsahuje například 2,5 palce.
Za tímto účelem najdeme sloupec 2 "" (2 palce) a vlevo hledáme hodnotu 1/2. Celkem 2,5 palce = 63,501 mm, které lze zaokrouhlit až na 64 mm, a například 6,25 palce (tj. 6 a 1/4) = 158,753 mm nebo 159 mm.
|
| Palce "" až milimetry |
|||||||
|
| ||||||||
|
| ||||||||
Reg.ru: domény a hosting
Největší registrátor a poskytovatel hostingu v Rusku.
V provozu je více než 2 miliony doménových jmen.
Propagace, mail pro doménu, řešení pro podnikání.
Již si vybralo více než 700 tisíc zákazníků po celém světě.
*Přejetím myší pozastavíte rolování.
Zpět dopředu
Kódování: užitečné informace a krátká retrospektiva
Tento článek jsem se rozhodl napsat jako malou recenzi na problematiku kódování.
Pochopíme, co je kódování obecně, a trochu se dotkneme historie toho, jak se v zásadě objevily.
Promluvíme si o některých jejich vlastnostech a také zvážíme body, které nám umožňují pracovat s kódováním vědoměji a vyhnout se tzv. Krakozyabrov, tj. nečitelné znaky.
Tak pojďme...
Co je to kódování?
Jednoduše řečeno, kódování je tabulka mapování znaků, které můžeme vidět na obrazovce, na určité číselné kódy.
Tito. každý znak, který zadáme z klávesnice nebo vidíme na obrazovce monitoru, je zakódován určitou posloupností bitů (nul a jedniček). 8 bitů, jak pravděpodobně víte, se rovná 1 bajtu informace, ale o tom později.
Vzhled samotných znaků je určen soubory písem které jsou nainstalovány na vašem počítači. Proto lze proces zobrazování textu na obrazovce popsat jako neustálé mapování sekvencí nul a jedniček na nějaké specifické znaky, které jsou součástí písma.
Lze považovat za předchůdce všech moderních kódování ASCII.
Tato zkratka znamená Americký standardní kód pro výměnu informací(Americká standardní tabulka kódování pro tisknutelné znaky a některé speciální kódy).
to jednobajtové kódování, který původně obsahoval pouze 128 znaků: písmena latinské abecedy, arabské číslice atd.

Později byl rozšířen (zpočátku nepoužíval všech 8 bitů), takže bylo možné použít ne 128, ale 256 (2 až 8) různých znaků, které lze zakódovat do jednoho bajtu informace.
Toto vylepšení umožnilo přidat do ASCII symboly národních jazyků, navíc k již existující latinské abecedě.
Existuje mnoho možností pro rozšířené kódování ASCII, protože na světě existuje také mnoho jazyků. Myslím, že mnozí z vás slyšeli o takovém kódování jako KOI8-R je také rozšířené kódování ASCII, navržený pro práci s ruskými znaky.
Za další krok ve vývoji kódování lze považovat vzhled tzv ANSI kódování.
V podstatě byly stejné rozšířené verze ASCII, byly z nich však odstraněny různé pseudografické prvky a přidány typografické symboly, pro které dříve nebylo dostatek „volných míst“.
Příkladem takového kódování ANSI je dobře známý Windows-1251. Kromě typografických symbolů toto kódování zahrnovalo také písmena abeced jazyků blízkých ruštině (ukrajinský, běloruský, srbský, makedonský a bulharský).
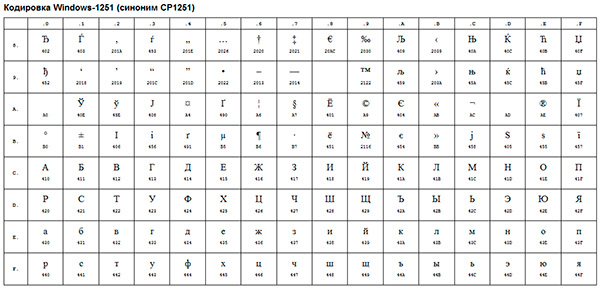
Kódování ANSI je souhrnný název pro. Ve skutečnosti bude skutečné kódování při použití ANSI určeno tím, co je uvedeno v registru vašeho operační systém Okna. V případě ruštiny to bude Windows-1251, ale pro ostatní jazyky to bude jiný druh ANSI.
Jak jste pochopili, spousta kódování a nedostatek jediného standardu nepřinesly dobro, což byl důvod častých setkání s tzv. krakozyabry- nečitelný nesmyslný soubor znaků.
Důvod jejich vzhledu je jednoduchý - je pokusit se zobrazit znaky zakódované jednou kódovací tabulkou pomocí jiné kódovací tabulky.
V souvislosti s vývojem webu se můžeme setkat s chybami, když např. Ruský text je omylem uložen ve špatném kódování používaném na serveru.
Samozřejmě to není jediný případ, kdy se nám může dostat nečitelný text – možností je zde spousta, zvláště když uvážíte, že existuje i databáze, ve které jsou informace také uloženy v určitém kódování, existuje zde databázové spojení mapování atd.
Vznik všech těchto problémů posloužil jako podnět k vytvoření něčeho nového. Mělo to být kódování, které dokáže zakódovat jakýkoli jazyk na světě (ostatně s pomocí jednobajtových kódování, se vší touhou, je nemožné popsat všechny znaky, řekněme, čínština, kde je zřetelně více než 256), jakékoli další speciální znaky a typografii.
Jedním slovem bylo potřeba tvořit univerzální kódování, které by problém s chybami vyřešilo jednou provždy.
Unicode – univerzální kódování textu (UTF-32, UTF-16 a UTF-8)
Samotný standard byl navržen v roce 1991 neziskovou organizací "Unicode Consortium"(Unicode Consortium, Unicode Inc.), a prvním výsledkem jeho práce bylo vytvoření kódovacího UTF-32.
Mimochodem ta zkratka UTF znamená Transformační formát Unicode(Formát konverze Unicode).
V tomto kódování se pro zakódování jednoho znaku mělo použít tolik jako 32 bitů, tj. 4 bajty informací. Pokud toto číslo porovnáme s jednobajtovými kódováními, pak dojdeme k jednoduchému závěru: pro zakódování 1 znaku v tomto univerzálním kódování potřebujete 4krát více bitů, který soubor 4x „zváží“.
Je také zřejmé, že počet znaků, které by mohly být potenciálně popsány pomocí tohoto kódování, překračuje všechny rozumné meze a je technicky omezen na počet rovný 2 až 32. Je jasné, že se jednalo o jasnou přehnanost a plýtvání z hlediska hmotnosti souborů, takže toto kódování nebylo příliš využíváno.
Byl nahrazen novým vývojem - UTF-16.
Jak název napovídá, v tomto kódování je zakódován jeden znak již ne 32 bitů, ale pouze 16(tj. 2 bajty). Je zřejmé, že díky tomu je jakýkoli znak dvakrát „lehčí“ než v UTF-32, ale také dvakrát „těžší“ než jakýkoli znak kódovaný pomocí jednobajtového kódování.
Počet znaků dostupných pro kódování v UTF-16 je minimálně 2 až 16, tzn. 65536 znaků. Vše se zdá být v pořádku, kromě toho byla konečná hodnota kódového prostoru v UTF-16 rozšířena na více než 1 milion znaků.
Toto kódování však plně neuspokojovalo potřeby vývojářů. Řekněme, že pokud píšete výhradně znaky latinky, pak po přechodu z rozšířené verze kódování ASCII na UTF-16 se váha každého souboru zdvojnásobí.
Jako výsledek, byl učiněn další pokus vytvořit něco univerzálního a toto něco se stalo známým kódováním UTF-8.
UTF-8- tohle je vícebajtové kódování znaků s proměnnou délkou znaků. Při pohledu na název byste si mohli myslet, analogicky s UTF-32 a UTF-16, že pro kódování jednoho znaku se používá 8 bitů, ale není tomu tak. Přesněji řečeno ne tak docela.
Je to proto, že UTF-8 poskytuje nejlepší kompatibilitu se staršími systémy, které používaly 8bitové znaky. Ve skutečnosti se používá ke kódování jednoho znaku v UTF-8 1 až 4 bajty(hypoteticky možné až 6 bajtů).
V UTF-8 jsou všechny znaky latinky kódovány 8 bity, stejně jako v kódování ASCII.. Jinými slovy, základní část kódování ASCII (128 znaků) se přesunula do UTF-8, což umožňuje „utratit“ pouze 1 bajt na jejich reprezentaci při zachování univerzálnosti kódování, pro které bylo vše spouštěno.
Pokud je tedy prvních 128 znaků zakódováno 1 bajtem, pak všechny ostatní znaky jsou již zakódovány 2 bajty nebo více. Zejména každý znak azbuky je zakódován přesně 2 bajty.
Dostali jsme tak univerzální kódování, které nám umožňuje pokrýt všechny možné znaky, které je potřeba zobrazit bez „těžších“ souborů zbytečně.
S kusovníkem nebo bez kusovníku?
Pokud jste pracovali s textové editory(například pomocí editorů kódu). Poznámkový blok++, phpDesigner, rychlé PHP atd., pak asi dbali na to, že při nastavování kódování, ve kterém bude stránka vytvořena, lze obvykle zvolit 3 možnosti:
ANSI
-UTF-8
- UTF-8 bez kusovníku


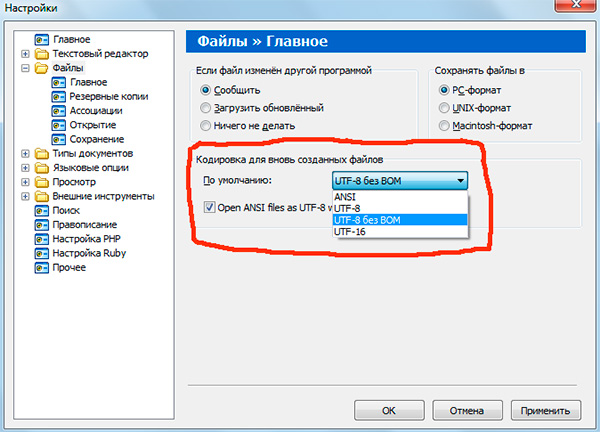
Hned řeknu, že se vždy vyplatí vybírat poslední možnost - UTF-8 bez kusovníku.
Co je tedy kusovník a proč ho nepotřebujeme?
kusovník znamená Značka pořadí bajtů. Toto je speciální znak Unicode používaný k označení endianness. textový soubor. Jeho použití je dle specifikace volitelné, ale pokud kusovník se používá, musí být nastaven na začátek textového souboru.
Nebudeme zabíhat do detailů práce kusovník. Pro nás je hlavní závěr následující: použití tohoto servisního znaku spolu s UTF-8 zabrání programům v normálním čtení kódování, což má za následek chyby ve skriptu.
ANSI je standard pro zobrazování znaků vyvinutý americkým národním institutem pro standardy (kód 1251). Standard ANSI používá k reprezentaci každého znaku pouze jeden bajt, a je proto omezen na maximálně 256 znaků včetně interpunkce. Kódy 32 až 126 se řídí standardem ASCII. V DOSu bylo použito ASCII (kód 688), ve Windows se používá ANSI.
Literatura
Archangelsky A.Ya. Programování v C++ Builder6. Ed. BINOM, 2004.
Archangelsky A.Ya. C++ Builder6. Referenční příručka. Moskva, Ed. BINOM, 2004.
Kimmel P. Borland C++5 "BHV-St. Petersburg, 2001.
Klímová L.M. C++ Praktické programování. Řešení typických úloh. "KUDITS-IMAGE", M.2001.
Kultin N. С/С++ v úlohách a příkladech. Petrohrad "BHV-Petersburg", 2003.
Pavlovská T.A. C/C++ Programování v jazyce vysoké úrovně. Petr, Moskva – Petrohrad –… 2005
Pavlovskaya T.A., Shchupak Yu.A. C++. Objektově orientované programování. Dílna. SPb., Peter, 2005.
Podbelský V.V. Jazyk C++ Finance a statistika, Moskva, 2003.
Polyakov A.Yu., Brusentsev V.A. Metody a algoritmy počítačová grafika v příkladech ve Visual C++. SPb BHI-Petersburg, 2003
Savitch W. Kurz objektově orientovaného programování v jazyce C++. Nakladatelství Williams. Moskva-Petrohrad-Kyjev, 2001
Wellin S. Jak neprogramovat v C++. "Petr". Moskva – Petrohrad – Nižnij Novgorod – Voroněž – Novosibirsk – Rostov – Don – Jekatěrinburg – Samara – Kyjev – Charkov – Minsk, 2004.
Shieldt G. Kompletní reference v C++. Ed. Dům "Williams" Moskva-Petrohrad-Kyjev, 2003.
Schildt G. Samoučitel C/C++. Petrohrad, BHV-Petersburg, 2004.
Schildt G. Programmer's Guide to C/C++ Ed. Dům "Williams" Moskva-Petrohrad-Kyjev, 2003.
Shimanovich.L. С/С++ v příkladech a úlohách. Minsk, Nové poznatky, 2004.
Stern V. Základy C++. Metody softwarového inženýrství. Ed. Lori.
Proč se v konzolové aplikaci zobrazuje odpad místo ruských písmen?
a správně! Text programu, který jste zadali ve svém nativním editoru vizuální studio, pomocí kódové stránky 1251 a textový výstup v konzolové aplikaci používá kódovou stránku 866. Co dělat s touto ostudou? Jak víte, z každé patové situace existují alespoň 3 východy. Zvažme je v pořadí.
Výjezd 1
Zadejte text programu do editoru libovolného správce souborů konzoly.
Ale co zvýraznění syntaxe, zobrazení nápovědy k vybrané funkci pomocí F1 a další malé kouzla, které rozjasní bezútěšný život jednoduchého programátora? Ne, tato možnost pro nás není.
výstup 2
Pokud jste začali psát konzolový program od nuly, může vám vyhovovat. Pojďme přepsat naše malé mistrovské dílo takto:
|
#include "stdafx.h" #include "windows.h" int main(int argc, char* argv) char s="Ahoj všichni!"; printf("%s\n", s); |
Klíčové slovo je zde CharToOem – právě tato funkce převede náš řetězec na požadovanou kódovou stránku. S výstupem našeho programu je nyní vše v pořádku.
Nabízí se ale další otázka – co dělat, když potřebujete svůj starý 100 000řádkový DOSový program napsaný v Borland C++ 3.1 překompilovat do konzolové aplikace Windows, ve které se taková situace vyskytuje na každém druhém řádku. Ale stále to musíte upravit na kompilátor MS a také chcete optimalizovat několik kusů kódu ...
Tady asi má smysl použít tah rytíře, ve smyslu