…Although the syntax of HTML is relatively simple to learn,…there"s, still a lot of elements, attributes and…other concepts that you"re going to need to learn and keep track of.…While this course is intended to introduce you to the essentials of HTML, it"s…really not designed to teach you every single element and attribute available.…So with that in mind, I want to give you a couple of online HTML resources,…that can really help you as you begin learning HTML, and…can serve as valuable references later on, as you"re authoring your own pages.…Now we"re going to start, at the specifications themselves.…
And this is something, two documents that you should definitely have bookmarked.…So, this is the W3Cs version of HTML5.…You can see they have a latest Publisher Version.…You can go see the Editor"s Draft,…if you want to see what"s coming down, down the pipe.…And, this is pretty large.…If I scroll down, you can see that here"s just the Table of Contents.…And I"m not even going to scroll through all of them.…
Resume Transcript Auto-Scroll
Updated
3/30/2017Released
3/16/2015HTML is the programming language that powers the web. And like any language, once you master it, you can begin to create your own content, whether that"s simple websites or complex web applications. This course provides an in-depth look at the essentials: the syntax of HTML and best practices for writing and editing your code. Senior staff author James Williamson reviews the structure of a typical HTML document, and shows how to section pages and format your content with HTML. Plus, learn how to create links and lists, and find out how HTML works with CSS and JavaScript to create rich, engaging user experiences. So open a text editor, watch these videos, and begin learning to author HTML the right way.
Topics include:
- Why is HTML important?
- Exploring an HTML document
- Formatting content
- Displaying images
- Using nav, article, and div elements
- Linking to pages and downloadable content
- Creating lists
- Controlling styling (fonts, colors, and more)
- Writing basic scripts
: всегда хотел это понять, но значимость его была настолько мала, что всегда находился повод этого не делать:)
А вы задавались вопросом: URL — что это ?
Всегда с таким сталкиваюсь, но до сих пор не желал понять в чем различие между терминами URI, URL, URN, а тут вдруг постик (к сожалению, он уже канул в Лету), решил - и сам почитаю, и другим поведаю, хотя, как сказано выше, от этого ничего не изменится, но люблю я иногда побуквоедствовать, так-что читайте толковый переводец:
Вы когда-нибудь обращали внимание на адресную строку в Вашем браузере? Что это? URI, URL или URN? Многие из нас не делают различий между URI, URL, URN, а кое-кто даже и не слышал терминов URI и URN, все просто пользуются термином URL. Давайте вместе попытаемся разобраться в этом.
Расшифровка аббревиатур
URI - Uniform Resource Identifier (унифицированный идентификатор
ресурса)
URL - Uniform Resource Locator (унифицированный определитель местонахождения
ресурса)
URN - Unifrorm Resource Name (унифицированное имя
ресурса)
Внимание, здесь в мелочах кроется истина, но пока ничего не понятно, какая-то каша. Едем дальше.
Определение
URI: Обозначает имя и адрес ресурса в сети. Как правило, делится на URL и URN, поэтому URL и URN это составляющие URI.
URL: Адрес некоторого ресурса в веб. URL определяет местонахождение ресурса и способ обращения к нему.
URN: Имя некоторого ресурса в веб. Смысл URN в том, что он определяет только название конкретного предмета, который может находится во множестве конкретных мест.
Нет ничего лучше, чем конкретный пример
URI = http://сайт/2009/09/uri-url-urn.html
URL = http://сайт
URN = /2009/09/uri-url-urn.html
Подведем итоги
URI это концепция абстрактного идентификатора, тогда как URL и URN конкретная реализация - адреса и имени.
Надеюсь всем всё понятно. Будьте грамотны!
Восприятие каждого из нас индивидуально, поэтому — спорьте и читайте обсуждения в комментариях к статье, там много чего интересного.
Как правило, многие вебмастера загружают свои сайты на хост сразу-же после их создания. При этом они большей частью ориентируются на правильность составления смысла текстового содержания, чем на правильность внутреннего кода страниц.
Валидация сайта
Но есть и другие факторы, которые могут и влияют на позиции сайта. И к ним относятся, в том числе, и технические факторы. Ну а к техническим относятся и валидация сайта. Так что же это такое?
Если простыми словами, то валидация сайта — это проверка кода сайта на техническое соответствие и ошибки. Ну например, вы забыли использовать закрывающий тег — /html. В последнем HTML5, визуально ничего не поменяется. Однако, это ошибка кода.
При написании кода, возможны и другие ошибки. И опять-таки, современный язык гипер разметки «стерпит» многое. Например, «забытие» закрывающего тега /head. И снова вы не увидите разницу. Но она есть))
На самом деле, при написании сайта, ошибок может быть довольно много. И что хуже, некоторые из этих ошибок, могут проявиться и визуально. Ну может блоки поплывут, может выравнивание, а может и еще что-то. Потенциальных ошибок, тысячи. И далеко не все из них, бросаются в глаза.
В чем опасность?
Ну казалось-бы, ну и что тут такого? Да, нужно сказать, что зачастую такие ошибки не видимы. Точнее, невидимы человеком. А ведь страницы нашего сайта могут посетить не только люди, но и поисковые пауки, которые полностью просматривают сайт. И каждую ошибку, которую они находят на сайте, они передают на сервера поисковиков, таких как Яндекс или Гугл.
А поисковики, в свою очередь, видя что на сайте много ошибок кода, вполне могут сделать вывод о том, что сайт плохой. И значит, не будут поднимать его в поиске. Ну а это уже будет означать, что прощай посетители с поиска.
Да, надо признать, определенная пессимизация сайта из-за ошибок валидации, это довольно редкое явление. Но это вполне возможно, а значит, над валидацией обязательно нужно работать. А что для этого нужно сделать? Понятное дело, вначале ошибки нужно найти.
Но поскольку вручную это очень трудоёмкое и ненадежное дело, то для поиска ошибок, используются специальные сервисы, так называемые «Валидаторы».
Валидатор Markup Validation Service.
Этот сервис проверяет правильность кодов HTML и XHTML, которые являются основой большей части страниц при создании практически любого сайта и определяют его внутреннюю структуру. На этот сервис валидатора можно попасть, если пройти по ссылке http://validator.w3.org
Но здесь есть обязательное условие, которое также относится и к другим валидаторам: проверяемый сайт или его проверяемые страницы должны быть закачаны на хостинг. В противном случае, валидатор не будет «знать» адрес сайта и не сможет ничего проверить. Вот сейчас можно уже рассмотреть, как работать на этом валидаторе.
После захода на страницу этого сервиса, отобразиться вся его функциональная картинка. Но большая часть изображённого и написанного к основной проверке не относится и всё своё внимание надо обратить только на окно ввода адреса проверяемой страницы:
Вот именно с него и надо начинать.
Вообще-то, проверка валидации сайта чрезвычайно проста, как и весь наш бренный мир: в адресном окне сервиса надо написать адрес сайта, т.е. его URL и затем нажать «Check». После такого простого действия, валидатор «попыхтит» несколько секунд и выдаст следующее:
Это означает, что никаких ошибок в коде страницы нет и Вы можете быть абсолютно спокойны.
Но также может быть и такой нежелательный вариант:

Это уже похуже и означает, что во внутреннем коде проверяемой страницы есть какие-то ошибки. Однако, это совсем не смертельно: просто надо прокрутить страницу ниже и там подробно будут написаны все найденные ошибки в процессе проверки.

Кроме того, валидатор не только перечислит найденные ошибки, но и точно покажет, на какой строке внутреннего кода эти ошибки расположены. Так что долго их искать не придётся. Здесь, ничего не преувеличивая, можно твёрдо сказать, что этот валидор работает прекрасно.
Но это ещё не всё: валидатор не только указывает местоположение обнаруженной ошибки кода, но и даёт достаточно полные рекомендации, каким образом можно устранить эти ошибки. Конечно, для этого не надо лениться и внимательно прочитать всё написанное.
В качестве краткого и обобщенного вывода, можно сказать следующее:
- данный сервис валидатора работает прекрасно и может очень быстро провести проверку сайта.
- Ну и небольшое, но очень приятное дополнение: валидация сайта производиться бесплатно.
- Сейчас можно перейти к следующему этапу: это проверка кода CSS.
Валидатор CSS Validation Service
В общем это вторая функция вышеописанного сервиса, но она «заточена» не для проверки кода HTML и XHTML, а конкретно для проверки правильности кода стиля CSS, расположенного на внешней таблице. А чтобы попасть на страницу сервиса, надо пройти по ссылке http://jigsaw.w3.org/css-validator .
Кстати, здесь стоит отметить нечто приятное: проверка на этом сервисе абсолютно бесплатна. Так что не надо вытаскивать деньги из своего кошелька — пусть они лежат до нужного момента. Однако перейдём к методике работы на этом втором сервисе.
В общем-то вся работа на валидаторе CSS абсолютно идентична проверке на чистоту кода. Поэтому, приводить отдельную картинку адресной строки валидатора нет необходимости. Просто чуть ниже кратко рассмотрим непосредственно порядок самой проверки и всё.
Для этого надо в адресной строке записать URL таблицы CSS, типа «http://мой сайт/style.css» и после этого нажать кнопку с русской надписью «Проверить». Соответственно, этот валидатор тоже несколько секунд «попыхтит» и выдаст искомый результат:
Это значит, что таблица CSS написана правильно и никаких ошибок в ней не обнаружено.
И здесь также есть приятная неожиданность: если прокрутить страницу несколько ниже, то там будет написан оптимизированный код для Вашей таблицы CSS, из которого убраны все лишние надписи и все теги кода будут расставлены в той последовательности, которая соответствует оптимальным рабочим требованиям всех поисковых систем. Остаётся только скопировать этот идеальный образец кода и вставить его в таблицу CSS.
Вполне может быть, что случиться и такой вариант:

Это значит, что обнаружены какие-то ошибки в коде CSS, но пугаться этого совсем не стоит. Сразу внизу под этой красной строкой, валидатор точно укажет, какой тег написан неправильно. Остаётся только в таблице стиля найти эти теги и сделать нужные исправления.

И конечно, после этого закачать исправленную таблицу стиля на хост и при наличии зелёной строки можно с удовольствием скопировать оптимизированный код стиля таблицы CSS. Вполне понятно, что затем лучше всего поменять старый код на новый и оптимизированный.
Краткое резюме.
Выше были рассмотрены две самых основных и обязательных проверки валидации сайта. Без этих проверок даже не стоит открывать индексацию для поисковых систем в robots.txt В противном случае, сайт может быть проигнорирован для индексации поисковыми машинами и будет считаться неисправным с соответствующими санкциями.
Чтобы этого не произошло, надо затратить всего несколько минут, чтобы быть абсолютно спокойным и полностью уверенным в техническом состоянии своего сайта и всех его страниц. Конечно, необходимо ещё произвести дополнительные проверки ссылок и анкоров, видимости сайта на мобильных устройствах и параметры других кодов. Только тогда сайт можно считать готовым для его полного функционирования и для удачного и быстрого продвижению в ТОП.
Заранее хочется сказать, что все остальные проверки проходят также быстро и просто, как и рассмотренные выше — надо только внимательно прочитать порядок работы с валидатором.
Добавлено 19.04.2018г.
Распространенные ошибки валидности при проверке html кода
Решил дополнить статью ошибками HTML кода, которые часто встречаются на сайтах. Во всяком случае у меня их было много)). Сами ошибки валидатор подсвечивает желтым цветом.
1) Error: Character reference was not terminated by a semicolon.

Ошибка: символ не был прерван точкой с запятой — соответственно надо добавить.
2) Warning: Section lacks heading. Consider using h2-h6 elements to add identifying headings to all sections.
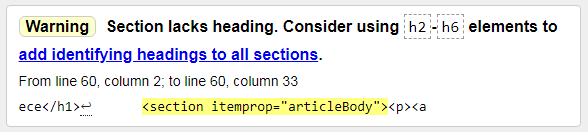
Предупреждение: Раздел не имеет заголовка. Рассмотрите возможность использования элементов h2-h6 для добавления идентифицирующих заголовков ко всем разделам. Тут все понятно, надо добавить хотя бы один подзаголовок. Это даже не ошибка, а рекомендация.
3) Error: Element noindex not allowed as child of element p in this context.
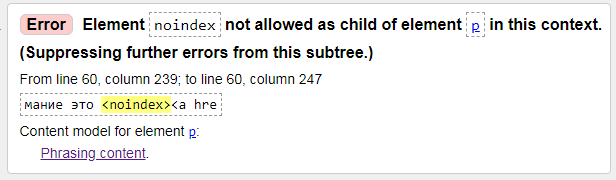
Ошибка: элемент noindex не разрешен как дочерний элемент элемента p в этом контексте. (Подавление дальнейших ошибок из этого поддерева.)
Решение простое, надо закомментировать тег ноиндекс, вид будет таким:
4) Error: The center element is obsolete.
Ошибка: тег «center» устарел — надо заменить, если речь про img то можно использовать атрибут align. Если что-то другое центрировали, то заменить на div.
5) An img element must have an alt attribute, except under certain

Ошибка: Элемент img должен иметь атрибут alt -тут все понятно, надо добавить атрибут альт, даже если он будет незаполненный, то ошибка уйдет.
6) The width attribute on the td element is obsolete. Use CSS instead.
Ошибка: Атрибут «width» на элементе «td» устарел

7) The type attribute is unnecessary for javascript resources

Ошибка: атрибут type не нужен для ресурсов javascript. Решение просто удаляем все лишнее и оставляем только тег «script».
8) The align attribute on the img element is obsolete.

Ошибка: Атрибут align для элемента img устарел. Сделайте выравнивание изображений дивами.
В классе ResourceBundle.Control существует набор внешних методов, вызываемых методом ResourceBundle.getBundle() во время поиска и загрузки наборов. Создав свой класс Control , вы можете изменить поведение по-умолчанию для загрузки и кеширования.
В данном случае вам необходимо создать реализацию двух методов класса Control: getFormats() и newBundle() . Метод getFormats() отвечает за поддержку формата XML, а newBundle() работает с набором ресурсов. В базовом классе Control существуют вспомогательные методы, предназначенные для преобразования основных имен наборов в действительные имена ресурсов.
В данную реализацию класса ResourceBundle.Control включен подкласс XMLResourceBundle . Данный подкласс используется для загрузки данных из XML файла и использовании их в методе ResourceBundle .
Ниже приводится описание класса Control и реализация метода ResourceBundle:
import
java.io.*;
import
java.net.*;
import
java.util.*;
Public class
XMLResourceBundleControl
extends
ResourceBundle.Control
{
private static
String XML =
"xml"
;
Public
List getFormats
(String baseName
) {
return
Collections.singletonList
(XML
)
;
}
Public
ResourceBundle newBundle
(String baseName, Locale locale,
String format, ClassLoader loader,
boolean
reload
)
throws
IllegalAccessException, InstantiationException, IOException
{
if
((baseName ==
null
)
||
(locale ==
null
)
||
(format ==
null
)
||
(loader ==
null
)) {
throw new
NullPointerException
()
;
}
ResourceBundle bundle =
null
;
if
(format.equals
(XML
)) {
String bundleName = toBundleName
(baseName, locale
)
;
String resourceName = toResourceName
(bundleName, format
)
;
URL url = loader.getResource
(resourceName
)
;
if
(url !=
null
) {
URLConnection connection = url.openConnection
()
;
if
(connection !=
null
) {
if
(reload
) {
connection.setUseCaches
(false
)
;
}
InputStream stream = connection.getInputStream
()
;
if
(stream !=
null
) {
BufferedInputStream bis =
new
BufferedInputStream
(
stream
)
;
bundle =
new
XMLResourceBundle
(bis
)
;
bis.close
()
;
}
}
}
}
return
bundle;
}
Private static class
XMLResourceBundle
extends
ResourceBundle
{
private
Properties props;
XMLResourceBundle
(InputStream stream
)
throws
IOException
{
props =
new
Properties
()
;
props.loadFromXML
(stream
)
;
}
Protected
Object handleGetObject
(String key
) {
return
props.getProperty
(key
)
;
}
Public
Enumeration getKeys
() {
Set handleKeys = props.stringPropertyNames
()
;
return
Collections.enumeration
(handleKeys
)
;
}
}
Public static
void
main
(String args
) {
("Test2"
,
new
XMLResourceBundleControl
())
;
String string = bundle.getString
("HelpKey"
)
;
System.out.println
("HelpKey: "
+ string
)
;
}
}
В данную реализацию включена тестовая программа из трех строчек:
ResourceBundle bundle = ResourceBundle.getBundle
("Test2"
,
new
XMLResourceBundleControl
())
;
String string = bundle.getString
("HelpKey"
)
;
System.out.println
("HelpKey: "
+ string
)
;
Наибольший интерес здесь представляет первая строка. Вам необходимо передать ваш элемент Control методу getBundle() . После этого вы можете использовать набор, как и в любом другом случае.
Ниже преводится пример XML файла Test2.xml:
http://java.sun.com/dtd/properties.dtd
"
>
Результатом выполнения программы XMLResourceBundleControl будет:
> java XMLResourceBundleControl HelpKey: Help
В приведенной реализации не используются методы getTimeToLive() и needsReload() :
public long getTimeToLive (String baseName, Locale locale )
Public
boolean
needsReload
(String baseName,
Locale locale,
String format,
ClassLoader loader,
ResourceBundle bundle,
long
loadTime
)
Метод getTimeToLive() возвращает время жизни для наборов ресурсов, созданных при помощи ResourceBundle.Control . Наборы ресурсов сохраняются в кеше для убыстрения процесса повторной загрузки. Таким образом, при повторной загрузке набора, он будет находиться в кеше. Положительное значение времени жизни затает в милисекундах продолжительность сохранения набора в кеше без повторной проверки. По-умолчанию значением, возвращаемым методом getTimeToLive() является TTL_NO_EXPIRATION_CONTROL , отключающее проверку истечения времени хранения в кеше. Если вы не хотите кешировать набор, то верните значение TTL_DONT_CACHE . Если возвращается значение 0, то набор кешируется, но при каждом вызове метода getBundle() происходит его проверка. Для очистки кеша вызовите статичный метод clearCache() класса ResourceBundle . В нем есть не обязательный аргумент ClassLoader , позволяющий очищать кеши, созданные определенным загрузчиком.
Метод needsReload() определяет необходимость перезагрузки кешированного набора. Значение true означает, что набор необходимо перезагрузить, а false , что не его перезагружать не надо. Вы можете контролировать необходимость перезагрузки набора ресурсов при помощи перегрузки метода needsReload() . Например, если вы хотите, чтобы набор ресурсов всегда перезагружался, метод needsReload() должен всегда возвращать значние true . В этом случае метод getTimeToLive() должен возвращать всегда значение 0. Иначе набор будет сохраняться дольше, чем положено.
Для получения дополнительной информации об улучшениях, связанных с процессами интернационализации в Mustang, вы можете обратиться к блогу Джона Оконера, разработчика програмнного обеспечения фирмы Sun, по адресу