…Chociaż składnia HTML jest stosunkowo prosta do nauczenia,… jest jeszcze wiele elementów, atrybutów i… innych pojęć, których będziesz musiał się nauczyć i śledzić.… Chociaż ten kurs ma na celu wprowadzenie do podstaw HTML, to "naprawdę nie jest zaprojektowane tak, aby nauczyć cię każdego dostępnego elementu i atrybutu. Mając to na uwadze, chcę dać ci kilka zasobów HTML online, które naprawdę mogą ci pomóc jako zaczynasz uczyć się HTML i… możesz później służyć jako cenne odniesienia, gdy będziesz tworzyć własne strony… Teraz zaczniemy od samych specyfikacji…
I to jest coś, dwa dokumenty, które zdecydowanie powinieneś dodać do zakładek.…Więc to jest wersja HTML5 W3Cs.…Widać, że mają najnowszą wersję dla wydawcy.…Możesz zobaczyć wersję roboczą redaktora,…jeśli chcę zobaczyć, co schodzi w dół, w dół rury… I to jest dość duże… Jeśli przewinę w dół, możesz zobacz, że tutaj jest tylko spis treści… I nawet nie zamierzam przewijać ich wszystkich…
Automatyczne przewijanie transkrypcji CV
Zaktualizowano
3/30/2017Wydany
3/16/2015HTML to język programowania, który napędza sieć. I jak każdy język, kiedy już go opanujesz, możesz zacząć tworzyć własne treści, niezależnie od tego, czy są to proste strony internetowe, czy złożone aplikacje internetowe. Ten kurs zapewnia dogłębne spojrzenie na podstawowe elementy: składnię HTML i najlepsze praktyki w zakresie autor starszego personelu, James Williamson, przegląda strukturę typowego dokumentu HTML i pokazuje, jak dzielić strony i formatować zawartość za pomocą HTML. Ponadto, dowiedz się, jak tworzyć łącza i listy, oraz dowiedz się, jak HTML współpracuje z CSS i JavaScript w celu tworzenia bogatych , angażujące wrażenia użytkownika.
Tematy obejmują:
- Dlaczego HTML jest ważny?
- Eksploracja dokumentu HTML
- Formatowanie treści
- Wyświetl obrazy
- Korzystanie z elementów nav, article i div
- Linki do stron i treści do pobrania
- Tworzenie list
- Kontrolowanie stylu (czcionki, kolory i więcej)
- Pisanie podstawowych skryptów
: Zawsze chciałem to zrozumieć, ale jego znaczenie było tak małe, że zawsze był powód, aby tego nie robić :)
I zastanawiałeś się: URL - co to jest?
Zawsze się na to natykam, ale nadal nie chciałem zrozumieć różnicy między terminami URI, URL, URN, a potem nagle postem (niestety już zapadł w zapomnienie), postanowiłem - przeczytam ja i powiem innym, chociaż jak wspomniano powyżej nic się od tego nie zmieni, ale czasami lubię przeliterować, więc poczytaj rozsądnego tłumacza:
Czy kiedykolwiek zwracałeś uwagę na pasek adresu w swojej przeglądarce? Co to jest? URI, URL czy URN? Wielu z nas nie rozróżnia URI, URL, URN, a niektórzy z nas nigdy nawet nie słyszeli o terminach URI i URN, wszyscy po prostu używają terminu URL. Spróbujmy razem to rozgryźć.
Wyjaśnienie skrótów
URI — jednolity identyfikator zasobu (jednolity identyfikator ratunek)
URL — jednolity lokalizator zasobów (ujednolicony wyszukiwarka lokalizacji ratunek)
URN — Jednolita nazwa zasobu (jednolita Nazwa ratunek)
Uwaga, tutaj prawda tkwi w drobiazgach, ale na razie nic nie jest jasne, jakiś bałagan. Chodźmy dalej.
Definicja
URI: Wskazuje nazwę i adres zasobu w sieci. Ogólnie podzielony na URL i URN, więc URL i URN są składnikami identyfikatora URI.
URL: adres jakiegoś zasobu w sieci. Adres URL określa lokalizację zasobu i sposób uzyskania do niego dostępu.
URN: nazwa jakiegoś zasobu w sieci. Celem URN jest to, że definiuje tylko nazwę konkretnego elementu, który można znaleźć w wielu określonych miejscach.
Nie ma nic lepszego niż konkretny przykład
URI = http://site/2009/09/uri-url-urn.html
URL = http://witryna
URL=/2009/09/uri-url-urn.html
Podsumowując
URI to pojęcie abstrakcyjnego identyfikatora, podczas gdy URL i URN to konkretne implementacje adresów i nazw.
Mam nadzieję, że dla wszystkich wszystko jest jasne. Bądź mądry!
Percepcja każdego z nas jest indywidualna, dlatego - dyskutuj i czytaj dyskusje w komentarzach do artykułu, jest wiele ciekawych rzeczy.
Z reguły wielu webmasterów przesyła swoje witryny do hosta natychmiast po ich utworzeniu. Jednocześnie skupiają się głównie na poprawności znaczenia treści tekstowych, a nie na poprawności wewnętrznego kodu stron.
Walidacja witryny
Ale istnieją inne czynniki, które mogą i mają wpływ na pozycję witryny. A są to między innymi czynniki techniczne. Cóż, walidacja strony należy również do technicznych. Więc co to jest?
Jeśli w prostych słowach, weryfikacja witryny polega na sprawdzeniu kodu witryny pod kątem zgodności technicznej i błędów. Na przykład zapomniałeś użyć tagu zamykającego - /html. W najnowszym HTML5 wizualnie nic się nie zmieni. Jest to jednak błąd kodu.
Podczas pisania kodu możliwe są inne błędy. I znowu, nowoczesny język hiper-znaczników wiele wytrzyma. Na przykład „zapominając” zamykający tag /head. Znowu nie zobaczysz różnicy. Ale ona jest))
W rzeczywistości podczas pisania strony internetowej może być całkiem sporo błędów. Co gorsza, niektóre z tych błędów mogą również pojawić się wizualnie. Cóż, może klocki będą się unosić, może wyrównanie, a może coś innego. Potencjalne błędy, tysiące. I nie wszystkie są uderzające.
Jakie jest niebezpieczeństwo?
Cóż, wydaje się, no cóż, co w tym złego? Tak, trzeba powiedzieć, że często takie błędy nie są widoczne. A raczej niewidoczny dla ludzi. Ale strony naszej witryny mogą odwiedzać nie tylko ludzie, ale także roboty-pająki, które całkowicie skanują witrynę. A każdy błąd, który znajdą na stronie, przekazują na serwery wyszukiwarek, takich jak Yandex czy Google.
Z kolei wyszukiwarki, widząc, że witryna zawiera wiele błędów kodu, mogą stwierdzić, że jest ona zła. A to oznacza, że nie podniosą go w poszukiwaniach. Cóż, to już będzie oznaczać pożegnanie odwiedzających z wyszukiwania.
Tak, trzeba przyznać, że pewna pesymizacja serwisu spowodowana błędami walidacji jest dość rzadka. Ale jest to całkiem możliwe, co oznacza, że trzeba popracować nad walidacją. I co należy w tym celu zrobić? Oczywiście pierwszym krokiem jest znalezienie błędów.
Ale ponieważ ręcznie jest to bardzo czasochłonny i zawodny biznes, to do wyszukiwania błędów używają usługi specjalne, tak zwane „walidatory”.
Usługa sprawdzania poprawności znaczników walidatora.
Usługa ta sprawdza poprawność kodów HTML i XHTML, które są podstawą większości stron przy tworzeniu niemal każdej witryny oraz określa jej wewnętrzną strukturę. Dostęp do tej usługi walidatora można uzyskać, klikając link http://validator.w3.org
Ale jest tu warunek wstępny, który dotyczy również innych walidatorów: sprawdzana witryna lub jej sprawdzone strony muszą zostać przesłane do hostingu. W przeciwnym razie walidator nie „zna” adresu strony i nie będzie mógł niczego sprawdzić. Teraz możesz już zastanowić się, jak pracować na tym walidatorze.
Po wejściu na stronę tego serwisu zostanie wyświetlony cały jego funkcjonalny obraz. Ale większość tego, co jest przedstawione i napisane, nie dotyczy głównego czeku, a całą uwagę należy zwrócić tylko na okno wprowadzania adresu sprawdzanej strony:
Właśnie od tego musisz zacząć.
Właściwie sprawdzenie walidacji strony jest niezwykle proste, podobnie jak cały nasz śmiertelny świat: w okienku adresowym usługi należy wpisać adres strony, tj. jego adres URL, a następnie kliknij „Sprawdź”. Po tak prostej czynności walidator „zaciągnie się” na kilka sekund i wyda następujące polecenie:
Oznacza to, że w kodzie strony nie ma błędów i możesz być absolutnie spokojny.
Ale może być też taka niepożądana opcja:

To już jest gorsze i oznacza, że w wewnętrznym kodzie sprawdzanej strony są błędy. Nie jest to jednak wcale fatalne: wystarczy przewinąć poniższą stronę, a wszystkie błędy znalezione podczas procesu weryfikacji zostaną tam szczegółowo opisane.

Ponadto walidator nie tylko wyświetli listę znalezionych błędów, ale także pokaże dokładnie, w której linii kodu wewnętrznego te błędy się znajdują. Więc nie będziesz musiał ich długo szukać. Tutaj bez przesady możemy z całą stanowczością stwierdzić, że ten walidator działa doskonale.
Ale to nie wszystko: walidator nie tylko wskazuje lokalizację wykrytego błędu kodu, ale także daje dość kompletne zalecenia, jak wyeliminować te błędy. Oczywiście do tego nie musisz być leniwy i uważnie czytać wszystko, co napisano.
Jako krótki i uogólniony wniosek możemy powiedzieć:
- ta usługa sprawdzania poprawności działa świetnie i może bardzo szybko sprawdzić witrynę.
- Cóż, mały, ale bardzo fajny dodatek: walidacja witryny jest bezpłatna.
- Teraz możemy przejść do następnego kroku: jest to sprawdzenie kodu CSS.
Usługa walidacji CSS
Generalnie jest to druga funkcja powyższej usługi, ale jest „wyostrzona” nie do sprawdzania kodu HTML i XHTML, a konkretnie do sprawdzania poprawności kodu styl css znajduje się na zewnętrznym stole. Aby dostać się na stronę usługi, musisz kliknąć link http://jigsaw.w3.org/css-validator .
Nawiasem mówiąc, tutaj warto zwrócić uwagę na coś przyjemnego: sprawdzenie tej usługi jest całkowicie bezpłatne. Nie wyciągaj więc pieniędzy z portfela - niech leżą do odpowiedniego momentu. Przejdźmy jednak do metodologii pracy nad tą drugą usługą.
Ogólnie rzecz biorąc, cała praca nad walidatorem CSS jest absolutnie identyczna ze sprawdzaniem czystości kodu. Dlatego nie ma potrzeby dostarczania osobnego obrazu paska adresu walidatora. Tylko trochę niżej krótko rozważymy kolejność samego czeku i to wszystko.
W tym celu musisz pasek adresu zapisz adres URL tabeli CSS, np. „http://moja witryna/style.css”, a następnie kliknij przycisk z rosyjskim napisem „Sprawdź”. W związku z tym ten walidator również „zaciąga się” przez kilka sekund i daje pożądany wynik:
Oznacza to, że tabela CSS jest napisana poprawnie i nie znaleziono w niej błędów.
I tu też miła niespodzianka: jeśli przewiniesz stronę nieco niżej, to tam zostanie zapisany zoptymalizowany kod dla Twojej tabeli CSS, z którego wszystkie niepotrzebne napisy zostaną usunięte, a wszystkie tagi kodu zostaną ułożone w sekwencji który spełnia optymalne wymagania pracy wszystkich Wyszukiwarki. Pozostaje tylko skopiować ten doskonały przykładowy kod i wkleić go do tabeli CSS.
Całkiem możliwe, że coś takiego mogłoby się wydarzyć:

Oznacza to, że w kodzie CSS znaleziono pewne błędy, ale nie należy się tego w ogóle bać. Tuż pod czerwoną linią walidator powie dokładnie, który tag jest błędnie napisany. Pozostaje tylko znaleźć te tagi w arkuszu stylów i wprowadzić niezbędne poprawki.

I oczywiście po tym prześlij poprawiony arkusz stylów do hosta i jeśli pojawi się zielona linia, możesz z radością skopiować zoptymalizowany kod stylu tabeli CSS. Jest całkiem jasne, że wtedy najlepiej się zmienić stary kod na nowy i zoptymalizowany.
Krótkie podsumowanie.
Dwie najbardziej podstawowe i obowiązkowe kontrole walidacji witryny zostały omówione powyżej. Bez tych kontroli nie należy nawet otwierać indeksowania dla wyszukiwarek w pliku robots.txt W przeciwnym razie witryna może zostać zignorowana podczas indeksowania Wyszukiwarki i zostaną uznane za wadliwe z odpowiednimi sankcjami.
Aby temu zapobiec, musisz poświęcić tylko kilka minut, aby być całkowicie spokojnym i całkowicie pewnym stanu technicznego swojej witryny i wszystkich jej stron. Oczywiście wymagane są również dodatkowe sprawdzenia linków i kotwic, widoczności witryny na urządzeniach mobilnych oraz parametrów innych kodów. Tylko wtedy strona może być uznana za gotową do pełnego funkcjonowania i pomyślnego i szybki awans w TOP.
Z góry chciałbym powiedzieć, że wszystkie inne sprawdzenia są tak samo szybkie i proste jak te omówione powyżej - wystarczy dokładnie zapoznać się z procedurą pracy z walidatorem.
Dodano 19.04.2018
Typowe błędy walidacji podczas walidacji kodu HTML
Postanowiłem zaktualizować artykuł. Błędy HTML kody, które często można znaleźć w witrynach. W każdym razie miałem ich dużo)). Walidator podświetla błędy na żółto.
1) Błąd: Odwołanie do znaku nie zostało zakończone średnikiem.

Błąd: znak nie został przerwany średnikiem - odpowiednio należy go dodać.
2) Ostrzeżenie: w sekcji brakuje nagłówka. Rozważ użycie elementów h2-h6, aby dodać identyfikujące nagłówki do wszystkich sekcji.
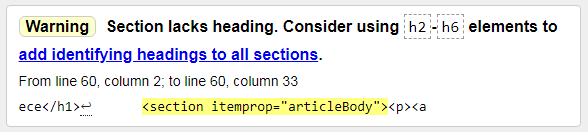
Ostrzeżenie: Ta sekcja nie ma tytułu. Rozważ użycie elementów h2-h6, aby dodać identyfikujące nagłówki do wszystkich sekcji. Tutaj wszystko jest jasne, musisz dodać przynajmniej jeden podtytuł. To nawet nie pomyłka, ale zalecenie.
3) Błąd: Element noindex nie jest dozwolony jako dziecko elementu p w tym kontekście.
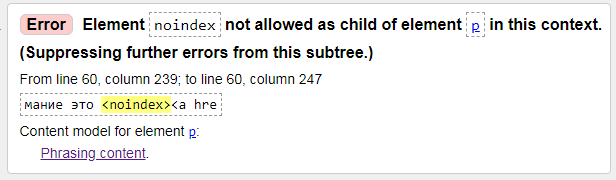
Błąd: element noindex jest niedozwolony jako element potomny element p w tym kontekście. (Pomiń dalsze błędy z tego poddrzewa.)
Rozwiązanie jest proste, musisz zakomentować tag noindex, widok będzie wyglądał tak:
4) Błąd: środkowy element jest przestarzały.
Błąd: tag "center" jest nieaktualny - należy go wymienić, jeśli mówimy o img, to możesz użyć atrybutu align. Jeśli coś innego jest wyśrodkowane, zastąp to div.
5) Element img musi mieć atrybut alt, z wyjątkiem pewnych

Błąd: Element img musi mieć atrybut alt - tutaj wszystko jest jasne, musisz dodać atrybut alt, nawet jeśli jest pusty, błąd zniknie.
6) Atrybut szerokości w elemencie td jest przestarzały. Zamiast tego użyj CSS.
Błąd: atrybut „width” w elemencie „td” jest przestarzały

7) Atrybut type jest zbędny dla zasobów javascript

Błąd: atrybut type nie jest wymagany w przypadku zasobów JavaScript. Rozwiązaniem jest po prostu usunięcie wszystkiego, co niepotrzebne i pozostawienie tylko znacznika „script”.
8) Atrybut align w elemencie img jest przestarzały.

Błąd: atrybut align w elemencie img jest przestarzały. Utwórz elementy div wyrównania obrazu.
Klasa ResourceBundle.Control zawiera zestaw metod zewnętrznych, które są wywoływane przez metodę ResourceBundle.getBundle() podczas wyszukiwania i ładowania pakietów. Po utworzeniu klasy Control możesz zmienić domyślne zachowanie ładowania i buforowania.
W takim przypadku musisz stworzyć implementację dwóch metod klasy Control: getFormats() i newBundle() . Za utrzymanie odpowiada metoda getFormats() Format XML, a newBundle() działa na pakiecie zasobów. Podstawowa klasa Control ma metody pomocnicze do konwertowania nazw zestawów podstawowych na rzeczywiste nazwy zasobów.
Ta implementacja klasy ResourceBundle.Control zawiera podklasę XMLResourceBundle . Ta podklasa służy do ładowania danych z Plik XML i używanie ich w metodzie ResourceBundle.
Poniżej znajduje się opis klasy Control oraz implementacja metody ResourceBundle:
importować java.io.*;
importować java.net.*;
import java.util.*;
Klasa publiczna XMLResourceBundleControl rozszerza ResourceBundle.Control(
prywatny statyczny String XML = "xml" ;
Lista publiczna getFormats(String baseName ) (
return Collections.singletonList(XML) ;
}
Public ResourceBundle nowyPakiet( Nazwa podstawowa ciągu znaków, ustawienia regionalne,
Format ciągu, program ładujący ClassLoader, przeładowanie logiczne)
rzuty IllegalAccessException, InstantiationException, IOException{
if ((baseName == null ) || (locale == null ) || (format == null )
|| (ładowacz == null )) (
wyrzuć nowy wyjątek NullPointerException();
}
Pakiet ResourceBundle = null ;
if (format.equals(XML))(
String nazwapakietu = toBundleName(nazwa bazy, ustawienia regionalne ) ;
String nazwa_zasobu = to nazwa_zasobu(nazwapakietu, format ) ;
adres URL= loader.getResource(Nazwa zasobu) ;
if (url != null ) (
Połączenie URLConnection = url.openConnection()
;
if (połączenie != null ) (
jeśli (przeładuj) (
połączenie.setUseCaches(false) ;
}
Strumień InputStream = connection.getInputStream()
;
if (strumień != null ) (
BufferedInputStream bis = nowy BufferedInputStream(
strumień);
pakiet = nowy XMLResourceBundle(bis) ;
bis.zamknij();
}
}
}
}
zwrot pakietu;
}
Prywatna statyczna klasa XMLResourceBundle rozszerza ResourceBundle(
rekwizyty własności prywatnej;
XMLResourceBundle (strumień InputStream) zgłasza wyjątek IOException(
rekwizyty = nowe Właściwości();
props.loadFromXML(strumień) ;
}
Obiekt chroniony handleGetObject (klawisz String) (
return props.getProperty(klucz) ;
}
Wyliczenie publiczne getKeys()(
Ustaw handleKeys = props.stringPropertyNames()
;
return Kolekcje enumeration (handleKeys ) ;
}
}
Public static void main(String args ) (
("Test2" ,
nowy XMLResourceBundleControl()) ;
strunowy= bundle.getString("Klucz Pomocy" ) ;
System.out.println ("HelpKey: " + string ) ;
}
}
Ta implementacja obejmuje trzyliniowy program testowy:
Pakiet ResourceBundle = ResourceBundle.getBundle(„Test2”, nowa funkcja XMLResourceBundleControl()) ;
String string = bundle.getString("Klucz Pomocy" ) ;
System.out.println ("HelpKey: " + string ) ;
Najciekawsza jest tutaj pierwsza linia. Musisz przekazać kontrolę do metody getBundle(). Następnie możesz korzystać z zestawu jak w każdym innym przypadku.
Poniżej znajduje się przykładowy plik XML Test2.xml:
http://java.sun.com/dtd/properties.dtd"
>
Rezultatem wykonania programu XMLResourceBundleControl będzie:
> java XMLResourceBundleControl HelpKey: Pomoc
Powyższa implementacja nie korzysta z metod getTimeToLive() i needsReload():
public long getTimeToLive( Nazwa podstawowa ciągu znaków, ustawienia regionalne)
public boolean needsReload( Nazwa podstawowa ciągu,
widownia,
format ciągu,
ładowarka klasy,
pakiet zasobów,
długi czas ładowania )
Metoda getTimeToLive() zwraca okres istnienia pakietów zasobów utworzonych za pomocą ResourceBundle.Control . Zestawy zasobów są buforowane, aby przyspieszyć proces ponownego ładowania. Tak więc po przeładowaniu zestaw znajdzie się on w pamięci podręcznej. Dodatnia wartość czasu życia określa w milisekundach, jak długo zestaw pozostanie w pamięci podręcznej bez ponownej walidacji. Domyślną wartością zwracaną przez metodę getTimeToLive() jest TTL_NO_EXPIRATION_CONTROL , która wyłącza sprawdzanie ważności pamięci podręcznej. Jeśli nie chcesz buforować zestawu, zwróć TTL_DONT_CACHE . Jeśli zwracana wartość wynosi 0, pakiet jest buforowany, ale jest sprawdzany za każdym razem, gdy wywoływana jest metoda getBundle(). Aby wyczyścić pamięć podręczną, wywołaj statyczną metodę clearCache() klasy ResourceBundle. Posiada opcjonalny argument ClassLoader, który umożliwia wyczyszczenie pamięci podręcznych utworzonych przez określony program ładujący.
Metoda needReload() określa, czy buforowany zestaw wymaga ponownego załadowania. Wartość true oznacza, że zestaw musi zostać ponownie załadowany, a false, że nie trzeba go ponownie wczytać. Możesz kontrolować, czy zestaw zasobów musi być ponownie załadowany, przeciążając metodę needReload(). Na przykład, jeśli chcesz, aby zestaw zasobów był zawsze ponownie ładowany, metoda needReload() powinna zawsze zwracać true . W takim przypadku metoda getTimeToLive() musi zawsze zwracać wartość 0. W przeciwnym razie zestaw będzie trwał dłużej niż oczekiwano.
Za zdobycie Dodatkowe informacje Informacje o ulepszeniach procesów internacjonalizacji Mustanga można znaleźć na blogu Johna Okonera, Sun Software Developer pod adresem