…Přestože je syntaxe HTML relativně jednoduchá na naučení,…je zde stále mnoho prvků, atributů a…dalších pojmů, které se budete muset naučit a sledovat.…Přestože tento kurz má za cíl představit abyste se seznámili se základy HTML, je to...opravdu není navrženo tak, aby vás naučilo každý jednotlivý dostupný prvek a atribut....Takže s ohledem na to vám chci poskytnout několik online zdrojů HTML,...které vám mohou začnete se učit HTML a...může vám později posloužit jako cenné reference, když budete vytvářet své vlastní stránky....Nyní začneme u samotných specifikací....
A tohle je něco, dva dokumenty, které byste si rozhodně měli dát do záložek.…Takže toto je verze HTML5 W3Cs.…Můžete vidět, že mají nejnovější verzi vydavatele.…Můžete se podívat na koncept editora,…pokud chci vidět, co jde dolů, potrubím....A tohle je docela velké....Když se posunu dolů, můžeš vidět, že tady je "jen obsah....a já je ani nebudu procházet všechny."...
Obnovit automatické posouvání přepisu
Aktualizováno
3/30/2017Vydáno
3/16/2015HTML je programovací jazyk, který pohání web. A jako každý jazyk, jakmile si ho osvojíte, můžete začít vytvářet svůj vlastní obsah, ať už jde o jednoduché webové stránky nebo složité webové aplikace. Tento kurz poskytuje hloubkový pohled na základy: syntaxi HTML a osvědčené postupy pro Autor vedoucího týmu James Williamson si prohlédne strukturu typického dokumentu HTML a ukáže, jak rozdělovat stránky a formátovat obsah pomocí HTML.Plus, naučit se vytvářet odkazy a seznamy a zjistit, jak HTML spolupracuje s CSS a JavaScript při vytváření , poutavé uživatelské zkušenosti.
Mezi témata patří:
- Proč je HTML důležité?
- Prozkoumání dokumentu HTML
- Formátování obsahu
- Zobrazte obrázky
- Použití prvků nav, article a div
- Odkazování na stránky a obsah ke stažení
- Vytváření seznamů
- Ovládání stylů (fonty, barvy a další)
- Psaní základních skriptů
: Vždy jsem to chtěl pochopit, ale jeho význam byl tak malý, že se vždy našel důvod to neudělat :)
A zajímalo tě: URL - co to je?
Na tohle narážím vždycky, ale pořád jsem nechtěl chápat rozdíl mezi pojmy URI, URL, URN a pak najednou příspěvek (bohužel už upadl v zapomnění), rozhodl jsem se - přečtu si to a řekněte to ostatním, i když, jak je uvedeno výše, na tom se nic nezmění, ale já někdy rád pravopis, takže si přečtěte rozumného překladatele:
Věnovali jste někdy pozornost adresnímu řádku v prohlížeči? co je to? URI, URL nebo URN? Mnoho z nás nerozlišuje mezi URI, URL, URN a někteří o pojmech URI a URN nikdy ani neslyšeli, všichni jen používají termín URL. Zkusme na to společně přijít.
Vysvětlení zkratek
URI - Uniform Resource Identifier (uniform identifikátor zdroj)
URL – Uniform Resource Locator (sjednocený vyhledávač polohy zdroj)
URN – Uniform Resource Name (uniform název zdroj)
Pozor, tady je pravda v maličkostech, ale zatím není nic jasné, nějaký nepořádek. Pojďme dále.
Definice
URI: Označuje název a adresu zdroje na webu. Obecně se dělí na URL a URN, takže URL a URN jsou součástí URI.
URL: Adresa nějakého zdroje na webu. Adresa URL definuje umístění zdroje a způsob přístupu k němu.
URN: Název nějakého zdroje na webu. Smyslem URN je, že definuje pouze název konkrétní položky, kterou lze nalézt na více konkrétních místech.
Není nic lepšího než konkrétní příklad
URI = http://site/2009/09/uri-url-urn.html
URL = http://stránka
URL=/2009/09/uri-url-urn.html
Shrnutí
URI je koncept abstraktního identifikátoru, zatímco URL a URN jsou konkrétní implementace adres a jmen.
Doufám, že je všem jasné. Buď chytrý!
Vnímání každého z nás je individuální, proto - argumentujte a čtěte diskuze v komentářích k článku, je tam spousta zajímavých věcí.
Mnoho webmasterů zpravidla nahrává své stránky na hostitele ihned po jejich vytvoření. Většinou se přitom soustředí spíše na správnost smyslu obsahu textu než na správnost vnitřního kódu stránek.
Ověření webu
Existují ale další faktory, které mohou ovlivnit a ovlivňují pozici webu. A zahrnují mimo jiné i technické faktory. No a k těm technickým patří i validace webu. Tak co to je?
Pokud jednoduše řečeno, pak ověření webu je kontrola kódu webu z hlediska technické shody a chyb. No, například jste zapomněli použít uzavírací značku - /html. V nejnovějším HTML5 se vizuálně nic nezmění. Jedná se však o chybu kódu.
Při psaní kódu jsou možné další chyby. A opět, moderní hyper-značkovací jazyk vydrží hodně. Například "zapomenutí" uzavírací značky /head. Opět neuvidíte rozdíl. Ale ona je))
Ve skutečnosti se při psaní webu může vyskytnout poměrně hodně chyb. A co je horší, některé z těchto chyb se mohou projevit i vizuálně. No, možná budou bloky plavat, možná zarovnání, nebo možná něco jiného. Potenciální chyby, tisíce. A ne všechny jsou nápadné.
jaké je nebezpečí?
No, zdálo by se, no, co je na tom špatného? Ano, nutno říci, že často takové chyby nejsou vidět. Nebo spíše pro lidi neviditelné. Stránky našeho webu však mohou navštívit nejen lidé, ale také vyhledávací pavouci, kteří web kompletně prohledají. A každou chybu, kterou na webu najdou, přenášejí na servery vyhledávačů, jako je Yandex nebo Google.
A vyhledávače, když vidí, že stránka obsahuje mnoho chyb v kódu, mohou snadno dojít k závěru, že stránka je špatná. A to znamená, že to při hledání nezvednou. No, to už bude znamenat, že sbohem návštěvníkům z hledání.
Ano, nutno přiznat, že určitá pesimizace webu kvůli chybám ve validaci je poměrně vzácná. Ale to je docela možné, což znamená, že se musí pracovat na validaci. A co je pro to potřeba udělat? Samozřejmě prvním krokem je najít chyby.
Ale protože ručně je to velmi časově náročné a nespolehlivé podnikání, pak k hledání chyb používají speciální služby, tzv. „Validátory“.
Validator Markup Validation Service.
Tato služba kontroluje správnost HTML a XHTML kódů, které jsou základem většiny stránek při tvorbě téměř jakéhokoli webu, a určuje jeho vnitřní strukturu. Tato služba validátoru je přístupná kliknutím na odkaz http://validator.w3.org
Je zde ale předpoklad, který platí i pro ostatní validátory: kontrolovaný web nebo jeho kontrolované stránky musí být nahrány na hosting. V opačném případě validátor „nezná“ adresu webu a nebude moci nic zkontrolovat. Nyní již můžete zvážit, jak na tomto validátoru pracovat.
Po vstupu na stránku této služby se zobrazí její celý funkční obrázek. Ale většina toho, co je zobrazeno a napsáno, se nevztahuje na hlavní kontrolu a veškerou svou pozornost byste měli věnovat pouze vstupnímu oknu pro adresu kontrolované stránky:
To je přesně místo, kde musíte začít.
Kontrola validace webu je ve skutečnosti velmi jednoduchá, stejně jako celý náš smrtelný svět: do adresního okna služby musíte napsat adresu webu, tzn. jeho URL a poté klikněte na „Zkontrolovat“. Po takové jednoduché akci validátor na několik sekund „bafne“ a vydá následující:
To znamená, že v kódu stránky nejsou žádné chyby a můžete být naprosto v klidu.
Ale může existovat i taková nežádoucí možnost:

To už je horší a znamená to, že v interním kódu kontrolované stránky jsou nějaké chyby. To však není vůbec fatální: stačí posouvat stránku níže a všechny chyby nalezené během procesu ověřování se tam podrobně zapíší.

Validátor navíc nejen vypíše nalezené chyby, ale také přesně ukáže, na kterém řádku interního kódu se tyto chyby nacházejí. Nebudete je tedy muset dlouho hledat. Zde můžeme bez přehánění s jistotou říci, že tento validor funguje perfektně.
Ale to není vše: validátor nejen indikuje umístění detekované chyby kódu, ale také dává poměrně kompletní doporučení, jak tyto chyby odstranit. K tomu samozřejmě nemusíte být líní a pečlivě si přečíst vše napsané.
Jako krátký a obecný závěr můžeme říci následující:
- tato služba validátoru funguje skvěle a dokáže stránky zkontrolovat velmi rychle.
- No, malý, ale velmi pěkný dodatek: ověření stránek je zdarma.
- Nyní můžeme přejít k dalšímu kroku: tím je kontrola kódu CSS.
Ověřovací služba CSS
Obecně se jedná o druhou funkci výše uvedené služby, která je však „vybroušena“ nikoli pro kontrolu HTML a XHTML kódu, ale konkrétně pro kontrolu správnosti kódu styl css umístěné na vnějším stole. A abyste se dostali na stránku služby, musíte kliknout na odkaz http://jigsaw.w3.org/css-validator .
Mimochodem, zde stojí za zmínku něco příjemného: kontrola této služby je zcela zdarma. Nevytahujte tedy peníze z peněženky – nechte je ležet do správné chvíle. Přejděme však k metodice práce na této druhé službě.
Obecně je veškerá práce na CSS validátoru naprosto totožná s kontrolou čistoty kódu. Proto není nutné poskytovat samostatný obrázek adresního řádku validátoru. Jen o něco níže krátce zvážíme pořadí samotné kontroly a je to.
K tomu potřebujete adresní řádek zapište si URL tabulky CSS, např. „http://my site/style.css“ a poté klikněte na tlačítko s ruským nápisem „Check“. V souladu s tím tento validátor také na několik sekund „nafoukne“ a poskytne požadovaný výsledek:
To znamená, že CSS tabulka je zapsána správně a nebyly v ní nalezeny žádné chyby.
A zde je také příjemné překvapení: pokud stránku posunete o něco níže, zapíše se tam optimalizovaný kód pro vaši CSS tabulku, ze které budou odstraněny všechny nepotřebné nápisy a všechny kódové značky budou uspořádány v pořadí který splňuje optimální pracovní požadavky všech vyhledávače. Zbývá pouze zkopírovat tento dokonalý vzorek kódu a vložit jej do tabulky CSS.
Je docela možné, že se něco takového může stát:

To znamená, že v kódu CSS byly nalezeny nějaké chyby, ale toho se vůbec nemusíte bát. Těsně pod touto červenou čarou vám validátor přesně řekne, která značka je špatně napsaná. Zbývá pouze najít tyto značky v šabloně stylů a provést potřebné opravy.

A samozřejmě poté nahrajte opravenou šablonu stylů na hostitele a pokud je tam zelená čára, můžete vesele zkopírovat optimalizovaný kód stylu tabulky CSS. Je celkem jasné, že pak je nejlepší se změnit starý kód na nový a optimalizovaný.
Stručné shrnutí.
Dvě nejzákladnější a povinné kontroly ověření webových stránek byly diskutovány výše. Bez těchto kontrol byste ani neměli otevírat indexování pro vyhledávače v souboru robots.txt, jinak může být web pro indexování ignorován vyhledávače a budou považovány za vadné s příslušnými sankcemi.
Abyste tomu zabránili, musíte věnovat jen pár minut tomu, abyste byli absolutně klidní a zcela si jistí technickým stavem vašeho webu a všech jeho stránek. Samozřejmostí jsou také dodatečné kontroly odkazů a kotev, viditelnosti stránek na mobilních zařízeních a parametrů dalších kódů. Jedině tak lze web považovat za připravený pro své plné fungování a pro úspěšné a rychlá propagace v TOP.
Předem bych chtěl říci, že všechny ostatní kontroly jsou stejně rychlé a jednoduché jako ty, které byly diskutovány výše – stačí si pozorně přečíst postup práce s validátorem.
Přidáno 19.04.2018
Běžné chyby platnosti při ověřování HTML kódu
Rozhodl se článek aktualizovat. chyby HTML kódy, které se často nacházejí na stránkách. V každém případě jsem jich měl hodně)). Validátor zvýrazní chyby žlutě.
1) Chyba: Odkaz na znak nebyl ukončen středníkem.

Chyba: znak nebyl přerušen středníkem - podle toho se musí přidat.
2) Upozornění: Sekce nemá nadpis. Zvažte použití prvků h2-h6 k přidání identifikačních nadpisů do všech sekcí.
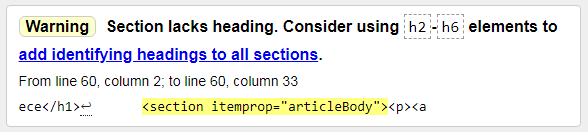
Upozornění: Tato sekce nemá žádný název. Zvažte použití prvků h2-h6 k přidání identifikačních nadpisů do všech sekcí. Zde je vše jasné, je potřeba přidat alespoň jeden podtitul. To ani není chyba, ale doporučení.
3) Chyba: Prvek noindex není v tomto kontextu povolen jako potomek prvku p.
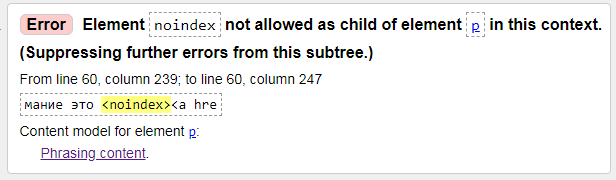
Chyba: prvek noindex není povolen jako podřízený prvek p prvek v tomto kontextu. (Potlačit další chyby z tohoto podstromu.)
Řešení je jednoduché, musíte zakomentovat značku noindex, pohled bude vypadat takto:
4) Chyba: Středový prvek je zastaralý.
Chyba: značka "center" je zastaralá - musí být nahrazena, pokud mluvíme o img, můžete použít atribut align. Pokud je vycentrováno něco jiného, nahraďte to div.
5) Prvek img musí mít atribut alt, kromě určitých

Chyba: Element img musí mít atribut alt – zde je vše jasné, je třeba přidat atribut alt, i když je prázdný, chyba zmizí.
6) Atribut width na prvku td je zastaralý. Místo toho použijte CSS.
Chyba: Atribut 'width' prvku 'td' je zastaralý

7) Atribut type je pro zdroje javascriptu zbytečný

Chyba: Atribut type není potřeba pro zdroje javascriptu. Řešením je jednoduše odstranit vše nepotřebné a ponechat pouze značku „script“.
8) Atribut align na prvku img je zastaralý.

Chyba: Atribut align na prvku img je zastaralý. Proveďte zarovnání obrazu div.
Třída ResourceBundle.Control má sadu externích metod, které jsou volány metodou ResourceBundle.getBundle() při vyhledávání a načítání balíčků. Jakmile vytvoříte třídu Control, můžete změnit výchozí chování načítání a ukládání do mezipaměti.
V tomto případě musíte vytvořit implementaci dvou metod třídy Control: getFormats() a newBundle() . Za údržbu je zodpovědná metoda getFormats(). XML formát a newBundle() funguje na svazku zdrojů. Základní třída Control má pomocné metody pro převod názvů základních sad na skutečné názvy zdrojů.
Tato implementace třídy ResourceBundle.Control zahrnuje podtřídu XMLResourceBundle . Tato podtřída se používá k načítání dat XML soubor a jejich použití v metodě ResourceBundle.
Následuje popis třídy Control a implementace metody ResourceBundle:
import java.io.*;
import java.net.*;
import java.util.*;
Veřejná třída XMLResourceBundleControl rozšiřuje ResourceBundle.Control(
private static String XML = "xml" ;
Veřejný seznam getFormats(String baseName ) (
return Collections.singletonList(XML) ;
}
Public ResourceBundle newBundle( Řetězec baseName, národní prostředí,
Formát řetězce, zavaděč ClassLoader, booleovské opětovné načtení)
hází IllegalAccessException, InstantiationException, IOException{
if ((baseName == null ) || (locale == null ) || (format == null )
|| (loader == null )) (
throw new NullPointerException();
}
ResourceBundle bundle = null ;
if (format.equals(XML))(
Řetězec bundleName = toBundleName(baseName, locale ) ;
Řetězec resourceName = toResourceName(název balíčku, formát ) ;
url= loader.getResource(název zdroje) ;
if (url != null ) (
Připojení URLConnection = url.openConnection()
;
if (spojení != null ) (
if (znovu načíst) (
connection.setUseCaches(false) ;
}
InputStream stream = connection.getInputStream()
;
if (stream != null ) (
BufferedInputStream bis = nový BufferedInputStream (
proud);
bundle = new XMLResourceBundle(bis) ;
bis.close();
}
}
}
}
vrátit svazek;
}
Soukromá statická třída XMLResourceBundle rozšiřuje ResourceBundle(
rekvizity soukromých nemovitostí;
XMLResourceBundle(InputStream stream) vyvolá IOException(
rekvizity = new Properties();
props.loadFromXML(stream) ;
}
Handle pro chráněný objektGetObject (klíč řetězce) (
return props.getProperty(key) ;
}
Veřejný výčet getKeys()(
Nastavte handleKeys = props.stringPropertyNames()
;
return Collections.enumeration (handleKeys);
}
}
Public static void main(String args) (
("Test2",
nový XMLResourceBundleControl()) ;
tětiva= bundle.getString("HelpKey");
System.out.println ("HelpKey: " + řetězec ) ;
}
}
Tato implementace zahrnuje třířádkový testovací program:
ResourceBundle bundle = ResourceBundle.getBundle("Test2", nový XMLResourceBundleControl()) ;
String string = bundle.getString("HelpKey");
System.out.println ("HelpKey: " + řetězec ) ;
Nejzajímavější je zde první řádek. Musíte předat své ovládání metodě getBundle(). Poté můžete sadu používat jako v každém jiném případě.
Níže je uveden příklad souboru XML Test2.xml:
http://java.sun.com/dtd/properties.dtd"
>
Výsledkem spuštění programu XMLResourceBundleControl bude:
> java XMLResourceBundleControl HelpKey: Help
Výše uvedená implementace nepoužívá metody getTimeToLive() a needsReload():
veřejné dlouhé getTimeToLive( Řetězec baseName, Locale locale)
public boolean needsReload( Řetězec baseName,
národní prostředí,
formát řetězce,
nakladač třídy,
balíček zdrojů,
dlouhá doba načítání)
Metoda getTimeToLive() vrací životnost pro balíčky prostředků vytvořené pomocí ResourceBundle.Control . Sady prostředků se ukládají do mezipaměti, aby se urychlil proces opětovného načítání. Při opětovném načtení sady tedy bude v mezipaměti. Kladná hodnota doby životnosti nastaví v milisekundách, jak dlouho sada zůstane v mezipaměti bez opětovného ověření. Výchozí hodnota vrácená metodou getTimeToLive() je TTL_NO_EXPIRATION_CONTROL , která zakazuje kontrolu vypršení platnosti mezipaměti. Pokud sadu nechcete ukládat do mezipaměti, vraťte TTL_DONT_CACHE . Pokud je návratová hodnota 0, pak je svazek uložen do mezipaměti, ale je zkontrolován při každém volání metody getBundle(). Chcete-li vymazat mezipaměť, zavolejte statickou metodu clearCache() třídy ResourceBundle. Má volitelný argument ClassLoader, který vám umožňuje vymazat mezipaměti vytvořené konkrétním zavaděčem.
Metoda needsReload() určuje, zda je třeba znovu načíst sadu uloženou v mezipaměti. Hodnota true znamená, že sadu je třeba znovu načíst, a hodnota false znamená, že ji není třeba znovu načíst. Přetížením metody needsReload() můžete řídit, zda je třeba sadu prostředků znovu načíst. Pokud například chcete, aby byla sada prostředků vždy znovu načtena, metoda needsReload() by měla vždy vrátit true . V tomto případě musí metoda getTimeToLive() vždy vrátit hodnotu 0. Jinak bude sada přetrvávat déle, než se očekávalo.
Pro získání dodatečné informace Informace o vylepšeních procesů internacionalizace Mustangu najdete na Johnu Okonerovi, blogu Sun Software Developer na adrese