Американски национален институт по стандартизация(Английски) Американски ннационален сстандарти азинститут, ANSI) е асоциация на американски индустриални и бизнес групи, която разработва търговски и комуникационни стандарти. Той е член на ISO и IEC, представлявайки интересите на САЩ там.
История
ANSI първоначално е създаден през 1918 г., когато пет инженерни дружества и три правителствени агенции основават "Американския комитет по инженерни стандарти" ( AESC- Английски. Американски комитет по инженерни стандарти). През 1928 г. комитетът става известен като Американската асоциация по стандартизация. КАТО- Английски. Американска асоциация по стандартизация). През 1966 г. ASA е реорганизирана и се превръща в „Институт за стандарти на Съединените американски щати“ ( USASI- Английски. Институт по стандартизация на Съединените американски щати). Настоящото име е прието през 1969 г.
До 1918 г. имаше пет инженерни дружества, участващи в разработването на технически стандарти:
- Американски институт на електроинженерите (AIEE, сега IEEE)
- Американско дружество на машинните инженери (ASME)
- Американско дружество на строителните инженери (ASCE)
- Американски институт на минните инженери (AIME, сега Американски институт на минните, металургични и петролни инженери)
- Американско дружество за изпитване и материали (сега ASTM)
През 1916 г. Американският институт на електроинженерите (сега IEEE) пое инициативата да обедини усилията на тези организации за създаване на независим национален орган, който да координира разработването на стандарти, хармонизирането и одобрението на националните стандарти. Горните пет организации станаха основните членове на Обединеното инженерно общество (United Engineering Society - UES), впоследствие Министерството на войната на САЩ, Военноморските сили (обединени през 1947 г., за да станат Министерството на отбраната на САЩ) и Търговията бяха поканени да участват като основатели.
През 1931 г. организацията (преименувана на ASA през 1928 г.) става част от Националния комитет на САЩ към Международната електротехническа комисия (IEC), който е създаден през 1904 г. за разработване на стандарти в електрическото и електронното инженерство
Членове
Членовете на ANSI включват правителствени агенции, организации, академични и международни организации и физически лица. Като цяло Институтът представлява интересите на повече от 270 000 компании и организации и 30 милиона професионалисти по целия свят /
Дейност
Въпреки че самият ANSI не разработва стандарти, Институтът наблюдава разработването и използването на стандарти чрез акредитация на процедурите на организациите за разработване на стандарти. Акредитацията на ANSI означава, че процедурите, използвани от организациите, разработващи стандарти, отговарят на изискванията на Института за откритост, баланс, консенсус и надлежен процес.
ANSI също определя специфични стандарти като американски национални стандарти или ANS, когато Институтът определи, че стандартите са разработени в среда, която е справедлива, достъпна и отговаряща на нуждите на различни заинтересовани страни.
Международна дейност
В допълнение към дейностите по стандартизация на САЩ, ANSI насърчава международното използване на стандартите на САЩ, защитава политическата и техническата позиция на САЩ в международни и регионални организации по стандартизация и насърчава приемането на международните стандарти като национални стандарти.
Институтът е официален представител на САЩ в две големи международни организации по стандартизация, Международната организация по стандартизация (ISO) като член-основател и Международната електротехническа комисия (IEC) чрез Националния комитет на САЩ (USNC). ANSI участва в почти всички техническа програма ISO и IEC и управлява много ключови комитети и подгрупи. В много случаи американските стандарти се подават на ISO и IEC чрез ANSI или USNC, където се приемат изцяло или частично като международни стандарти.
Приемането на стандартите ISO и IEC като стандарти на САЩ се е увеличило от 0,2% през 1986 г. на 15,5% през май 2012 г.
Насоки на стандартизация
Институтът управлява девет стандартизационни групи:
- ANSI Homeland Defense and Security Standardization Collaborative (HDSSC)
- Панел за стандарти за нанотехнологии ANSI (ANSI-NSP - Панел за стандарти за нанотехнологии ANSI)
- ID Theft Prevention and ID Standards Management Panel (IDSP - ID Theft Prevention and ID Management Standards Panel)
- ANSI Energy Efficiency Standardization Coordination Collaborative (EESCC)
- Сътрудничество за координация на стандарти за ядрена енергия (NESCC-Сътрудничество за координация на стандарти за ядрена енергия)
- Панел за стандарти за електрически превозни средства (EVSP)
- ANSI-NAM Мрежа за химическо регулиране
- Координационен панел за стандарти за биогорива на ANSI
- Панел по стандарти за информационни технологии в здравеопазването (HITSP)
- Американска агенция за сертифициране на тръбопроводи и машини
Всяка от групите се занимава с идентифициране, координиране и хармонизиране на доброволни стандарти, свързани с тези области. През 2009 г. ANSI и (NIST) сформираха Сътрудничеството за координиране на стандартите за ядрена енергия (NESCC). NESCC е съвместна инициатива за идентифициране и посрещане на текущата нужда от стандарти в ядрената индустрия.
Стандарти
От стандартите, приети от института, са известни следните:
Противно на популярното погрешно схващане, ANSI не е приел стандартите за 8-битови кодови страници, въпреки че е участвал в разработването на кодирането ISO-8859-1 и вероятно някои други.
Бележки
- Относно ANSI
- RFC
- ANSI: Исторически преглед (неопределен) . ansi.org. Посетен на 31 октомври 2016.
- История на ANSI
Струва си да се отбележи, че всички обозначения на класове на налягане ANSI имат определено значение, а именно стойността на налягането, но само в единици, различни от тези, с които сме свикнали. Всички числа след ANSI показват стойността на номиналното (номинално) налягане: ANSI 150, ANSI 300, ANSI 600, ANSI 900, ANSI 1500, ANSI 2500 и ANSI 4500. Например ANSI 150 означава, че номиналното налягане е 150 psi. На английски това се изписва като Pound-force per Square Inch или накратко PSI.
Съответно по този начин е възможно да се направи независимо преобразуване от паундове на квадратен инч в бар (100 kPa) или MPa. За независимо изчисление на точното, ще трябва да знаете, че 1 PSI \u003d 6894,76 Pa. Всички изчисления на налягането по ANSI в барове и паскали могат да бъдат направени, когато има време и нужда от точни данни, като в същото време повечето стандартни стойности за класове на налягане по ANSI вече имат стандартни стойности за барове и MPa. За да опростим, съставихме кратка таблица за справка:
Таблица на класовете на налягане ANSI с преобразуване в Bar и MPa
|
Клас на налягане ANSI |
||
Понякога дори доста опитен специалист няма да ви каже веднага каква конкретна стойност на налягането или дължината в една система съответства на стойностите в друга система от количества.
Да се облекчавамви тази задача, ние предлагаме таблици на връзката между налягането и дължината в европейската и американската система с малки обяснения. Но първо, няколко думи за самите стандарти.
DINе немският стандарт (съкращение от Deutsches Institut für Normung, т.е. разработен от Германския институт за стандартизация), който е разработен стриктно в рамките на разпоредбите на Международната организация по стандартизация - ISO (Международна организация за стандартизация).
ANSIе стандартът, приет в Съединените американски щати. означава Американски национален институт по стандартизация, който е стандартът на Американския национален институт по стандартизация.
Съответно стандартите на ANSI се определят от същата тази институция и то далеч не винагимежду стандартите DINи ANSIможе да се проследи точната съответствиев различни области.
Преобразуване на единици за налягане от ANSI в DIN
Тук всичко е просто: ако според стандарта ANSIсрещу налягането е числото 150 - това означава, че номиналното (за което е проектиран вентилът) налягане е 20 bar, 300 - 50 bar и т.н. Максимална стойност за ANSI клас– 2500 ще се равнява на 420 бара според европейския стандарт DIN.
Използвайки тази таблица, не е трудноконвертирайте стойностите на налягането и обратно: от DINв ANSI, въпреки че нашите инженери се нуждаят от много по-рядко.
Преобразуване на единици за дължина от американската система в европейската (руска)
Както е известно, американцивсичко се измерва в инчове и футове, а ние европейци- милиметри, сантиметри и метри, тоест като по-голямата част от страните в света, в които живеем показателсистема от единици.
Как да конвертирате инчове в милиметри? Всъщност в това също няма нищо сложно, просто не забравяйте, че 1 инч е равен на 25,4 мм. Въпреки това, често цифрата след десетичната запетая пренебрегванеи за добра мярка посочете това 1 инч = 25 мм.
Така, ако например напречното сечение на входа е 2 инча според американската система от мерки, тогава, превеждайки тази стойност в нашата система от мерки съгласно горното правило, получаваме 50 mm или по-точно, 51 мм (закръгляване 50,8 по правилата) .
Остава да добавим, че диаметърът в техническихарактеристиките са отбелязани с латински букви DNи често се посочва в инча, а налягането се обозначава с буквите PNи най-често се посочва в барове- във всеки случай използваме точно тази маркировка като най-много удобно.
И следната таблица ще помогнеизчислявате не само точноброя на милиметрите в един инч (с точност до хилядна от милиметъра), но също така ще ви помогне да разберете колко милиметра се съдържат в например 2,5 инча.
За да направите това, намираме колона 2 "" (2 инча), а отляво търсим стойността 1/2. Общо 2,5 инча = 63,501 мм, което може да се закръгли до 64 мм, и например 6,25 инча (т.е. 6 и 1/4) = 158,753 мм или 159 мм.
|
| Инчове "" до милиметри |
|||||||
|
| ||||||||
|
| ||||||||
Reg.ru: домейни и хостинг
Най-големият регистратор и хостинг доставчик в Русия.
Над 2 милиона имена на домейни в услуга.
Промоция, поща за домейн, решения за бизнеса.
Повече от 700 хиляди клиенти по света вече са направили своя избор.
*Задръжте курсора на мишката, за да спрете превъртането на пауза.
Назад напред
Кодировки: полезна информация и кратка ретроспекция
Реших да напиша тази статия като малък преглед на проблема с кодировките.
Ще разберем какво е кодирането като цяло и ще се докоснем малко до историята на това как са се появили по принцип.
Ще говорим за някои от техните характеристики и също така ще разгледаме точките, които ни позволяват да работим с кодировките по-съзнателно и да избягваме т.нар. кракозябров, т.е. нечетливи знаци.
Така че да тръгваме...
Какво е кодиране?
Просто казано, кодиранее таблица със съпоставяния на знаци, които можем да видим на екрана, към определени цифрови кодове.
Тези. всеки знак, който въвеждаме от клавиатурата или виждаме на екрана на монитора, е кодиран от определена последователност от битове (нули и единици). 8 бита, както вероятно знаете, са равни на 1 байт информация, но повече за това по-късно.
Външният вид на самите знаци се определя от файловете с шрифтовекоито са инсталирани на вашия компютър. Следователно процесът на показване на текст на екрана може да се опише като постоянно съпоставяне на поредици от нули и единици към някои специфични знаци, които са част от шрифта.
Може да се счита за прародител на всички съвременни кодировки ASCII.
Това съкращение означава Американски стандартен код за обмен на информация(Американска стандартна кодираща таблица за печатни знаци и някои специални кодове).
то еднобайтово кодиране, който първоначално съдържаше само 128 знака: букви от латинската азбука, арабски цифри и др.

По-късно той беше разширен (първоначално не използваше всичките 8 бита), така че стана възможно да се използват не 128, а 256 (2 до 8) различни символа, които могат да бъдат кодирани в един байт информация.
Това подобрение направи възможно добавянето към ASCII символи на националните езици, в допълнение към вече съществуващата латиница.
Има много опции за разширено ASCII кодиране, поради факта, че има и много езици в света. Мисля, че много от вас са чували за такова кодиране като KOI8-R също е разширено ASCII кодиране, проектиран да работи с руски знаци.
Следваща стъпка в развитието на кодировките може да се счита появата на т.нар ANSI кодировки.
По същество те бяха еднакви разширени версии на ASCII, но от тях бяха премахнати различни псевдографични елементи и бяха добавени типографски символи, за които преди това нямаше достатъчно „свободни пространства“.
Пример за такова ANSI кодиране е добре познатото Windows-1251. В допълнение към типографските символи, това кодиране включваше и букви от азбуките на езици, близки до руския (украински, беларуски, сръбски, македонски и български).
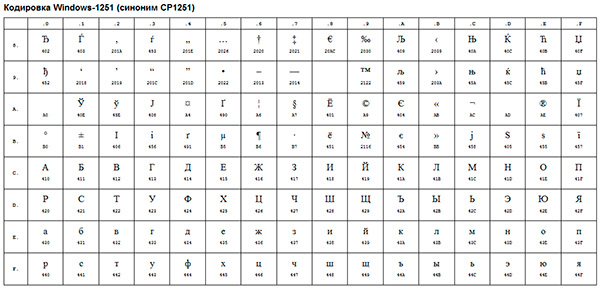
ANSI кодирането е общото име за. Всъщност действителното кодиране при използване на ANSI ще се определя от това, което е посочено в системния регистър на вашия операционна система Windows. В случай на руски това ще бъде Windows-1251, но за други езици ще бъде различен вид ANSI.
Както разбирате, куп кодировки и липсата на единен стандарт не доведоха до добро, което беше причината за честите срещи с т.нар. кракозябри- нечетлив безсмислен набор от знаци.
Причината за появата им е проста - тя е опитайте се да покажете знаци, кодирани с една таблица за кодиране, като използвате друга таблица за кодиране.
В контекста на уеб разработката може да срещнем грешки, когато напр. Руският текст е записан погрешно в грешното кодиране, което се използва на сървъра.
Разбира се, това не е единственият случай, когато можем да получим нечетлив текст - тук има много опции, особено като имате предвид, че има и база данни, в която информацията също се съхранява в определено кодиране, има връзка с база данни картографиране и др.
Появата на всички тези проблеми послужи като стимул за създаване на нещо ново. Предполагаше се, че това е кодиране, което може да кодира всеки език в света (в края на краищата, с помощта на еднобайтови кодировки, с цялото желание е невъзможно да се опишат всички знаци, да речем, Китайски, където очевидно има повече от 256), всякакви допълнителни специални знаци и типография.
С една дума, беше необходимо да се създаде универсално кодиране, което ще реши проблема с грешките веднъж завинаги.
Unicode - универсално кодиране на текст (UTF-32, UTF-16 и UTF-8)
Самият стандарт е предложен през 1991 г. от организация с нестопанска цел "Консорциум Unicode"(Unicode Consortium, Unicode Inc.), а първият резултат от неговата работа е създаването на кодиране UTF-32.
Между другото съкр UTFозначава Unicode формат за трансформация(Формат за конвертиране на Unicode).
При това кодиране, за да се кодира един знак, трябваше да се използват колкото се може повече 32 бита, т.е. 4 байта информация. Ако сравним това число с еднобайтови кодировки, тогава ще стигнем до просто заключение: за да кодирате 1 знак в това универсално кодиране, трябва 4 пъти повече бита, което "претегля" файла 4 пъти.
Също така е очевидно, че броят на знаците, които потенциално биха могли да бъдат описани с помощта на това кодиране, надхвърля всички разумни ограничения и е технически ограничен до число, равно на 2 на степен 32. Ясно е, че това беше явно прекаляване и прахосничество по отношение на теглото на файловете, така че това кодиране не беше широко използвано.
Той беше заменен от нова разработка - UTF-16.
Както подсказва името, в това кодиране се кодира един знак вече не 32 бита, а само 16(т.е. 2 байта). Очевидно това прави всеки знак два пъти "по-лек" отколкото в UTF-32, но и два пъти по-"тежък" от всеки знак, кодиран с помощта на еднобайтово кодиране.
Броят на наличните знаци за кодиране в UTF-16 е най-малко 2 на степен 16, т.е. 65536 знака. Всичко изглежда наред, освен това крайната стойност на кодовото пространство в UTF-16 е разширена до повече от 1 милион знака.
Това кодиране обаче не задоволи напълно нуждите на разработчиците. Да речем, че ако пишете, използвайки изключително латински символи, тогава след преминаване от разширената версия на ASCII кодирането към UTF-16, теглото на всеки файл се удвоява.
Като резултат, беше направен още един опит да се създаде нещо универсално, и това нещо се превърна в добре познатото UTF-8 кодиране.
UTF-8- това е многобайтово кодиране на знаци с променлива дължина на знаците. Гледайки името, може да си помислите, по аналогия с UTF-32 и UTF-16, че 8 бита се използват за кодиране на един знак, но това не е така. По-точно, не съвсем така.
Това е така, защото UTF-8 осигурява най-добрата съвместимост с по-стари системи, които използват 8-битови знаци. За кодиране на един знак всъщност се използва UTF-8 1 до 4 байта(хипотетично е възможно до 6 байта).
В UTF-8 всички латински знаци са кодирани с 8 бита, точно както при ASCII кодирането.. С други думи, основната част от ASCII кодирането (128 знака) се премести в UTF-8, което ви позволява да "прекарате" само 1 байт за тяхното представяне, като същевременно запазите универсалността на кодирането, за което всичко е започнато.
Така че, ако първите 128 знака са кодирани с 1 байт, тогава всички останали символи вече са кодирани с 2 байта или повече. По-конкретно, всеки знак на кирилица е кодиран с точно 2 байта.
По този начин получихме универсално кодиране, което ни позволява да покрием всички възможни знаци, които трябва да бъдат показани, без излишни "по-тежки" файлове.
С BOM или без BOM?
Ако сте работили с текстови редактори(от редактори на кодове), например Notepad++, phpDesigner, бърз PHPи т.н., тогава вероятно са обърнали внимание на факта, че когато задавате кодирането, в което ще бъде създадена страницата, обикновено можете да изберете 3 опции:
ANSI
-UTF-8
- UTF-8 без BOM


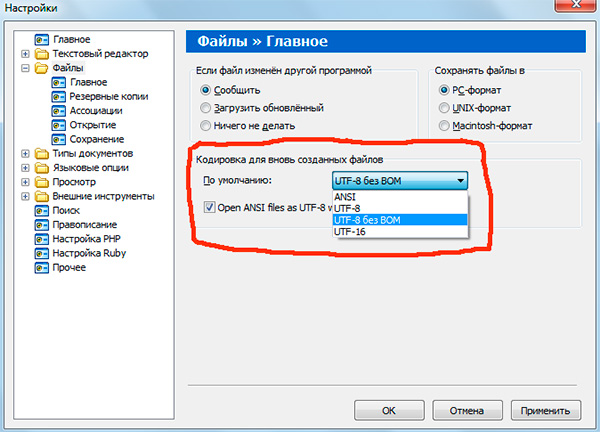
Веднага ще кажа, че винаги си струва да избирате последен вариант - UTF-8 без BOM.
И така, какво е BOM и защо не ни трябва?
BOMозначава Марка за ред на байтове. Това е специален Unicode знак, използван за указване на endianness. текстов файл. Според спецификацията използването му не е задължително, но ако BOMсе използва, той трябва да бъде зададен в началото на текстовия файл.
Няма да навлизаме в детайли на работата BOM. За нас основният извод е следният: използването на този служебен символ заедно с UTF-8 не позволява на програмите да четат нормално кодирането, което води до грешки в скрипта.
ANSI е стандарт за показване на знаци, разработен от Американския национален институт по стандартизация (код 1251). Стандартът ANSI използва само един байт за представяне на всеки знак и следователно е ограничен до максимум 256 знака, включително пунктуация. Кодовете от 32 до 126 следват стандарта ASCII. ASCII (код 688) се използва в DOS, ANSI се използва в Windows.
Литература
Архангелски А.Я. Програмиране в C++ Builder6. Изд. БИНОМ, 2004г.
Архангелски А.Я. C++Builder6. Справочно ръководство. Москва, Изд. БИНОМ, 2004г.
Kimmel P. Borland C++5 "BHV-Санкт Петербург, 2001 г.
Климова Л.М. C++ Практическо програмиране. Решение на типови задачи. "KUDITS-IMAGE", M.2001.
Култин Н. С/С++ в задачи и примери. Санкт Петербург "BHV-Петербург", 2003 г.
Павловская Т.А. Програмиране на C/C++ на език от високо ниво. Петър, Москва-Санкт Петербург-… 2005 г
Павловская Т.А., Шчупак Ю.А. C++. Обектно-ориентирано програмиране. Работилница. СПб., Питър, 2005 г.
Подбелски В.В. Език C++ Финанси и статистика, Москва, 2003 г.
Поляков А.Ю., Брусенцев В.А. Методи и алгоритми компютърна графикав примери в Visual C++. СПб БХИ-Петербург, 2003г
Savitch W. Language C++ курс по обектно-ориентирано програмиране. Издателство Уилямс. Москва-Санкт Петербург-Киев, 2001г
Wellin S. Как да не програмираме на C++. "Петър". Москва-Санкт Петербург-Нижни Новгород-Воронеж-Новосибирск-Ростов-на-Дон-Екатеринбург-Самара-Киев-Харков-Минск, 2004 г.
Шийлд Г. Пълна справкав C++. Изд. Къща "Уилямс" Москва-Санкт Петербург-Киев, 2003г.
Schildt G. Самоучител C/C++. Санкт Петербург, BHV-Петербург, 2004 г.
Schildt G. Ръководство на програмиста за C/C++ Изд. Къща "Уилямс" Москва-Санкт Петербург-Киев, 2003г.
Шиманович.Л. С/С++ в примери и задачи. Минск, Ново знание, 2004.
Стърн В. Основи на C++. Методи на софтуерното инженерство. Изд. Лори.
Защо вместо руски букви в конзолното приложение се показва боклук?
и правилно! Текстът на програмата, който сте въвели в собствения си редактор визуално студио, използвайки кодова страница 1251, а извеждането на текст в конзолното приложение използва кодова страница 866. Какво да правим с този позор? Както знаете, от всяка безизходица има поне 3 изхода. Нека ги разгледаме по ред.
Изход 1
Въведете текста на програмата в редактора на произволен файлов мениджър на конзолата.
Но какво ще кажете за подчертаването на синтаксиса, показването на помощ за избраната функция с помощта на F1 и други малки прелести, които освежават мрачния живот на обикновен програмист? Не, това не е опция за нас.
Изход 2
Ако сте започнали да пишете конзолна програма от нулата, тя може да ви подхожда. Нека пренапишем нашия малък шедьовър така:
|
#include "stdafx.h" #include "windows.h" int main(int argc, char* argv) char s="Здравейте на всички!"; printf("%s\n", s); |
Ключовата дума тук е CharToOem - именно тази функция ще преобразува нашия низ в желаната кодова страница. С резултата от нашата програма вече всичко е наред.
Но възниква следващият въпрос - какво да направите, ако трябва да прекомпилирате старата си DOS програма от 100 000 реда, написана на Borland C++ 3.1, в Windows конзолно приложение, в което подобна ситуация се случва на всеки втори ред. Но все пак трябва да го настроите към MS компилатора и също така искате да оптимизирате няколко парчета код ...
Тук вероятно има смисъл да се използва ходът на коня, в смисъл