Ha az elmúlt néhány évben fejleszti a PHP-t, valószínűleg tisztában van ezzel a nyelvvel kapcsolatos problémákkal. Gyakran lehet hallani, hogy töredezett nyelvről van szó, hacker-eszközről, hogy nincs valódi specifikációja stb. A valóság az, hogy a PHP sokat fejlődött az utóbbi időben. A PHP 5.4-es verziója közelebb hozta a befejezéshez tárgymodellés sok új funkciót biztosított.
És ez mind jó, de mi a helyzet a keretekkel? PHP-ben nagyon sok van belőlük. Csak el kell kezdeni keresni, és meg fogod érteni, hogy nem lesz elég életed mindegyik tanulmányozására, mert folyamatosan új keretek jelennek meg, és mindegyikben feltalálnak valami sajátosat. Tehát hogyan lehet ezt olyasmivé alakítani, ami nem idegeníti el a fejlesztőket, és megkönnyíti a funkciók egyik keretrendszerről a másikra történő áthelyezését?
Mi az a PHPFIG
A PHP-FIG (PHP Framework Interop Group) fejlesztők szervezett csoportja, amelynek célja több keretrendszer együttműködésének módja.
Képzelje csak el: Ön jelenleg egy Zend Framework projektet támogat, amelyhez bevásárlókosár-modulra volt szüksége. Már írtál egy ilyen modult egy korábbi projekthez, amely a Symphony-n volt. Miért nem csinálod újra? Szerencsére a ZendF és a Symphony is a PHP-FIG része, így lehetséges a modulok importálása egyik keretrendszerből a másikba. Hát nem nagyszerű?
Nézzük meg, milyen keretrendszereket tartalmaz a PHP-FIG
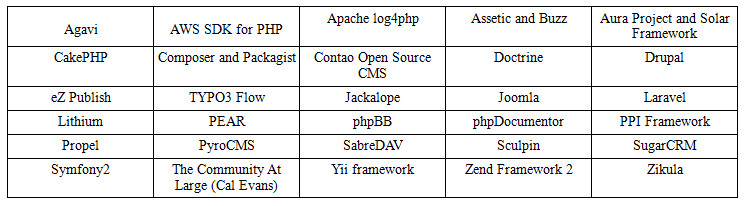
PHP-FIG tagok
Bármely fejlesztő felveheti a keretrendszerét a PHP-FIG közreműködőinek listájára. Ehhez azonban bizonyos összeget kell fizetnie, így ha nem kapja meg a közösség támogatását, akkor valószínűleg nem fog beleegyezni. Ez azért van így, hogy megakadályozzuk, hogy mikrokeretek milliói regisztráljanak minden jó hírnév nélkül.
Jelenlegi tagok:
Mi az a PSR?
PSR (PHP Standards Recommendations) - szabványos ajánlások, a PHP-FIG eredménye. A csoport egyes tagjai szabályokat javasolnak az egyes PSR-ekre, mások e szabályok mellett szavaznak vagy eltörlésük mellett. A beszélgetés a Google Csoportokon zajlik, a PSR-készletek pedig elérhetők a hivatalos PHP-FIG webhelyen.
Nézzünk néhány PSR-t:
Az első lépés a keretrendszerek egységesítése felé a közös címtárstruktúra, ezért egy közös automatikus betöltési szabványt fogadtak el.
- A névtérnek (névtérnek) és az osztálynak \\(\)* szerkezettel kell rendelkeznie.
- Minden névtérnek tartalmaznia kell egy legfelső szintű szóközt ("Szállító neve").
- Minden névtérnek tetszőleges számú szintje lehet.
- Minden névtér-elválasztó betöltéskor DIRECTORY_SEPARATOR-ra konvertálódik.
- A CLASS NAME minden egyes "_" karaktere DIRECTORY_SEPARATOR formátumba konvertálódik.
- A teljes képzésű névtér és osztály betöltéskor hozzáfűződik a ".php" karakterhez.
Példa az automatikus betöltés funkcióra:

PSR-1 – Alapvető kódolási szabvány
Ezek a PSR-ek szabályozzák az alapvető szabványokat, amelyek fő gondolata az, hogy ha minden fejlesztő ugyanazokat a szabványokat használja, akkor a kódportolás probléma nélkül elvégezhető.
- A fájlok csak címkéket használhatnak
- A fájlok csak UTF-8-at használhatnak BOM-kódolás nélkül.
- A helyneveknek és osztályoknak követniük kell a PSR-0-t.
- Az osztályneveket StudlyCaps jelöléssel kell megadni.
- Az osztályállandókat nagybetűvel kell megadni, aláhúzásjellel elválasztva.
- A módszereket camelCase jelöléssel kell megadni.
PSR-2 - Kódolási stílus útmutató
Ezek a PSR-1 kiterjesztett utasításai, amelyek leírják a kód formázási szabályait.
- A kódnak meg kell felelnie a PSR-1 szabványnak.
- Tabulátor helyett 4 szóközt kell használni.
- A karakterlánc hosszát nem szabad szigorúan korlátozni, az ajánlott hossza legfeljebb 80 karakter.
- A névtér-deklaráció után egy üres sornak kell lennie.
- Az osztályok zárójeleinek a deklaráció utáni következő sorban kell nyílniuk, és az osztálytörzs után be kell zárniuk (ugyanez a metódusoknál).
- Meg kell határozni a módszerek és tulajdonságok láthatóságát (nyilvános, privát).
- A vezérlőszerkezetek nyitókapcsainak ugyanazon a vonalon, a zárókonzoloknak a szerkezet törzse után következő sorban kell lenniük.
- Nincs szóköz a vezérlőszerkezeti módszerek nyitó zárójelei után és a zárójelek bezárása előtt.
PCR-3 - Logger interfész
A PCR-3 szabályozza a naplózást, különösen a kilenc fő módszert.
- A LoggerInterface 8 módszert kínál nyolc RFC 5424 szint naplózására (hibakeresés, értesítés, figyelmeztetés, hiba, kritikus, figyelmeztetés, vészhelyzet).
- A kilencedik log() metódus a figyelmeztetési szintet veszi fel első paramétereként. Egy metódus riasztási szint paraméterrel történő hívása ugyanazt az eredményt adja, mint egy adott naplószintű metódus meghívása (log(ALERT) == alert()). Egy meghatározatlan figyelmeztetési szinttel rendelkező metódus hívásakor Psr\Log\InvalidArgumentException kivételt kell adni.
A PSR-0-hoz hasonlóan a PSR-4 is továbbfejlesztett automatikus betöltési módszereket biztosít
- Az „osztály” kifejezés osztályokra, interfészekre, tulajdonságokra és más hasonló struktúrákra utal.
- A teljesen minősített osztálynévnek a következő alakja van: \
(\ )*\ - Ha olyan fájlt tölt be, amely megfelel egy teljesen minősített osztálynévnek:
- Egy vagy több vezető névtér összefüggő sorozata, a vezető névtérelválasztó kivételével, egy teljesen minősített osztálynévben legalább egy "gyökérkönyvtárral" egyezik.
- A könyvtárak és alkönyvtárak nevének meg kell egyeznie a névtér kis- és nagybetűivel.
- A teljes osztálynév vége megegyezik a .php végződésű fájlnévvel. A fájlnév kis- és nagybetűjének meg kell egyeznie a teljes osztálynév végződésének kis- és nagybetűjével.
- Az automatikus betöltő megvalósítás nem dobhat kivételeket, nem generálhat semmilyen szintű hibát, és nem adhat vissza értéket.
Következtetés
A PHP-FIG megváltoztatja a keretrendszerek írásmódját, de a működését nem. Az ügyfelek gyakran megkövetelik, hogy egy keretrendszeren belül meglévő kóddal dolgozzon, vagy adja meg, hogy melyik keretrendszerrel kell dolgoznia egy projekten. A PSR ajánlások nagyban megkönnyítik a fejlesztők életét ebben a tekintetben, ami nagyszerű!
PHP programozási nyelv hosszú utat tett meg a személyes oldalak létrehozására szolgáló eszköztől az általános célú nyelvvé. Ma több millió szerverre van telepítve szerte a világon, és fejlesztők milliói használják, akik sokféle projektet készítenek.
Könnyen megtanulható és rendkívül népszerű, különösen a kezdők körében. Ezért a nyelv fejlődése után a körülötte lévő közösség erőteljes fejlődése következett. Rengeteg szkript, minden alkalomra, különböző könyvtárakra, keretrendszerekre. Az egységes tervezési és kódolási szabványok hiánya az információs termékek hatalmas rétegének kialakulásához vezetett, amelyek a termék fejlesztőjének saját elvei alapján épültek fel. Ez különösen akkor volt észrevehető, amikor különféle eszközökkel dolgoztunk PHP keretrendszerek, amely sokáig zárt, más keretekkel nem kompatibilis ökoszisztémát képviselt, annak ellenére, hogy az általuk megoldott feladatok sokszor hasonlóak.
2009-ben több keretrendszer fejlesztői megállapodtak egy közösség létrehozásáról PHP Framework Interop Group (PHP-FIG), amely ajánlásokat dolgozna ki a fejlesztők számára. Fontos hangsúlyozni, hogy nem arról beszélünk ISO szabványok, helyesebb ajánlásokról beszélni. De mivel azok, akik alkottak php-fig A fejlesztők közössége nagy kereteket képvisel, ajánlásaik komoly súllyal bírnak. Támogatás PSR (PHP szabvány ajánlás) szabványok lehetővé teszi az interoperabilitást, ami megkönnyíti és felgyorsítja a végtermék fejlesztését.
Összességében ennek az írásnak a készítésekor 17 szabvány létezik, és ezek közül 9 jóváhagyott, 8 tervezeti szakaszban van, aktívan megvitatás alatt áll, 1 szabvány használata nem javasolt.
Most menjünk közvetlenül az egyes szabványok leírásához. Ne feledje, hogy itt nem fogok részletesen végigmenni az egyes szabványokon, inkább egy kis bevezető. Ezenkívül a cikk csak azokat veszi figyelembe PSR szabványok, amelyeket hivatalosan is elfogadnak, i.e. vannak Elfogadott állapotban.
PSR-1. Fő kódolási szabvány
A legáltalánosabb szabályokat képviseli, mint például a használat PHP címkék, fájlkódolás, egy függvény deklarálási helyének, osztályának és felhasználási helyének elkülönítése, osztályok, metódusok elnevezése.
PSR-2. Kódstílus útmutató
Ez az első szabvány folytatása, és szabályozza a tabulátorok használatát a kódban, a sortöréseket, a kódsorok maximális hosszát, a vezérlési struktúrák kialakításának szabályait stb.
PSR-3. Naplózási felület.
Ezt a szabványt úgy tervezték, hogy lehetővé tegye a beírt alkalmazásokba való bejelentkezést (naplózást). PHP.
PSR-4. Autoload Standard
Valószínűleg ez a legfontosabb és legszükségesebb szabvány, amelyről egy külön, részletes cikkben lesz szó. Osztályok, amelyek megvalósítják PSR-4, egyetlen automatikus betöltővel tölthető be, lehetővé téve az egyik keretrendszerből vagy könyvtárból származó alkatrészek és összetevők más projektekben történő felhasználását.
PSR-6. gyorsítótárazási felület
A gyorsítótárazás a rendszer teljesítményének javítására szolgál. És PSR-6 lehetővé teszi az adatok szabványos mentését és lekérését a gyorsítótárból, egységes felület segítségével.
PSR-7. HTTP üzenet interfész
Ha többé-kevésbé összetettet ír webhelyek PHP-ben, szinte mindig együtt kell dolgozni HTTP fejlécek. Természetesen, PHP nyelv kész lehetőségeket biztosít számunkra a velük való munkához, mint pl szuperglobális tömb $_SERVER, funkciók fejléc(), setcookie() stb., azonban manuális elemzésük tele van hibákkal, és nem mindig lehet figyelembe venni a velük való munka minden árnyalatát. És így, annak érdekében, hogy megkönnyítse a munkát a fejlesztő, valamint, hogy a felület interakció HTTP protokoll ezt a szabványt elfogadták. Erről a szabványról részletesebben a következő cikkek egyikében fogok beszélni.
PSR-11. Konténer felület
Íráskor PHP programok Gyakran harmadik féltől származó összetevőket kell használnia. És annak érdekében, hogy ne vesszen el a függőségek erdejében, a kódfüggőségek kezelésére különféle módszereket találtak ki, amelyek gyakran nem kompatibilisek egymással, és ez a szabvány közös nevezőhöz vezet.
PSR-13. Hipermédia linkek
Ez az interfész célja, hogy megkönnyítse az alkalmazásprogramozási felületek fejlesztését és használatát ( API).
PSR-14. Egyszerű gyorsítótárazási felület
Ez a szabvány folytatása és továbbfejlesztése PSR-6
Így ma mérlegeltük PSR szabványok. A szabványok állapotával kapcsolatos naprakész információkért forduljon a következőhöz
16.09.2016Próbáljuk meg meghatározni, hogyan javítható a php-fpm alapú alkalmazásszerver teljesítménye, valamint hozzunk létre egy ellenőrző listát a folyamat fpm konfigurációjának ellenőrzéséhez.
Először is érdemes meghatározni a pool konfigurációs fájl helyét. Ha a php-fpm-et a rendszertárból telepítette, akkor a készletkonfiguráció www az /etc/php5/fpm/pool.d/www.conf körül található. Ha saját buildet vagy más operációs rendszert (nem debian) használ, keresse meg a fájl helyét a dokumentációban, vagy adja meg manuálisan.
Próbáljuk meg részletesebben megvizsgálni a konfigurációt.
Váltás UNIX aljzatokra
Valószínűleg az első dolog, amire figyelni kell, az az, hogy az adatok hogyan jutnak el a webszervertől a php folyamatokhoz. Ez tükröződik a figyelési direktívában:
figyelj = 127.0.0.1:9000
Ha az address:port be van állítva, akkor az adatok átmennek a TCP veremen, és ez valószínűleg nem túl jó. Ha van elérési út a sockethez, például:
listen = /var/run/php5-fpm.sock
akkor az adatok a unix socketen mennek keresztül, és ezt a részt kihagyhatod.
Miért érdemes még mindig unix foglalatra váltani? Az UDS (unix domain socket) a TCP-veremen keresztüli kommunikációval ellentétben jelentős előnyökkel rendelkezik:
- nem igényel környezetkapcsolót, az UDS netisr-t használ)
- UDS datagram közvetlenül a cél socketbe írva
- egy UDS datagram küldése kevesebb műveletet igényel (nincs ellenőrző összeg, nincs TCP-fejléc, nincs útválasztás)
Átlagos TCP késleltetés: 6 us UDS Átlagos késleltetés: 2 us PIPE Átlagos késleltetés: 2 us TCP Átlagos áteresztőképesség: 253702 msg/s UDS Átlagos áteresztőképesség: 1733874 msg/s PIPE Átlagos áteresztőképesség: 1682796
Így az UDS késéssel rendelkezik ~66%-kal kevesebbés áteresztőképesség 7-szer több TCP. Ezért nagy valószínűséggel érdemes UDS-re váltani. Az én esetemben a socket a /var/run/php5-fpm.sock címen lesz.
; kommenteld - figyelj = 127.0.0.1:9000 listen = /var/run/php5-fpm.sock
Győződjön meg arról is, hogy a webszerver (vagy bármely más folyamat, amelynek kommunikálnia kell) rendelkezik olvasási/írási hozzáféréssel a sockethez. Erre vannak beállítások. figyelj.csoportés hallgatási mód A legegyszerűbb, ha mindkét folyamatot ugyanattól a felhasználótól vagy csoporttól futtatjuk, esetünkben a php-fpm és a webszerver a csoporttal indul. www-adatok:
listen.owner=www-data listen.group=www-data listen.mode=0660
A kiválasztott eseménykezelési mechanizmus ellenőrzése
Az I / O (bemenet-kimenet, fájl / eszköz / aljzat leírók) hatékony munkavégzéséhez érdemes ellenőrizni, hogy a beállítás helyes-e események.mechanizmus. Ha a php-fpm telepítve van a rendszertárból, akkor valószínűleg minden rendben van - vagy nincs megadva (automatikusan telepítve), vagy megfelelően van megadva.
Jelentése az operációs rendszertől függ, amelyre utalás található a dokumentációban:
; - epoll (linux >= 2.5.44) ; - kqueue (FreeBSD >= 4.1, OpenBSD >= 2.9, NetBSD >= 2.0) ; - /dev/poll (Solaris >= 7) ; - port (Solaris >= 10)
Például, ha egy modern linux disztribúción dolgozunk, szükségünk van az epoolra:
események.mechanizmus = epoll
Medencetípus kiválasztása - dinamikus / statikus / igény szerinti
Ezenkívül ügyeljen a folyamatkezelő (pm) beállításaira is. Valójában ez a fő folyamat (főfolyamat), amely az összes alárendeltet (amelyek végrehajtják az alkalmazás kódját) egy bizonyos logika szerint kezeli, amely valójában a konfigurációs fájlban van leírva.
Összesen 3 folyamatvezérlési séma áll rendelkezésre:
- dinamikus
- statikus
- igény szerint
A legegyszerűbb az statikus. Munkájának sémája a következő: futtasson meghatározott számú gyermekfolyamatot, és tartsa őket futásban. Ez a munkaséma nem túl hatékony, mivel a kérések száma és terhelése időről időre változhat, de a gyermekfolyamatok száma nem - mindig egy bizonyos mennyiségű RAM-ot foglalnak el, és nem tudják felváltani a csúcsterheléseket.
dinamikus a pool megoldja ezt a problémát, a konfigurációs fájl értékei alapján szabályozza a gyermekfolyamatok számát, felfelé vagy lefelé változtatva azokat a terheléstől függően. Ez a készlet a legalkalmasabb olyan alkalmazáskiszolgálókhoz, amelyeknek gyors válaszra van szükségük egy kérésre, csúcsterhelés mellett kell dolgozni, és erőforrás-megtakarítást igényelnek (az utódfolyamatok tétlenségben történő csökkentésével).
igény szerint a medence nagyon hasonló statikus, de nem indít el gyermekfolyamatokat, amikor a fő folyamat elindul. Csak az első kérés megérkezésekor jön létre az első gyermekfolyamat, amely egy bizonyos (a konfigurációban megadott) időtúllépés után leállítja. Ezért releváns a korlátozott erőforrásokkal rendelkező szervereknél, vagy olyan logikánál, amely nem igényel gyors választ.
Memóriaszivárgás és OOM gyilkos
Ügyeljen az utódfolyamatok által végrehajtott alkalmazások minőségére. Ha az alkalmazás minősége nem túl magas, vagy sok harmadik féltől származó könyvtárat használnak, akkor gondolnia kell a lehetséges memóriaszivárgásokra, és be kell állítania az értékeket az alábbi változókra:
- pm.max_requests
- request_terminate_timeout
pm.max_requests ez a kérések maximális száma, amelyet az alárendelt folyamat feldolgozni fog a megölés előtt. Egy folyamat erőszakos leállításával elkerülhető az olyan helyzet, amelyben a gyermekfolyamat memóriája "megduzzad" a szivárgások miatt (mert a folyamat kérésről kérésre tovább működik). Másrészt a túl kicsi érték gyakori újraindítást eredményez, ami teljesítménycsökkenést eredményez. Érdemes 1000-es értékkel kezdeni, majd ezt az értéket csökkenteni vagy növelni.
request_terminate_timeout beállítja, hogy egy gyermekfolyamat mennyi ideig futhat a leállítás előtt. Ez elkerüli a hosszú lekérdezéseket, ha valamilyen oknál fogva a max_execution_time értéke megváltozott az értelmező beállításaiban. Az értéket mondjuk a feldolgozott alkalmazások logikája alapján kell beállítani 60-as évek(1 perc).
Dinamikus készlet konfigurálása
A fő alkalmazásszerver számára a nyilvánvaló előnyök miatt gyakran a dinamikus készletet választják. Működését a következő beállítások írják le:
- pm.max_children- a gyermekfolyamatok maximális száma
- pm.start_servers- folyamatok száma indításkor
- pm.min_spare_servers- a csatlakozásra váró folyamatok minimális száma (feldolgozási kérelmek)
- pm.max_spare_servers- a csatlakozásra váró folyamatok maximális száma (feldolgozási kérelmek)
Ezen értékek helyes beállításához figyelembe kell venni:
- mennyi memóriát fogyaszt átlagosan egy gyerekfolyamat
- elérhető RAM
Az ütemező segítségével megtudhatja a php-fpm folyamatonkénti átlagos memóriaértéket egy már futó alkalmazáson:
# ps -ylC php-fpm --sort:rss S UID PID PPID C PRI NI RSS SZ WCHAN TTY TIME CMD S 0 1445 1 0 80 0 9552 42588 ep_pol ? 00:00:00 php5-fpm
Szükségünk van az átlagos értékre az RSS oszlopban (rezidens memória mérete kilobájtban). Az én esetemben ~20Mb. Ha nincs terhelés az alkalmazásokban, az Apache Benchmark segítségével létrehozhatja a legegyszerűbb terhelést a php-fpm-en.
A teljes / rendelkezésre álló / használt memória mennyisége megtekinthető ingyenes:
# szabad -m összesen felhasznált ingyenes ... Memória: 4096 600 3496
Teljes maximális folyamatok = (Összes RAM - (felhasznált RAM + puffer)) / (Memória php folyamatonként) Teljes RAM: 4 GB RAM Felhasznált: 1000 MB biztonsági puffer: 400 MB memória gyermek php-fpm folyamatonként (átlag): 30 MB Maximális lehetséges szám folyamatok = (4096 - (1000 + 400)) / 30 = 89 Páros szám: 89 lefelé kerekítve 80-ra
A fennmaradó direktívák értékét az alkalmazás várható terhelése alapján lehet beállítani, és azt is figyelembe kell venni, hogy a php-fpm-en kívül mit csinál még a szerver (mondjuk a DBMS is erőforrásokat igényel). Ha sok feladat van a szerveren, akkor érdemes csökkenteni mind a kezdeti, mind a maximális folyamatok számát.
Például vegyük figyelembe, hogy 2 www1 és www2 pool van a szerveren (például 2 webes erőforrás), akkor mindegyik konfigurációja így nézhet ki:
pm.max_children = 40 ; 80 / 14 pm.start_servers = 15 pm.min_spare_servers = 15 pm.max_spare_servers = 25
1. GROUP BY egy gombbal
Ez a függvény GROUP BY-ként működik a tömbhöz, de egy fontos korlátozással: csak egy csoportosítási "oszlop" ($azonosító) lehetséges.
Függvény arrayUniqueByIdentifier(tömb $tömb, string $azonosító) ( $ids = tömb_oszlop($tömb, $azonosító); $ids = array_unique($ids); $tömb = array_filter($tömb, függvény ($kulcs, $érték ) use ($ids) ( return in_array($value, array_keys($ids)); ), ARRAY_FILTER_USE_BOTH); return $array; )
2. Egy táblázat egyedi sorainak észlelése (kétdimenziós tömb)
Ez a funkció a "sorok" szűrésére szolgál. Ha azt mondjuk, hogy egy kétdimenziós tömb egy táblázat, akkor minden eleme egy sor. Tehát ezzel a funkcióval eltávolíthatjuk a duplikált sorokat. Két sor (az első dimenzió elemei) egyenlő, ha minden oszlopuk (a második dimenzió elemei) egyenlő. Az "oszlop" értékek összehasonlítására vonatkozik: Ha egy érték egyszerű típusú, akkor magát az értéket fogják használni az összehasonlításhoz; ellenkező esetben a típusa (tömb , objektum , erőforrás , ismeretlen típus) kerül felhasználásra.
A stratégia egyszerű: Készíts az eredeti tömbből egy sekély tömböt, ahol az elemek az eredeti tömb d "oszlopai" lesznek; majd alkalmazza rá az array_unique(...) függvényt; és utolsóként használja az észlelt azonosítókat az eredeti tömb szűrésére.
Függvény arrayUniqueByRow(tömb $table = , string $implodeSeparator) ( $elementStrings = ; foreach ($tábla mint $sor) ( // Az olyan megjegyzések elkerülése érdekében, mint a "Tömb átalakítása karakterláncba". $elementPreparedForImplode = array_map(function ($field)) $valueType = gettype($field); $simpleTypes = ["boolean", "integer", "double", "float", "string", "NULL"]; $field = in_array($valueType, $simpleTypes) ? $field: $valueType; return $field; ), $row); $elementStrings = implode($implodeSeparator, $elementPreparedForImplode); ) $elementStringsUnique = array_unique($elemStrings); $table = array_intersect_key($table, $elementStringsUnique); $asztal visszaküldése;)
Az "oszlop" érték osztályának összehasonlító, észlelése is javítható, ha annak típusa objektum .
Az $implodeSeparator többé-kevésbé összetett legyen, z.B. spl_object_hash($this) .
3. Egy táblázat egyedi azonosító oszlopait tartalmazó sorok észlelése (kétdimenziós tömb)
Ez a megoldás a 2. megoldáson alapul. A teljes „sornak” nem kell egyedinek lennie. Két „sor” (az első dimenzió elemei) egyenlő most, ha az összes ide vonatkozó Az egyik "sor" "mezői" (a második dimenzió elemei) megegyeznek a megfelelő "mezőkkel" (azonos kulcsú elemek).
A "releváns" "mezők" a "mezők" (a második dimenzió elemei), amelyek kulcsa megegyezik az átadott "azonosítók" egyik elemével.
Function ArrayuniquyByMultIpleIdentifiers (tömb $ táblázat, tömb $ azonosítók, karakterlánc $ ImprodeParator = NULL) ($ ArrayFormakinguniquyRow = = array ($table, $arrayUniqueByRow); return $arrayUniqueByMultipleIdentifiers; ) függvény removeArrayColumns(tömb $tábla, tömb $oszlopNames, bool $isWhitelist = false) ( foreach ($tábla mint $rowKey => $row) ( if (is_array $row )) ( if ($isWhitelist) ( foreach ($sor mint $fieldName => $fieldValue) (if (!in_array($fieldName, $columnNames)) ( unset($table[$rowKey][$fieldName ]); ) ) ) else ( foreach ($sor mint $fieldName => $fieldValue) (if (in_array($fieldName, $columnNames)) ( unset($table[$rowKey][$fieldName]); ) ) ) ) ) $ asztal visszaküldése;)
Mióta a technológia fejlődése oda vezetett, hogy ma már minden programozónak van saját számítógépe, ennek mellékhatásaként több ezer különböző könyvtárunk, keretrendszerünk, szolgáltatásunk, API-nk stb. minden alkalomra. Ám amikor eljön ez az élet esete, akkor felmerül a probléma – mire használja őket, és mit tegyünk, ha nem egészen passzol – írjon át, írjon a semmiből a sajátját, vagy csavarjon be többféle megoldást különböző felhasználási esetekre.
Azt hiszem, sokan észrevették, hogy gyakran egy projekt létrehozása nem annyira programozáson múlik, mint inkább több kész megoldás integrálásához szükséges kód megírásán. Néha az ilyen kombinációk új megoldásokká alakulnak, amelyek ismételten felhasználhatók a következő problémákban.
Térjünk át egy adott „futó” feladatra – egy objektumrétegre a PHP adatbázisokkal való munkához. Rengeteg megoldás létezik, az ORM-től kezdve a többszintű (és véleményem szerint PHP-ban nem teljesen megfelelő) ORM-motorokig.
A legtöbb ilyen megoldás más platformokról költözött PHP-re. A szerzők azonban gyakran nem veszik figyelembe a PHP jellemzőit, ami nagyban leegyszerűsítené mind az írást, mind a hordozható konstrukciók használatát.
Ennek a feladatosztálynak az egyik gyakori architektúrája az Active Record minta. Különösen az úgynevezett entitások épülnek e minta szerint, amelyeket ilyen vagy olyan formában számos platformon használnak, kezdve az EJB3 persistent bean-jétől a .NET EF-ig.
Tehát építsünk egy hasonló konstrukciót PHP-hez. Kombináljunk két klassz dolgot - a kész ADODB könyvtárat és az objektumok gyengén tipizált és dinamikus tulajdonságait a PHP nyelvben.
Az ADODB számos funkciója közül az egyik az SQL lekérdezések úgynevezett automatikus generálása rekordok beszúrásához (INSERT) és frissítéséhez (UPDATE) adatokkal asszociatív tömbök alapján.
Valójában semmi sem katonailag használható egy tömbben, ahol a kulcsok a mezők nevei, az értékek pedig az adatok, és egy SQL lekérdezési karakterláncot generálnak. De az ADODB intelligensebben csinálja. A lekérdezés az adatbázissémából előzetesen kiolvasott táblastruktúra alapján épül fel. Ennek eredményeként először is csak a meglévő mezők kerülnek be az sql-be, és nem minden sorban, másodsorban a mező típusát veszik figyelembe - a karakterláncokhoz idézőjeleket adnak, dátumformátumok alakíthatók időbélyeg alapján, ha az ADODB látja. karakterlánc helyett a továbbított értékben stb.
Most menjünk a PHP oldaláról.
Képzeljünk el egy ilyen osztályt (leegyszerűsítve).
Osztályentitás( védett $fields = array(); nyilvános végső függvény __set($name, $value) ($this->fields[$name] = $érték; ) nyilvános végső függvény __get($name) ( return $ this- >fields[$name]; ) )
A belső tömbnek az ADODB könyvtárba való átadásával automatikusan generálhatunk SQL lekérdezéseket, hogy ezzel az objektummal frissítsünk egy rekordot az adatbázisban, ugyanakkor az adatbázistáblák mezőinek leképezése egy entitás objektum mezőire XML és XML alapú, ill. hasonlókra nincs szükség. Csak az szükséges, hogy a mezőnév egyezzen az objektum tulajdonságával. Mivel az adatbázis mezőinek és az objektum mezőinek elnevezése nem számít a számítógép számára, nincs ok arra, hogy ne egyezzenek.
Mutassuk meg, hogyan működik a végső verzióban.
Az elvégzett osztály kódja a Gist oldalon található. Ez egy absztrakt osztály, amely az adatbázissal való munkához szükséges minimumot tartalmazza. Megjegyzem, hogy ez az osztály a több tucat projekten kidolgozott megoldás egyszerűsített változata.
Képzeljük el, hogy van egy ilyen táblázatunk:
TÁBLÁZAT LÉTREHOZÁSA "felhasználók" ("felhasználónév" varchar(255) , "létrehozás" dátuma, "user_id" int(11) NOT NULL AUTO_INCREMENT, ELSŐDLEGES KULCS ("felhasználói_azonosító"))
Az adatbázis típusa nem számít – az ADODB hordozhatóságot biztosít az összes általános adatbázis-kiszolgáló számára.
Hozzunk létre egy User entitásosztályt az Entity osztály alapján
/** * @table=users * @keyfield=user_id */ osztály A felhasználó kiterjeszti az entitást( )
Valójában ez minden.
Egyszerűen használva:
$user = new User(); $user->username="Vasya Pupkin"; $user->created=time(); $user->save(); //mentés tárhelyre //újratöltés $thesameuser = User::load($user->user_id); echo $thesameuser ->felhasználónév;
Áljegyzetekben adjuk meg a táblázatot és a kulcsmezőt.
Megadhatunk egy nézetet is (például view =usersview), ha – ahogy az gyakran előfordul – az entitást a csatolt vagy számított mezőket tartalmazó táblázata alapján választjuk ki. Ebben az esetben az adatok a nézetből kerülnek kiválasztásra, és a táblázat frissül. Aki nem szereti az ilyen annotációkat, az felülírhatja a getMetatada() metódust, és megadhatja a tábla paramétereit a visszaadott tömbben.
Mi más hasznos az Entity osztályban ebben a megvalósításban?
Például felülírhatjuk az init() metódust, amely egy entitáspéldány létrehozása után kerül meghívásra, hogy inicializáljuk az alapértelmezett létrehozási dátumot.
Vagy töltse túl az afterLoad() metódust, amely automatikusan meghívódik az entitás adatbázisból való betöltése után, hogy a dátumot időbélyegzővé alakítsa a további kényelmesebb használat érdekében.
Ennek eredményeként nem sokkal bonyolultabb szerkezetet kapunk.
/** * @table=users * @view=usersview * @keyfield=user_id */ class A felhasználó kiterjeszti az Entity( protected function init() ( $this->created = time(); ) Protected function afterLoad() ( $this ->létrehozva = strtotime($this->created); ) )
Túlterhelheti a beforeSave és beforeDelete metódusokat és egyéb életciklus-eseményeket is, ahol például ellenőrzést hajthat végre a mentés előtt vagy más műveleteket – például képeket távolíthat el a feltöltésből a felhasználó törlésekor.
Az entitások listáját a feltétel szerint töltjük be (valójában a WHERE feltételek).
$users = User::load("felhasználónév mint "Pupkin" ");
Ezenkívül az Entity osztály lehetővé teszi egy tetszőleges, "natív" SQL lekérdezés végrehajtását. Például szeretnénk visszaadni egy listát a felhasználókról néhány csoportosítással a statisztikák szerint. Nem számít, hogy mely konkrét mezők kerülnek visszaadásra (a lényeg, hogy legyen user_id, ha az entitás további manipulálására van szükség), csak a nevüket kell ismerni a kiválasztott mezők eléréséhez. Egy entitás mentésekor, amint az a fentiekből is kitűnik, szintén nem szükséges minden olyan mezőt kitölteni, amely az entitásobjektumban jelen lesz, azok az adatbázisba kerülnek. Vagyis nem kell további osztályokat létrehoznunk tetszőleges kijelölésekhez. Körülbelül olyan, mint az anonim struktúrák az EF-ben történő lekéréskor, csak itt ugyanaz az entitásosztály az összes üzleti logikai metódussal.
Szigorúan véve a fenti listák beszerzési módszerei némileg kívül esnek az AR mintán. Alapvetően ezek gyári módszerek. De ahogy Ockham öregje hagyta, nem állítunk elő entitásokat a szükséges mértéken túl, és nem kerítünk külön entitásmenedzsert vagy valami hasonlót.
Vegye figyelembe, hogy a fentiek csak PHP osztályok, és tetszés szerint bővíthetők és módosíthatók, hozzáadva az üzleti logika tulajdonságait és metódusait az entitáshoz (vagy az alap Entity osztályhoz). Vagyis nem csak egy adatbázis tábla sorának másolatát kapjuk meg, hanem egy üzleti entitást is az alkalmazás objektumarchitektúrájának részeként.
Ki profitálhat ebből? Természetesen nem azoknak a fejlesztőknek, akiknek nincs dolga, akik azt hiszik, hogy a doktrínánál egyszerűbb dolgok használata nem szilárd, és nem a perfekcionisták számára, akik biztosak abban, hogy ha egy megoldás nem hoz ki egymilliárd DB hozzáférést másodpercenként, akkor ez nem megoldás. A fórumok alapján sok hétköznapi fejlesztő (amelynek 99,9%-a) előbb-utóbb szembesül azzal a problémával, hogy egyszerű és kényelmes objektummódot találjon az adatbázis eléréséhez. De szembesülnek azzal a ténnyel, hogy a legtöbb megoldás vagy indokolatlanul divatos, vagy egy keret része.
P.S. A keretből, mint külön projektből döntött