미국 국립 표준 연구소(영어) ㅏ미국인 N에이셔널 에스표준 나학회, ANSI)는 무역 및 통신 표준을 개발하는 미국 산업 및 비즈니스 그룹의 협회입니다. 그는 ISO 및 IEC의 회원이며 그곳에서 미국의 이익을 대표합니다.
이야기
ANSI는 원래 1918년 5개의 엔지니어링 협회와 3개의 정부 기관이 "미국 엔지니어링 표준 위원회"(American Engineering Standards Committee)를 설립하면서 형성되었습니다. AESC- 영어. 미국 엔지니어링 표준 위원회). 1928년에 위원회는 미국 표준 협회로 알려지게 되었습니다. ASA- 영어. 미국 표준 협회). 1966년 ASA는 개편되어 "미국 표준 연구소"가 되었습니다. USASI- 영어. 미국 표준 연구소). 현재 이름은 1969년에 채택되었습니다.
1918년까지 기술 표준 개발에 관련된 5개의 엔지니어링 협회가 있었습니다.
- 미국전기공학회(AIEE, 현재 IEEE)
- 미국기계학회(ASME)
- 미국 토목 학회(ASCE)
- American Institute of Mining Engineers(AIME, 현재 American Institute of Mining, Metallurgical and Petroleum Engineers)
- 미국재료시험협회(현재 ASTM)
1916년에 미국 전기 엔지니어 협회(현재 IEEE)는 표준 개발, 조화 및 국가 표준 승인을 조정하기 위해 독립적인 국가 기구를 구성하기 위해 이러한 조직을 함께 모으는 주도권을 잡았습니다. 위의 5개 단체는 United Engineering Society(United Engineering Society - UES)의 주요 회원이 되었으며, 이후 미국 국방부가 창립자로 초대되어 참여하게 되었으며, 해군(1947년에 병합되어 미국 국방부가 됨) 상무부.
1931년에 이 조직(1928년 ASA로 개명)은 전기 및 전자 공학 표준을 개발하기 위해 1904년에 설립된 IEC(International Electrotechnical Commission)의 미국 국가 위원회의 일부가 되었습니다.
회원
ANSI 회원에는 정부 기관, 조직, 학계 및 국제 조직, 개인이 포함됩니다. 전체적으로 이 연구소는 전 세계 270,000개 이상의 기업 및 조직과 3천만 명의 전문가의 이익을 대변합니다.
활동
ANSI 자체가 표준을 개발하지는 않지만, 연구소는 표준 개발 기관의 절차 승인을 통해 표준의 개발 및 사용을 감독합니다. ANSI 인증은 표준 개발 조직에서 사용하는 절차가 개방성, 균형, 합의 및 적법 절차에 대한 기관의 요구 사항을 충족한다는 것을 의미합니다.
ANSI는 또한 연구소가 표준이 공정하고 접근 가능하며 다양한 이해 관계자의 요구에 부응하는 환경에서 개발되었다고 결정할 때 특정 표준을 미국 국가 표준(ANS)으로 지정합니다.
국제 활동
미국 표준화 활동 외에도 ANSI는 미국 표준의 국제적 사용을 촉진하고 국제 및 지역 표준 조직에서 미국의 정치적, 기술적 위치를 옹호하며 국제 표준을 국가 표준으로 채택하도록 장려합니다.
이 연구소는 창립 멤버인 ISO(International Organization for Standardization)와 USNC(US National Committee)를 통한 IEC(International Electrotechnical Commission)의 두 가지 주요 국제 표준 기구의 공식 미국 대표입니다. ANSI는 거의 모든 기술 프로그램 ISO 및 IEC 및 많은 주요 위원회 및 하위 그룹을 관리합니다. 많은 경우에 미국 표준은 ANSI 또는 USNC를 통해 ISO 및 IEC에 제출되며, 여기에서 전체 또는 일부가 국제 표준으로 승인됩니다.
ISO 및 IEC 표준을 미국 표준으로 채택하는 비율은 1986년 0.2%에서 2012년 5월 15.5%로 증가했습니다.
표준화 방향
연구소는 9개의 표준화 그룹을 관리합니다.
- ANSI HDSSC(국토 방위 및 보안 표준화 협력)
- ANSI 나노기술 표준 패널(ANSI-NSP - ANSI 나노기술 표준 패널)
- ID 도용 방지 및 ID 관리 표준 패널(IDSP - ID 도용 방지 및 ID 관리 표준 패널)
- ANSI 에너지 효율 표준화 조정 협력(EESCC)
- 원자력 표준 조정 협력(NESCC-원자력 표준 조정 협력)
- 전기 자동차 표준 패널(EVSP)
- 화학 규제에 관한 ANSI-NAM 네트워크
- ANSI 바이오연료 표준 조정 패널
- 의료 정보 기술 표준 패널(HITSP)
- 미국 배관 및 기계 인증 기관
각 그룹은 이러한 영역과 관련된 자발적 표준을 식별, 조정 및 조화시키는 작업에 참여하고 있습니다. 2009년에 ANSI와 (NIST)는 NESCC(Nuclear Energy Standards Coordinating Collaboration)를 구성했습니다. NESCC는 원자력 산업의 표준에 대한 현재 요구 사항을 식별하고 충족하기 위한 공동 이니셔티브입니다.
표준
연구소에서 채택한 표준 중 다음이 알려져 있습니다.
널리 알려진 오해와 달리 ANSI는 ISO-8859-1 인코딩 및 일부 다른 인코딩 개발에 참여했지만 8비트 코드 페이지 표준을 채택하지 않았습니다.
메모
- ANSI 소개
- RFC
- ANSI: 역사적 개요 (무기한) . si.org. 2016년 10월 31일에 확인함.
- ANSI의 역사
모든 ANSI 압력 등급 지정에는 특정 의미, 즉 압력 값이 있지만 우리에게 익숙한 것과 다른 단위에만 있다는 점은 주목할 가치가 있습니다. ANSI 뒤의 모든 숫자는 공칭(공칭) 압력 값을 나타냅니다: ANSI 150, ANSI 300, ANSI 600, ANSI 900, ANSI 1500, ANSI 2500 and ANSI 4500. 예를 들어, ANSI 150은 공칭 압력이 150psi임을 의미합니다. 영어로는 제곱인치당 파운드포스(Pound-force per Square Inch) 또는 줄여서 PSI로 표기합니다.
따라서 이러한 방식으로 제곱인치당 파운드에서 바(100kPa) 또는 MPa로 독립적으로 변환하는 것이 가능합니다. 정확한 것을 독립적으로 계산하려면 1 PSI \u003d 6894.76 Pa를 알아야합니다. bar와 Pascal의 모든 ANSI 압력 계산은 시간이 있고 정확한 데이터가 필요할 때 수행할 수 있으며 동시에 대부분의 표준 ANSI 압력 등급 값은 이미 bar 및 MPa의 표준 값을 가지고 있습니다. 단순화하기 위해 참조용으로 짧은 표를 작성했습니다.
Bar 및 MPa로 변환된 ANSI 압력 등급 표
|
ANSI 압력 등급 |
||
때로는 숙련 된 전문가조차도 한 시스템의 특정 압력 또는 길이 값이 다른 수량 시스템의 값에 해당하는지 즉시 알려주지 않습니다.
에게 덜다당신이이 작업, 우리는 작은 유럽과 미국 시스템에서 압력과 길이 사이의 관계에 대한 테이블을 제공합니다 설명. 그러나 먼저 표준 자체에 대한 몇 마디.
소음는 독일 표준입니다( Deutsches Institut für Normung, 즉, 독일 표준화 연구소에서 개발한 것으로, 국제 표준화 기구 - ISO(국제 표준화 기구) 조항의 틀 내에서 엄격하게 개발되었습니다.
ANSI미국에서 채택된 표준입니다. 의 약자 미국 국립 표준 연구소, 이는 미국 국립 표준 연구소(American National Standards Institute) 표준입니다.
따라서 ANSI 표준은 바로 이 기관에 의해 결정되며 지금까지 항상은 아니다표준 사이 소음그리고 ANSI정확한 추적이 가능 규정 준수다양한 분야에서.
압력 단위를 ANSI에서 DIN으로 변환
여기에서는 모든 것이 간단합니다. 표준에 따르면 ANSI압력 반대는 숫자 150입니다. 이는 공칭(밸브가 설계된) 압력이 20bar, 300-50bar 등임을 의미합니다. 최대값 ANSI 클래스– 2500은 유럽 표준에 따라 420bar와 같습니다. 소음.
이 표를 이용하여, 어렵지 않음압력 값을 변환하거나 그 반대로 변환하십시오. 소음안에 ANSI, 우리 엔지니어들은 훨씬 더 많은 것을 필요로 하지만 덜 자주.
미국 시스템에서 유럽(러시아)으로 길이 단위 변환
알려진 바와 같이, 미국인모든 것은 인치와 피트로 측정되며 우리는 유럽인- 밀리미터, 센티미터 및 미터, 즉 세계의 대다수 국가와 마찬가지로 우리가 살고 있습니다. 미터법단위 시스템.
인치를 밀리미터로 변환하는 방법은 무엇입니까? 사실, 이것에 대해서도 복잡한 것은 없습니다. 1인치는 25.4mm임을 기억하십시오. 그러나 종종 소수점 이하 자릿수 소홀히 하다그리고 좋은 측정을 위해 1인치 = 25mm.
따라서 예를 들어 입구의 단면이 미국식 측정법에 따라 2인치인 경우 위의 규칙에 따라 이 값을 우리의 측정법으로 변환하면 50mm 또는 더 정확하게는, 51mm(규칙에 따라 반올림 50.8) .
의 직경을 추가해야 합니다. 전문인특성은 라틴 문자로 표시됩니다. DN에 자주 표시됩니다. 신장, 압력은 문자로 표시됩니다. PN에 가장 자주 표시됩니다. 바- 어쨌든, 우리는 정확히 이 표시를 가장 많이 사용합니다. 편안한.
그리고 다음 표 도움이 될 것입니다당신은 뿐만 아니라 계산 정확한 1인치의 밀리미터 수(1000분의 1밀리미터의 정확도)이지만, 예를 들어 2.5인치에 몇 밀리미터가 들어 있는지 알아내는 데도 도움이 됩니다.
이를 위해 열 2 ""(2인치)를 찾고 왼쪽에서 1/2 값을 찾습니다. 총 2.5인치 = 63.501mm(64mm로 반올림 가능), 예를 들어 6.25인치(즉, 6 및 1/4) = 158.753mm 또는 159mm입니다.
|
| 인치 ""에서 밀리미터로 |
|||||||
|
| ||||||||
|
| ||||||||
Reg.ru: 도메인 및 호스팅
러시아에서 가장 큰 등록 기관 및 호스팅 제공업체입니다.
2백만 개 이상의 도메인 이름이 서비스 중입니다.
프로모션, 도메인용 메일, 비즈니스용 솔루션.
전 세계적으로 700,000명 이상의 고객이 이미 선택했습니다.
* 스크롤을 일시 중지하려면 마우스를 가져갑니다.
뒤로 앞으로
인코딩: 유용한 정보 및 간략한 회고
나는 이 기사를 인코딩 문제에 대한 작은 리뷰로 쓰기로 결정했습니다.
우리는 일반적으로 인코딩이 무엇인지 이해하고 원칙적으로 어떻게 나타나는지 역사에 대해 조금 다룰 것입니다.
우리는 일부 기능에 대해 이야기하고 더 의식적으로 인코딩 작업을 수행하고 소위 말하는 것을 피할 수 있는 요점도 고려할 것입니다. 크라코자브로프, 즉. 읽을 수 없는 문자.
그럼 가자...
인코딩이란 무엇입니까?
간단히 말해서, 부호화화면에서 볼 수 있는 특정 숫자 코드에 대한 문자 매핑 테이블입니다.
저것들. 키보드에서 입력하거나 모니터 화면에서 보는 각 문자는 특정 비트 시퀀스(0과 1)로 인코딩됩니다. 아시다시피 8비트는 1바이트 정보와 동일하지만 나중에 자세히 설명합니다.
문자 자체의 모양은 글꼴 파일에 의해 결정됩니다.컴퓨터에 설치되어 있습니다. 따라서 화면에 텍스트를 표시하는 프로세스는 0과 1의 시퀀스를 글꼴의 일부인 특정 문자에 지속적으로 매핑하는 것으로 설명할 수 있습니다.
모든 현대 인코딩의 조상으로 간주될 수 있습니다. 아스키.
이 약어는 정보 교환을 위한 미국 표준 코드(인쇄 가능한 문자 및 일부 특수 코드에 대한 미국 표준 인코딩 테이블).
그것 단일 바이트 인코딩, 원래 128자(라틴 알파벳 문자, 아라비아 숫자 등)만 포함했습니다.

나중에 확장(초기에는 8비트를 모두 사용하지 않음)하여 1바이트 정보에 인코딩할 수 있는 128개가 아닌 256개(2~8개)의 다른 문자를 사용할 수 있게 되었습니다.
이 개선으로 ASCII에 추가할 수 있었습니다. 자국어의 상징, 이미 존재하는 라틴 알파벳에 추가로.
세계에는 많은 언어가 있기 때문에 확장 ASCII 인코딩에는 많은 옵션이 있습니다. 나는 많은 사람들이 다음과 같은 인코딩에 대해 들어 본 적이 있다고 생각합니다. KOI8-R은 또한 확장된 ASCII 인코딩입니다., 러시아어 문자와 함께 작동하도록 설계되었습니다.
인코딩 개발의 다음 단계는 소위 ANSI 인코딩.
본질적으로 그들은 동일했습니다. ASCII의 확장 버전그러나 이전에는 "여유 공간"이 충분하지 않은 다양한 의사 그래픽 요소가 제거되고 활자체 기호가 추가되었습니다.
이러한 ANSI 인코딩의 예는 잘 알려진 윈도우-1251. 인쇄상의 기호 외에도이 인코딩에는 러시아어 (우크라이나어, 벨로루시어, 세르비아어, 마케도니아어 및 불가리아어)에 가까운 언어 알파벳 문자도 포함되었습니다.
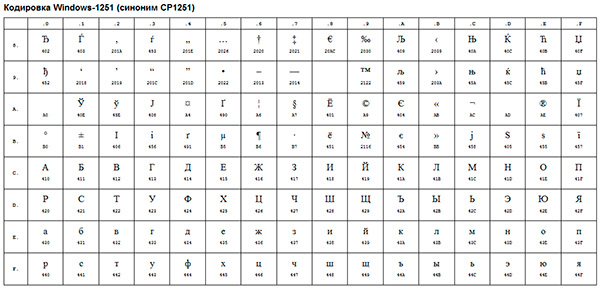
ANSI 인코딩은. 실제로 ANSI를 사용할 때의 실제 인코딩은 레지스트리에 지정된 내용에 따라 결정됩니다. 운영 체제윈도우. 러시아어의 경우 Windows-1251이 되지만 다른 언어의 경우 다른 종류의 ANSI가 됩니다.
아시다시피, 인코딩의 무리와 단일 표준의 부족으로 인해 좋은 결과를 얻지 못했기 때문에 소위 말하는 크라코자브리- 읽을 수 없는 의미 없는 문자 집합입니다.
그들의 출현 이유는 간단합니다. 다른 인코딩 테이블을 사용하여 한 인코딩 테이블로 인코딩된 문자를 표시하려고 시도합니다..
웹 개발의 맥락에서, 예를 들어 다음과 같은 경우 버그가 발생할 수 있습니다. 러시아어 텍스트가 서버에서 사용되는 잘못된 인코딩으로 잘못 저장되었습니다..
물론 읽을 수 없는 텍스트를 얻을 수 있는 유일한 경우는 아닙니다. 여기에는 많은 옵션이 있습니다. 특히 정보가 특정 인코딩으로 저장되어 있는 데이터베이스도 있다고 생각할 때 데이터베이스 연결이 있습니다. 매핑 등
이러한 모든 문제의 출현은 새로운 것을 창조하는 동기로 작용했습니다. 그것은 세계의 모든 언어를 인코딩할 수 있는 인코딩이어야 했습니다. 중국인, 분명히 256개가 넘는 경우), 추가 특수 문자 및 타이포그래피.
한마디로 만들 필요가 있었다. 버그 문제를 한 번에 해결할 수 있는 범용 인코딩.
유니코드 - 범용 텍스트 인코딩(UTF-32, UTF-16 및 UTF-8)
표준 자체는 비영리 단체에서 1991년에 제안했습니다. "유니코드 컨소시엄"(Unicode Consortium, Unicode Inc.) 및 그의 작업의 첫 번째 결과는 인코딩의 생성이었습니다. UTF-32.
덧붙여서, 약어 UTF의 약자 유니코드 변환 형식(유니코드 변환 형식).
이 인코딩에서 하나의 문자를 인코딩하려면 32비트, 즉. 4바이트 정보. 이 숫자를 단일 바이트 인코딩과 비교하면 간단한 결론에 도달합니다. 이 범용 인코딩에서 1자를 인코딩하려면 다음이 필요합니다. 4배 더 많은 비트, 파일을 4번 "가중치"합니다.
또한 이 인코딩을 사용하여 잠재적으로 설명할 수 있는 문자 수가 모든 합리적인 제한을 초과하고 기술적으로 2의 32승으로 제한된다는 것이 분명합니다. 이것은 파일의 무게 측면에서 명백한 과잉 및 낭비임이 분명하므로 이 인코딩은 널리 사용되지 않았습니다.
새로운 개발 - UTF-16으로 대체되었습니다..
이름에서 알 수 있듯이 이 인코딩에서는 하나의 문자가 인코딩됩니다. 더 이상 32비트가 아니라 16비트(즉, 2바이트). 분명히 이것은 모든 문자를 UTF-32보다 두 배 "가벼운" 것으로 만들지만 단일 바이트 인코딩을 사용하여 인코딩된 모든 문자보다 두 배 "무겁게" 만듭니다.
UTF-16으로 인코딩할 수 있는 문자 수는 최소 2의 16승입니다. 65536자. 모든 것이 괜찮은 것 같습니다. 게다가 UTF-16에서 코드 공간의 최종 값은 100만 문자 이상으로 확장되었습니다.
그러나 이 인코딩은 개발자의 요구를 완전히 충족시키지 못했습니다. 라틴 문자만 사용하여 작성하는 경우 ASCII 인코딩의 확장 버전에서 UTF-16으로 전환한 후 각 파일의 가중치가 두 배가 된다고 가정해 보겠습니다.
결과적으로, 보편적인 것을 만들기 위한 또 다른 시도가 있었습니다., 그리고 이것은 잘 알려진 UTF-8 인코딩이 되었습니다.
UTF-8- 이것은 가변 문자 길이의 멀티바이트 문자 인코딩. 이름을 보면 UTF-32 및 UTF-16과 유사하게 하나의 문자를 인코딩하는 데 8비트가 사용된다고 생각할 수 있지만 그렇지 않습니다. 더 정확하게는 그렇지 않습니다.
이는 UTF-8이 8비트 문자를 사용하는 이전 시스템과 최상의 호환성을 제공하기 때문입니다. UTF-8로 단일 문자를 인코딩하는 데 실제로 사용됩니다. 1~4바이트(가상적으로 최대 6바이트까지 가능).
UTF-8에서 모든 라틴 문자는 ASCII 인코딩과 마찬가지로 8비트로 인코딩됩니다.. 즉, ASCII 인코딩의 기본 부분(128자)이 UTF-8로 이동하여 모든 것이 시작된 인코딩의 보편성을 유지하면서 표현에 1바이트만 "사용"할 수 있습니다.
따라서 처음 128개의 문자가 1바이트로 인코딩되면 다른 모든 문자는 이미 2바이트 이상으로 인코딩됩니다. 특히 각 키릴 문자는 정확히 2바이트로 인코딩됩니다.
따라서 불필요하게 "무거운" 파일 없이 표시해야 하는 모든 가능한 문자를 포함할 수 있는 범용 인코딩을 얻었습니다.
BOM이 있거나 BOM이 없습니까?
함께 작업한 경우 텍스트 편집기(코드 편집기에 의해), 예를 들어 메모장++, PHP디자이너, 빠른 PHP등, 그러면 페이지가 생성될 인코딩을 설정할 때 일반적으로 3가지 옵션을 선택할 수 있다는 사실에 주의를 기울였을 것입니다.
ANSI
-UTF-8
- BOM이 없는 UTF-8


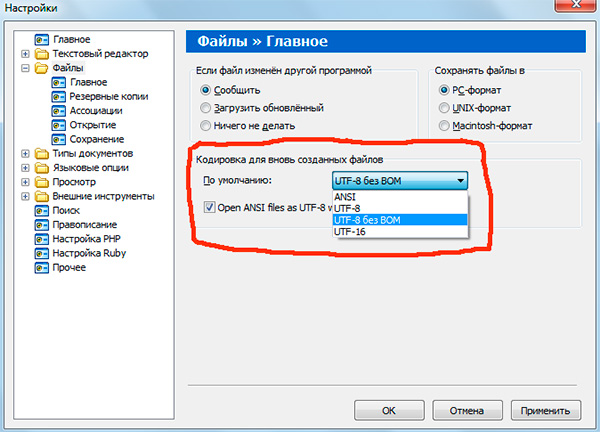
나는 그것이 항상 선택할 가치가 있다고 즉시 말할 것입니다. 마지막 옵션 - BOM이 없는 UTF-8.
그렇다면 BOM은 무엇이며 왜 필요하지 않습니까?
봄의 약자 바이트 순서 표시. 이것은 엔디안을 나타내는 데 사용되는 특수 유니코드 문자입니다. 텍스트 파일. 사양에 따르면 그 사용은 선택 사항이지만 다음과 같은 경우 봄사용되는 경우 텍스트 파일의 시작 부분에 설정해야 합니다.
우리는 작업의 세부 사항에 들어가지 않을 것입니다 봄. 우리의 주요 결론은 다음과 같습니다. 이 서비스 문자를 UTF-8과 함께 사용하면 프로그램이 인코딩을 정상적으로 읽을 수 없습니다., 스크립트 오류가 발생합니다.
ANSI는 American National Standards Institute(코드 1251)에서 개발한 문자 표시 표준입니다. ANSI 표준은 각 문자를 나타내는 데 1바이트만 사용하므로 구두점을 포함하여 최대 256자로 제한됩니다. 코드 32 ~ 126은 ASCII 표준을 따릅니다. ASCII(코드 688)는 DOS에서 사용되었고 ANSI는 Windows에서 사용되었습니다.
문학
아르한겔스키 A.Ya. C++ Builder6에서의 프로그래밍. 에드. 바이놈, 2004.
아르한겔스키 A.Ya. C++빌더6. 참조 메뉴얼. 모스크바, 에드. 바이놈, 2004.
Kimmel P. Borland C++5 "BHV-St. Petersburg, 2001.
클리모바 L.M. C++ 실용 프로그래밍. 일반적인 작업의 솔루션입니다. "KUDITS-IMAGE", M.2001.
작업 및 예제의 Kultin N. С/С++. 상트페테르부르크 "BHV-Petersburg", 2003.
파블로프스카야 T.A. 고급 언어로 된 C/C++ 프로그래밍. 피터, 모스크바-상트페테르부르크-… 2005
Pavlovskaya T.A., Shchupak Yu.A. C++. 객체 지향 프로그래밍. 작업장. SPb., Peter, 2005.
포드벨스키 V.V. C++ 언어 금융 및 통계, 모스크바, 2003.
Polyakov A.Yu., Brusentsev V.A. 방법 및 알고리즘 컴퓨터 그래픽 Visual C++의 예제에서. SPb BHI-Petersburg, 2003
Savitch W. Language C++ 객체 지향 프로그래밍 과정. 윌리엄스 출판사. 모스크바-상트페테르부르크-키예프, 2001
Wellin S. C++로 프로그래밍하지 않는 방법. "베드로". Moscow-St. Petersburg-Nizhny Novgorod-Voronezh-Novosibirsk-Rostov-on-Don-Yekaterinburg-Samara-Kyiv-Kharkov-Minsk, 2004.
실드 G. 완전한 참조 C++에서. 에드. House "Williams" 모스크바-상트페테르부르크-키예프, 2003.
Schildt G. 독학 C/C++. 상트페테르부르크, BHV-Petersburg, 2004.
Schildt G. 프로그래머 가이드 C/C++ Ed. House "Williams" 모스크바-상트페테르부르크-키예프, 2003.
시마노비치.L. 예제 및 작업의 С/С++. 민스크, 새로운 지식, 2004.
Stern V. C++의 기초. 소프트웨어 엔지니어링 방법. 에드. 로리.
콘솔 응용 프로그램에서 러시아어 문자 대신 쓰레기가 표시되는 이유는 무엇입니까?
그리고 맞아! 기본 편집기에 입력한 프로그램의 텍스트 비주얼 스튜디오, 코드 페이지 1251을 사용하고 콘솔 애플리케이션의 텍스트 출력은 코드 페이지 866을 사용하고 있습니다. 이 수치를 어떻게 해야 할까요? 아시다시피, 교착 상태에서 적어도 3개의 출구가 있습니다. 순서대로 고려합시다.
1번 출구
콘솔 파일 관리자의 편집기에 프로그램 텍스트를 입력합니다.
그러나 구문 강조 표시, F1을 사용하여 선택한 기능에 대한 도움말 표시 및 단순한 프로그래머의 암울한 삶을 밝게 해주는 기타 작은 매력은 어떻습니까? 아니요, 이것은 우리를 위한 옵션이 아닙니다.
2번 출구
콘솔 프로그램을 처음부터 작성하기 시작했다면 적합할 수 있습니다. 우리의 작은 걸작을 다음과 같이 다시 작성해 보겠습니다.
|
#include "stdafx.h" #include "windows.h" int main(int argc, char* argv) char s="안녕하세요!"; printf("%s\n", s); |
여기서 키워드는 CharToOem입니다. 문자열을 원하는 코드 페이지로 변환하는 것은 이 함수입니다. 우리 프로그램의 출력으로 이제 모든 것이 정상입니다.
그러나 다음 질문이 발생합니다. Borland C++ 3.1로 작성된 이전 100,000줄 DOS 프로그램을 두 번째 줄마다 이러한 상황이 발생하는 Windows 콘솔 응용 프로그램으로 재컴파일해야 하는 경우 수행할 작업입니다. 하지만 여전히 MS 컴파일러에 맞게 조정해야 하며 몇 가지 코드를 최적화하고 싶기도 합니다.
여기서 기사의 움직임을 사용하는 것이 합리적일 것입니다.