Ak ste vyvíjali PHP posledných pár rokov, pravdepodobne ste si vedomí problémov s týmto jazykom. Často môžete počuť, že je to roztrieštený jazyk, hackerský nástroj, že nemá skutočnú špecifikáciu a podobne. Realita je taká, že PHP sa v poslednom čase veľmi rozrástlo. Verzia PHP 5.4 ho priblížila k dokončeniu objektový model a poskytuje množstvo nových funkcií.
A to je všetko, samozrejme, dobré, ale čo frameworky? V PHP je ich veľa. Stačí začať hľadať a pochopíte, že nebudete mať dosť života na to, aby ste ich všetky študovali, pretože sa neustále objavujú nové rámce a v každom je vynájdené niečo vlastné. Ako to teda premeniť na niečo, čo neodcudzuje vývojárov a uľahčuje prenos funkcií z jedného rámca do druhého?
Čo je PHPFIG
PHP-FIG (PHP Framework Interop Group) je organizovaná skupina vývojárov, ktorých cieľom je nájsť spôsoby spolupráce viacerých rámcov.
Len si to predstavte: v súčasnosti podporujete projekt Zend Framework, ktorý potreboval modul nákupného košíka. Takýto modul ste už napísali pre predchádzajúci projekt, ktorý bol na Symphony. Prečo to nezopakovať? Našťastie ZendF aj Symphony sú súčasťou PHP-FIG, takže je možné importovať modul z jedného rámca do druhého. No nie je to skvelé?
Poďme zistiť, aké rámce sú zahrnuté v PHP-FIG
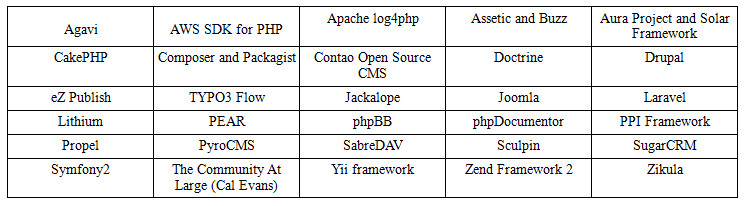
Členovia PHP-FIG
Každý vývojár môže pridať svoj rámec do zoznamu prispievateľov PHP-FIG. Za to však budete musieť zaplatiť určitú sumu, takže ak nemáte podporu komunity, pravdepodobne s tým nebudete súhlasiť. Je to preto, aby sa zabránilo registrácii miliónov mikrorámcov bez reputácie.
Súčasní členovia:
čo je PSR?
PSR (PHP Standards Recommendations) - štandardné odporúčania, výsledok PHP-FIG. Niektorí členovia skupiny navrhujú pravidlá pre každú PSR, iní hlasujú za tieto pravidlá alebo za ich zrušenie. Diskusia prebieha na Google Groups a PSR sady sú dostupné na oficiálnej webovej stránke PHP-FIG.
Pozrime sa na niektoré PSR:
Prvým krokom k zjednoteniu rámcov je mať spoločnú adresárovú štruktúru, a preto bol prijatý spoločný štandard automatického načítavania.
- Menný priestor (namespace) a trieda musia mať štruktúru \\(\)*.
- Každý menný priestor musí obsahovať medzeru najvyššej úrovne ("Názov dodávateľa").
- Každý menný priestor môže mať ľubovoľný počet úrovní.
- Každý oddeľovač menného priestoru sa pri načítaní skonvertuje na DIRECTORY_SEPARATOR.
- Každý znak „_“ v CLASS NAME sa skonvertuje na DIRECTORY_SEPARATOR.
- K plne kvalifikovanému priestoru názvov a triede sa pri načítaní pripojí ".php".
Príklad funkcie automatického načítania:

PSR-1 - Základný kódovací štandard
Tieto PSR regulujú základné štandardy, ktorých hlavnou myšlienkou je, že ak všetci vývojári používajú rovnaké štandardy, potom je možné bez problémov preniesť kód.
- Súbory by mali používať iba značky
- Súbory musia používať iba UTF-8 bez kódovania kusovníka.
- Názvy priestorov a triedy musia nasledovať PSR-0.
- Názvy tried musia byť deklarované v notácii StudlyCaps.
- Konštanty triedy musia byť deklarované veľkými písmenami oddelené podčiarkovníkom.
- Metódy musia byť deklarované v notácii camelCase.
PSR-2 - Sprievodca štýlom kódovania
Toto sú rozšírené inštrukcie pre PSR-1, ktoré popisujú pravidlá formátovania kódu.
- Kód musí byť v súlade s PSR-1.
- Namiesto tabulátorov by sa mali použiť 4 medzery.
- Dĺžka reťazca by nemala byť striktne obmedzená, odporúčaná dĺžka je do 80 znakov.
- Za deklaráciou priestoru názvov musí byť jeden prázdny riadok.
- Zátvorky pre triedy by sa mali otvárať na ďalšom riadku za deklaráciou a zatvárať za telom triedy (to isté pre metódy).
- Viditeľnosť metód a vlastností musí byť definovaná (verejná, súkromná).
- Otváracie konzoly pre riadiace konštrukcie musia byť na rovnakej línii, uzatváracie konzoly musia byť na ďalšej línii za telesom konštrukcie.
- Po otvorení zátvoriek metód riadiacej štruktúry a pred uzavretím zátvoriek sa neumiestňujú žiadne medzery.
PCR-3 - Logger Interface
PCR-3 reguluje protokolovanie, najmä deväť hlavných metód.
- LoggerInterface poskytuje 8 metód na zaznamenávanie ôsmich úrovní RFC 5424 (ladenie, upozornenie, varovanie, chyba, kritická, výstraha, núdzová situácia).
- Deviata metóda log() berie ako prvý parameter úroveň varovania. Volanie metódy s parametrom úrovne výstrahy musí vrátiť rovnaký výsledok ako volanie metódy určitej úrovne protokolu (log(ALERT) == alert()). Volanie metódy s nedefinovanou úrovňou varovania musí vyvolať výnimku Psr\Log\InvalidArgumentException.
Rovnako ako PSR-0, aj PSR-4 poskytuje vylepšené metódy automatického načítania
- Pojem "trieda" sa vzťahuje na triedy, rozhrania, vlastnosti a iné podobné štruktúry.
- Plne kvalifikovaný názov triedy má nasledujúci tvar: \
(\ )*\ - Pri načítavaní súboru, ktorý zodpovedá plne kvalifikovanému názvu triedy:
- Súvislý rad jedného alebo viacerých úvodných priestorov názvov, s výnimkou prvého oddeľovača priestoru názvov, v plne kvalifikovanom názve triedy sa zhoduje s aspoň jedným „koreňovým adresárom“.
- Názvy adresárov a podadresárov sa musia zhodovať s malými a veľkými písmenami v mennom priestore.
- Koniec úplného názvu triedy zodpovedá názvu súboru s koncovkou .php. Veľkosť písmen v názve súboru sa musí zhodovať s veľkosťou písmen v koncovke celého názvu triedy.
- Implementácia automatického načítavania nesmie vyvolávať výnimky, generovať chyby akejkoľvek úrovne a nesmie vrátiť hodnotu.
Záver
PHP-FIG mení spôsob písania rámcov, ale nie ich fungovanie. Klienti často vyžadujú, aby ste pracovali s existujúcim kódom v rámci alebo špecifikovali, s ktorým rámcom by ste mali na projekte pracovať. Odporúčania PSR v tomto smere výrazne uľahčujú život vývojárom, čo je skvelé!
PHP programovací jazyk prešiel dlhou cestou od nástroja na vytváranie osobných stránok k univerzálnemu jazyku. Dnes je nainštalovaný na miliónoch serverov po celom svete a používajú ho milióny vývojárov, ktorí vytvárajú širokú škálu projektov.
Ľahko sa učí a je mimoriadne obľúbený najmä medzi začiatočníkmi. Preto po vývoji jazyka nasledoval mohutný rozvoj komunity okolo neho. Obrovské množstvo skriptov, pre všetky príležitosti, rôzne knižnice, frameworky. Absencia jednotného dizajnu a štandardov kódovania viedla k vzniku obrovskej vrstvy informačných produktov postavených na vlastných princípoch vývojára tohto produktu. To sa prejavilo najmä pri práci s rôznymi PHP frameworky, ktorý dlho predstavoval uzavretý ekosystém, nekompatibilný s inými frameworkami, napriek tomu, že úlohy, ktoré riešia, sú často podobné.
V roku 2009 sa vývojári niekoľkých rámcov dohodli na vytvorení komunity PHP Framework Interop Group (PHP-FIG), ktorý by vypracoval odporúčania pre vývojárov. Je dôležité zdôrazniť, že nehovoríme o normy ISO, správnejšie je hovoriť o odporúčaniach. Ale keďže tí, ktorí tvorili php-obr komunita vývojárov predstavuje hlavné rámce, ich odporúčania majú vážnu váhu. podpora štandardy PSR (štandardné odporúčanie PHP). umožňuje interoperabilitu, ktorá uľahčuje a urýchľuje vývoj konečného produktu.
Celkovo je v čase písania tohto článku 17 noriem a 9 z nich je schválených, 8 je v štádiu návrhu, aktívne sa o nich diskutuje, 1 norma sa neodporúča používať.
Teraz prejdime priamo k popisu každého štandardu. Všimnite si, že tu nebudem podrobne rozoberať každý štandard, skôr malý úvod. Článok sa tiež bude zaoberať len tými PSR štandardy, ktoré sú oficiálne akceptované, t.j. sú v stave Prijaté.
PSR-1. Hlavný štandard kódovania
Predstavuje najvšeobecnejšie pravidlá, akými sú napríklad používanie PHP tagy, kódovanie súborov, oddelenie miesta deklarácie funkcie, triedy a miesta ich použitia, pomenovanie tried, metód.
PSR-2. Sprievodca štýlom kódu
Je pokračovaním prvého štandardu a upravuje používanie tabulátorov v kóde, zalomenia riadkov, maximálnu dĺžku riadkov kódu, pravidlá pre navrhovanie riadiacich štruktúr atď.
PSR-3. Rozhranie protokolovania.
Tento štandard je navrhnutý tak, aby umožňoval (logovanie) prihlasovanie do aplikácií napísaných v PHP.
PSR-4. Štandardné automatické načítanie
Toto je pravdepodobne najdôležitejší a potrebný štandard, ktorému sa budeme venovať v samostatnom podrobnom článku. Triedy, ktoré implementujú PSR-4, možno načítať pomocou jedného automatického zavádzača, čo umožňuje použitie častí a komponentov z jedného rámca alebo knižnice v iných projektoch.
PSR-6. rozhranie ukladania do vyrovnávacej pamäte
Ukladanie do vyrovnávacej pamäte sa používa na zlepšenie výkonu systému. A PSR-6 umožňuje štandardné ukladanie a získavanie údajov z vyrovnávacej pamäte pomocou jednotného rozhrania.
PSR-7. Rozhranie správy HTTP
Pri písaní viac či menej zložité stránky v PHP, takmer vždy musí pracovať s HTTP hlavičky. Samozrejme, jazyk PHP nám poskytuje hotové možnosti práce s nimi, ako napr superglobálne pole $_SERVER, funkcie hlavička(), setcookie() atď., ich manuálna analýza je však plná chýb a nie vždy je možné vziať do úvahy všetky nuansy práce s nimi. A tak, aby sa uľahčila práca vývojára, ako aj aby sa vytvorilo rozhranie interakcie s HTTP protokol táto norma bola prijatá. O tomto štandarde budem podrobnejšie rozprávať v niektorom z nasledujúcich článkov.
PSR-11. Rozhranie kontajnera
Pri písaní PHP programyČasto musíte použiť komponenty tretích strán. A aby sme sa v tomto lese závislostí nestratili, boli vynájdené rôzne metódy riadenia závislostí kódu, často navzájom nekompatibilné, čo tento štandard vedie k spoločnému menovateľovi.
PSR-13. Hypermediálne odkazy
Toto rozhranie je navrhnuté tak, aby uľahčilo vývoj a používanie rozhraní pre programovanie aplikácií ( API).
PSR-14. Jednoduché rozhranie pre ukladanie do vyrovnávacej pamäte
Ide o pokračovanie a zlepšenie štandardu PSR-6
Preto sme dnes zvážili PSR štandardy. Pre aktuálne informácie o stave noriem kontaktujte
16.09.2016Pokúsme sa zistiť, ako zlepšiť výkon aplikačného servera založeného na php-fpm, ako aj vytvoriť kontrolný zoznam na kontrolu konfigurácie procesu fpm.
V prvom rade stojí za to určiť umiestnenie konfiguračného súboru bazéna. Ak ste nainštalovali php-fpm zo systémového úložiska, potom konfigurácia fondu www sa bude nachádzať okolo /etc/php5/fpm/pool.d/www.conf . Ak používate vlastnú zostavu alebo iný OS (nie debian), mali by ste vyhľadať umiestnenie súboru v dokumentácii alebo ho špecifikovať ručne.
Pokúsme sa podrobnejšie zvážiť konfiguráciu.
Prechod na zásuvky UNIX
Pravdepodobne prvá vec, ktorú by ste mali venovať pozornosť, je spôsob, akým prechádzajú údaje z webového servera do vašich php procesov. To sa odráža v smernici počúvať:
počúvať = 127.0.0.1:9000
Ak je nastavená adresa:port, údaje prechádzajú zásobníkom TCP a to pravdepodobne nie je dobré. Ak existuje cesta k zásuvke, napríklad:
listen = /var/run/php5-fpm.sock
potom dáta prechádzajú cez unixovú zásuvku a túto časť môžete preskočiť.
Prečo sa stále oplatí prejsť na unixovú zásuvku? UDS (unix domain socket), na rozdiel od komunikácie cez TCP stack, má významné výhody:
- nevyžadujú prepínanie kontextu, UDS používa netisr)
- Datagram UDS zapísaný priamo do cieľového soketu
- odoslanie datagramu UDS vyžaduje menej operácií (žiadne kontrolné súčty, žiadne hlavičky TCP, žiadne smerovanie)
Priemerná latencia TCP: 6 us Priemerná latencia UDS: 2 us Priemerná latencia PIPE: 2 us Priemerná priepustnosť TCP: 253702 msg/s Priemerná priepustnosť UDS: 1733874 PIPE Priemerná priepustnosť: 1682796 msg/s
UDS má teda oneskorenie ~66% menej a priepustnosť v 7 krát viac TCP. Preto sa s najväčšou pravdepodobnosťou oplatí prejsť na UDS. V mojom prípade bude zásuvka umiestnená na /var/run/php5-fpm.sock .
; komentujte to - počúvajte = 127.0.0.1:9000 počúvajte = /var/run/php5-fpm.sock
Mali by ste sa tiež uistiť, že webový server (alebo akýkoľvek iný proces, ktorý potrebuje komunikovať) má prístup na čítanie/zápis do vášho soketu. Na to existujú nastavenia. počúvať.skupina a režim počúvania Najjednoduchší spôsob je spustiť oba procesy od toho istého používateľa alebo skupiny, v našom prípade php-fpm a webový server sa spustí so skupinou www-údaje:
listen.owner=www-data listen.group=www-data listen.mode=0660
Kontrola vybraného mechanizmu spracovania udalostí
Pre efektívnu prácu s I/O (vstup-výstup, súbor/zariadenie/zásuvkové deskriptory) sa oplatí skontrolovať, či je nastavenie správne udalosti.mechanizmus. Ak je php-fpm nainštalovaný zo systémového úložiska, s najväčšou pravdepodobnosťou je tam všetko v poriadku - buď nie je zadané (nainštalované automaticky), alebo je zadané správne.
Jeho význam závisí od operačného systému, pre ktorý je v dokumentácii náznak:
; - epoll (linux >= 2.5.44); - kqueue (FreeBSD >= 4.1, OpenBSD >= 2.9, NetBSD >= 2.0); - /dev/poll (Solaris >= 7) ; - prístav (Solaris >= 10)
Napríklad, ak pracujeme na modernej linuxovej distribúcii, potrebujeme epool:
udalosti.mechanizmus = epoll
Výber typu bazéna - dynamický / statický / na požiadanie
Tiež by ste mali venovať pozornosť nastaveniam procesného manažéra (pm). V skutočnosti ide o hlavný proces (hlavný proces), ktorý bude riadiť všetky podriadené (ktoré vykonávajú aplikačný kód) podľa určitej logiky, ktorá je v skutočnosti popísaná v konfiguračnom súbore.
K dispozícii sú celkom 3 schémy riadenia procesov:
- dynamický
- statické
- na požiadanie
Najjednoduchší je statické. Schéma jeho práce je nasledovná: spustiť pevný počet podriadených procesov a udržiavať ich v chode. Táto schéma práce nie je veľmi efektívna, pretože počet požiadaviek a ich zaťaženie sa môžu z času na čas meniť, ale počet podriadených procesov nie - vždy zaberajú určité množstvo pamäte RAM a nedokážu spracovať špičkové zaťaženie.
dynamický pool tento problém vyrieši, reguluje počet podriadených procesov na základe hodnôt konfiguračného súboru a mení ich nahor alebo nadol v závislosti od zaťaženia. Táto oblasť je najvhodnejšia pre aplikačný server, ktorý potrebuje rýchlu odozvu na požiadavku, prácu so špičkovým zaťažením a vyžaduje šetrenie zdrojov (znížením podriadených procesov pri nečinnosti).
na požiadanie bazén je veľmi podobný statické, ale nespustí podriadené procesy, keď sa spustí hlavný proces. Až keď príde prvá požiadavka, vytvorí sa prvý podriadený proces a po určitom časovom limite (špecifikovanom v konfigurácii) bude zabitý. Preto je relevantný pre servery s obmedzenými zdrojmi alebo logikou, ktorá nevyžaduje rýchlu reakciu.
Úniky pamäte a zabijak OOM
Mali by ste venovať pozornosť kvalite aplikácií, ktoré budú spúšťané podriadenými procesmi. Ak kvalita aplikácie nie je príliš vysoká alebo sa používa veľa knižníc tretích strán, musíte myslieť na možné úniky pamäte a nastaviť hodnoty na tieto premenné:
- pm.max_requests
- request_terminate_timeout
pm.max_requests toto je maximálny počet požiadaviek, ktoré dieťa spracuje pred zabitím. Násilným zabitím procesu sa vyhnete situácii, v ktorej sa pamäť podriadeného procesu „nafúkne“ kvôli únikom (pretože proces pokračuje v práci po požiadavke za požiadavkou). Na druhej strane príliš malá hodnota bude mať za následok časté reštarty, čo vedie k strate výkonu. Stojí za to začať s hodnotou 1 000 a potom túto hodnotu znížiť alebo zvýšiť.
request_terminate_timeout nastavuje maximálny čas, počas ktorého môže podradený proces bežať, kým bude zabitý. Tým sa zabráni dlhým dotazom, ak sa z nejakého dôvodu zmenila hodnota max_execution_time v nastaveniach tlmočníka. Hodnota by mala byť nastavená na základe logiky spracovávaných žiadostí, povedzme 60. roky(1 minúta).
Konfigurácia dynamického fondu
Pre hlavný aplikačný server sa kvôli zjavným výhodám často vyberá dynamický fond. Jeho činnosť je popísaná nasledujúcimi nastaveniami:
- pm.max_children- maximálny počet podriadených procesov
- pm.start_servers- počet procesov pri spustení
- pm.min_spare_servers- minimálny počet procesov čakajúcich na pripojenie (požiadavky na spracovanie)
- pm.max_spare_servers- maximálny počet procesov čakajúcich na pripojenie (požiadavky na spracovanie)
Pre správne nastavenie týchto hodnôt je potrebné zvážiť:
- koľko pamäte v priemere spotrebuje detský proces
- dostupnej RAM
Priemernú hodnotu pamäte na proces php-fpm v už spustenej aplikácii môžete zistiť pomocou plánovača:
# ps -ylC php-fpm --sort:rss S UID PID PPID C PRI NI RSS SZ ČAS VOĽBY CMD S 0 1445 1 0 80 0 9552 42588 ep_pol ? 00:00:00 php5-fpm
Potrebujeme priemernú hodnotu v stĺpci RSS (veľkosť rezidentnej pamäte v kilobajtoch). V mojom prípade je to ~ 20 Mb. V prípade, že aplikácie nie sú zaťažené, môžete použiť Apache Benchmark na vytvorenie najjednoduchšieho zaťaženia php-fpm.
Množstvo celkovej / dostupnej / použitej pamäte je možné zobraziť pomocou zadarmo:
# voľný -m celkom využitý voľný ... Pamäť: 4096 600 3496
Celkový maximálny počet procesov = (celkový počet RAM - (použitý RAM + vyrovnávacia pamäť)) / (pamäť na proces php) Celková pamäť RAM: 4 GB použitá pamäť RAM: 1 000 MB bezpečnostná vyrovnávacia pamäť: 400 MB pamäte na podriadený proces php-fpm (priemer): 30 MB Maximálny možný počet procesy = (4096 - (1000 + 400)) / 30 = 89 Párne číslo: 89 zaokrúhlené nadol na 80
Hodnotu zostávajúcich direktív je možné nastaviť na základe očakávaného zaťaženia aplikácie a tiež vziať do úvahy, čo ešte server robí okrem php-fpm (povedzme, že DBMS tiež vyžaduje zdroje). Ak je na serveri veľa úloh, oplatí sa znížiť počet počiatočných aj maximálnych procesov.
Napríklad, vezmime do úvahy, že na serveri sú 2 fondy www1 a www2 (napríklad 2 webové zdroje), potom môže konfigurácia každého z nich vyzerať takto:
pm.max_children = 40 ; 80 / 14 pm.start_servers = 15 pm.min_spare_servers = 15 pm.max_spare_servers = 25
1. GROUP PODĽA jedného kľúča
Táto funkcia funguje ako GROUP BY pre pole, ale s jedným dôležitým obmedzením: Je možný iba jeden "stĺpec" zoskupenia ($identifikátor) .
Funkcia arrayUniqueByIdentifier(pole $pole, reťazec $identifikátor) ( $ids = pole_stĺpec($pole, $identifikátor); $ids = pole_unique($ids); $pole = pole_filter($pole, funkcia ($kľúč, $hodnota ) použite ($ids) ( return in_array($value, array_keys($ids)); ), ARRAY_FILTER_USE_BOTH); return $array; )
2. Detekcia jedinečných riadkov pre tabuľku (dvojrozmerné pole)
Táto funkcia slúži na filtrovanie „riadkov“. Ak povieme, že dvojrozmerné pole je tabuľka, potom každý jeho prvok je riadok. Takže pomocou tejto funkcie môžeme odstrániť duplicitné riadky. Dva riadky (prvky prvej dimenzie) sú rovnaké, ak sú všetky ich stĺpce (prvky druhej dimenzie) rovnaké. Pre porovnanie hodnôt "stĺpca" platí: Ak je hodnota jednoduchého typu, na porovnanie sa použije samotná hodnota; inak sa použije jeho typ (pole , objekt , zdroj , neznámy typ).
Stratégia je jednoduchá: Vytvorte z pôvodného poľa plytké pole, kde prvky sú zložené do „stĺpcov“ pôvodného poľa; potom naň aplikujte array_unique(...); a ako posledný použiť zistené ID na filtrovanie pôvodného poľa.
Funkcia arrayUniqueByRow(pole $table = , string $implodeSeparator) ( $elementStrings = ; foreach ($tabuľka ako $riadok) ( // Aby ste sa vyhli upozorneniam ako "Konverzia poľa na reťazec". $elementPreparedForImplode = array_map(funkcia ($field) ( $valueType = gettype($field); $simpleTypes = ["boolean", "celé číslo", "double", "float", "string", "NULL"]; $field = in_array($valueType, $simpleTypes) ? $field: $valueType; return $field; ), $riadok); $elementStrings = implode($implodeSeparator, $elementPreparedForImplode); ) $elementStringsUnique = array_unique($elementStrings); $table = array_intersect_key($table, $elementStringsUnique); vrátiť $tabuľku ;)
Je tiež možné zlepšiť porovnávanie, zistiť triedu hodnoty "stĺpca", ak je jej typ objekt.
$implodeSeparator by mal byť viac-menej zložitý, z.B. spl_object_hash($this) .
3. Detekcia riadkov so stĺpcami s jedinečným identifikátorom pre tabuľku (dvojrozmerné pole)
Toto riešenie sa spolieha na 2. Teraz už nemusí byť celý „riadok“ jedinečný. Dva „riadky“ (prvky prvej dimenzie) sú teraz rovnaké, ak všetky relevantné"polia" (prvky druhej dimenzie) jedného "riadku" sa rovnajú príslušným "poliam" (prvky s rovnakým kľúčom).
„Relevantné“ „polia“ sú „polia“ (prvky druhej dimenzie), ktoré majú kľúč, ktorý sa rovná jednému z prvkov odovzdaných „identifikátorov“.
Funkcia arrayUniqueByMultipleIdentifiers(pole $tabuľka, pole $identifikátory, reťazec $implodeSeparator = null) ( $arrayForMakingUniqueByRow = $removeArrayColumns($tabuľka, $identifiers, true); $arrayUniqueByRow = $arrayUniqueByRayRow = $arrayUniqueByult_RowniqueniqueniifierSeparow = pole ($table, $arrayUniqueByRow); return $arrayUniqueByMultipleIdentifiers; ) function removeArrayColumns(pole $tabuľka, pole $columnNames, bool $isWhitelist = false) (foreach ($tabuľka ako $rowKey => $row) ( if (is_array( $row )) ( if ($isWhitelist) ( foreach ($row as $fieldName => $fieldValue) (neif (!in_array($fieldName, $columnNames)) ( unset($table[$rowKey][$fieldName ]); ) ) ) else ( foreach ($riadok ako $fieldName => $fieldValue) (neak (in_array($fieldName, $columnNames)) ( unset($table[$rowKey][$fieldName]); ) ) ) ) ) vrátiť $ tabuľku; )
Keďže vývoj technológie viedol k tomu, že každý programátor má teraz svoj vlastný počítač, ako vedľajší efekt máme tisíce rôznych knižníc, frameworkov, služieb, API atď. pre všetky príležitosti. Keď však príde tento prípad života, vyvstáva problém - na čo ich použiť a čo robiť, ak to úplne nesedí - prepíšte, napíšte svoje vlastné od začiatku alebo priskrutkujte niekoľko riešení pre rôzne prípady použitia.
Myslím, že mnohí si všimli, že tvorba projektu často nespočíva ani tak v programovaní, ako v písaní kódu na integráciu niekoľkých hotových riešení. Niekedy sa takéto kombinácie zmenia na nové riešenia, ktoré možno opakovane použiť pri následných problémoch.
Prejdime ku konkrétnej „bežiacej“ úlohe – objektovej vrstve pre prácu s databázami v PHP. Existuje veľa riešení, od PDO až po viacúrovňové (a podľa môjho názoru nie úplne vhodné v PHP) ORM motory.
Väčšina týchto riešení migrovala na PHP z iných platforiem. Ale často autori neberú do úvahy vlastnosti PHP, čo by výrazne zjednodušilo písanie aj používanie portable konštruktov.
Jednou z bežných architektúr pre túto triedu úloh je vzor Active Record. Podľa tohto vzoru sú postavené najmä takzvané entity, ktoré sa v tej či onej forme používajú na mnohých platformách, od perzistentných fazulí v EJB3 po EF v .NET.
Vytvorme teda podobnú konštrukciu pre PHP. Spojme dve super veci – hotovú knižnicu ADODB a slabo typizované a dynamické vlastnosti objektov v jazyku PHP.
Jednou z mnohých funkcií ADODB je takzvané automatické generovanie SQL dotazov na vkladanie (INSERT) a aktualizáciu (UPDATE) záznamov na základe asociatívnych polí s údajmi.
V skutočnosti nie je nič vojenské, čo by sa dalo vziať do poľa, kde kľúče sú názvy polí a hodnoty sú údaje a generujú reťazec dotazu SQL. Ale ADODB to robí inteligentnejšie. Dotaz je zostavený na základe štruktúry tabuľky, ktorá je predbežne načítaná z databázovej schémy. Výsledkom je, že po prvé sa do sql dostanú iba existujúce polia a nie všetko v rade a po druhé sa berie do úvahy typ poľa - pri reťazcoch sa pridávajú úvodzovky, formáty dátumu môžu byť vytvorené na základe časovej pečiatky, ak to ADODB vidí namiesto reťazca v prenášanej hodnote atď.
Teraz poďme zo strany PHP.
Predstavte si takúto triedu (zjednodušene).
Entita triedy( chránené $polia = pole(); verejná konečná funkcia __set($meno, $hodnota) ( $this->fields[$name] = $hodnota; ) verejná konečná funkcia __get($name) ( return $ this- >fields[$name]; ) )
Odovzdaním interného poľa do knižnice ADODB dokážeme automaticky generovať SQL dotazy na aktualizáciu záznamu v databáze týmto objektom.Súčasne ťažkopádne konštrukcie mapovania polí databázových tabuliek na polia objektu entity na báze XML a podobné nie sú potrebné. Je len potrebné, aby sa názov poľa zhodoval s vlastnosťou objektu. Keďže na spôsobe pomenovania polí v databáze a polí objektu nezáleží pre počítač, nie je dôvod, aby sa nezhodovali.
Poďme si ukázať, ako to funguje vo finálnej verzii.
Kód dokončenej triedy sa nachádza na Gist . Ide o abstraktnú triedu, ktorá obsahuje minimum potrebné na prácu s databázou. Podotýkam, že táto trieda je zjednodušenou verziou riešenia vypracovaného na niekoľkých desiatkach projektov.
Predstavme si, že máme takúto tabuľku:
CREATE TABLE `users` (`username` varchar(255) , `created` date , `user_id` int(11) NOT NULL AUTO_INCREMENT, PRIMARY KEY (`user_id`))
Na type databázy nezáleží - ADODB poskytuje prenosnosť pre všetky bežné databázové servery.
Vytvorme triedu entity User, založenú na triede Entity
/** * @table=users * @keyfield=user_id */ class Používateľ rozširuje Entitu( )
Vlastne, to je všetko.
Používa sa jednoducho:
$user = novy User(); $user->username="Vasya Pupkin"; $user->vytvoreny=cas(); $user->save(); //ulož do úložiska //načítaj znova $thesameuser = User::load($user->user_id); echo $thesameuser ->username;
Tabuľku a pole kľúča špecifikujeme v pseudoanotáciách.
Môžeme tiež špecifikovať pohľad (napríklad view =usersview), ak sa entita, ako sa to často stáva, vyberie na základe jej tabuľky s pripojenými alebo vypočítanými poľami. V tomto prípade sa údaje vyberú zo zobrazenia a tabuľka sa aktualizuje. Tí, ktorým sa takéto anotácie nepáčia, môžu prepísať metódu getMetatada() a zadať parametre tabuľky vo vrátenom poli.
Čo je ešte užitočné na triede Entity v tejto implementácii?
Môžeme napríklad prepísať metódu init(), ktorá sa volá po vytvorení inštancie entity, aby sa inicializoval predvolený dátum vytvorenia.
Alebo preťažte metódu afterLoad(), ktorá sa automaticky volá po načítaní entity z databázy, aby ste previedli dátum na časovú pečiatku pre ďalšie pohodlnejšie použitie.
V dôsledku toho získame nie oveľa zložitejšiu štruktúru.
/** * @table=users * @view=usersview * @keyfield=user_id */ class Používateľ rozširuje Entitu( chránená funkcia init() ( $this->created = time(); ) chránená funkcia afterLoad() ( $this ->vytvorené = strtotime($this->vytvorené); ) )
Môžete tiež preťažiť metódy beforeSave a beforeDelete a ďalšie udalosti životného cyklu, kde môžete napríklad vykonať overenie pred uložením alebo iné akcie - napríklad odstrániť obrázky z nahrávania, keď je používateľ odstránený.
Načítame zoznam entít podľa kritéria (v skutočnosti podmienky pre KDE).
$users = User::load("používateľské meno ako "Pupkin" ");
Trieda Entity vám tiež umožňuje spustiť ľubovoľný, takpovediac „natívny“ dotaz SQL. Chceme napríklad vrátiť zoznam používateľov s niektorými zoskupeniami podľa štatistík. Nezáleží na tom, ktoré konkrétne polia sa vrátia (hlavná vec je, že existuje user_id, ak je potrebná ďalšia manipulácia s entitou), stačí poznať ich mená, aby ste mali prístup k vybraným poliam. Pri ukladaní entity, ako je zrejmé z vyššie uvedeného, tiež nie je potrebné vypĺňať všetky polia, ktoré sa budú v objekte entity nachádzať, prejdú do databázy. To znamená, že nepotrebujeme vytvárať ďalšie triedy pre svojvoľné výbery. Približne ako anonymné štruktúry pri načítavaní v EF, len tu ide o rovnakú triedu entity so všetkými metódami obchodnej logiky.
Presne povedané, vyššie uvedené metódy na získanie zoznamov sú trochu mimo vzoru AR. V podstate sú to továrenské metódy. Ale ako starý muž z Ockhamu odkázal, nebudeme produkovať entity nad rámec toho, čo je nevyhnutné, a ohradiť samostatného manažéra entít alebo niečo podobné.
Všimnite si, že vyššie uvedené sú len triedy PHP a môžu sa rozširovať a upravovať, ako chcete, pridaním vlastností a metód obchodnej logiky do entity (alebo základnej triedy Entity). To znamená, že nezískavame len kópiu riadku databázovej tabuľky, ale obchodný subjekt ako súčasť objektovej architektúry aplikácie.
Kto z toho môže mať prospech? Samozrejme, nie pre vývojárov, ktorí nie sú napumpovaní, ktorí veria, že používanie niečoho jednoduchšieho ako doktrína nie je solídne, a nie pre perfekcionistov, ktorí sú si istí, že ak riešenie nevytiahne miliardu DB prístupov za sekundu, potom je to nie riešenie. Súdiac podľa fór, mnoho bežných vývojárov pracujúcich na bežných (z toho 99,9%) projektoch skôr či neskôr čelí problému nájsť jednoduchý a pohodlný objektový spôsob prístupu k databáze. Stretávajú sa však so skutočnosťou, že väčšina riešení je buď neprimerane vymyslená, alebo je súčasťou rámca.
P.S. Urobil rozhodnutie z rámca ako samostatný projekt