American National Standards Institute(English) A merican n ational s tandards i institute, ANSI) is an association of American industrial and business groups that develops trade and communication standards. He is a member of ISO and IEC , representing US interests there .
Story
ANSI was originally formed in 1918 when five engineering societies and three government agencies founded the "American Engineering Standards Committee" ( AESC- English. American Engineering Standards Committee). In 1928 the committee became known as the American Standards Association. ASA- English. American Standards Association). In 1966, the ASA was reorganized and became the "Standards Institute of the United States of America" ( USASI- English. United States of America Standards Institute). The current name was adopted in 1969.
Until 1918, there were five engineering societies involved in the development of technical standards:
- American Institute of Electrical Engineers (AIEE, now IEEE)
- American Society of Mechanical Engineers (ASME)
- American Society of Civil Engineers (ASCE)
- American Institute of Mining Engineers (AIME, now the American Institute of Mining, Metallurgical and Petroleum Engineers)
- American Society for Testing and Materials (now ASTM)
In 1916, the American Institute of Electrical Engineers (now IEEE) took the initiative to combine the efforts of these organizations to create an independent national body to coordinate the development of standards, the harmonization and approval of national standards. The above five organizations became the main members of the United Engineering Society (United Engineering Society - UES), subsequently the US Department of War was invited to participate in it as founders, Navy(merged in 1947 to become the US Department of Defense) and Commerce.
In 1931, the organization (renamed ASA in 1928) became part of the US National Committee of the International Electrotechnical Commission (IEC) which was formed in 1904 to develop standards in electrical and electronic engineering
Members
ANSI members include government agencies, organizations, academic and international organizations, and individuals. In total, the Institute represents the interests of more than 270,000 companies and organizations and 30 million professionals worldwide /
Activity
Although ANSI itself does not develop standards, the Institute oversees the development and use of standards through the accreditation of standards development organizations' procedures. ANSI accreditation means that the procedures used by standards developing organizations meet the Institute's requirements for openness, balance, consensus, and due process.
ANSI also designates specific standards as American National Standards, or ANS, when the Institute determines that the standards were developed in an environment that is fair, accessible, and responsive to the needs of various stakeholders.
International activity
In addition to US standardization activities, ANSI promotes the international use of US standards, advocates US political and technical position in international and regional standards organizations, and encourages the adoption of international standards as national standards.
The Institute is the official US representative in two major international standards organizations, the International Organization for Standardization (ISO) as a founding member, and the International Electrotechnical Commission (IEC) through the US National Committee (USNC). ANSI is involved in almost all technical program ISO and IEC and governs many key committees and subgroups. In many cases, US standards are submitted to ISO and IEC via ANSI or USNC, where they are accepted in whole or in part as International Standards.
Acceptance of ISO and IEC standards as US standards increased from 0.2% in 1986 to 15.5% in May 2012.
Directions of standardization
The Institute manages nine standardization groups:
- ANSI Homeland Defense and Security Standardization Collaborative (HDSSC)
- ANSI Nanotechnology Standards Panel (ANSI-NSP - ANSI Nanotechnology Standards Panel)
- ID Theft Prevention and ID Management Standards Panel (IDSP - ID Theft Prevention and ID Management Standards Panel)
- ANSI Energy Efficiency Standardization Coordination Collaborative (EESCC)
- Nuclear Energy Standards Coordination Collaborative (NESCC-Nuclear Energy Standards Coordination Collaborative)
- Electric Vehicles Standards Panel (EVSP)
- ANSI-NAM Network on Chemical Regulation
- ANSI Biofuels Standards Coordination Panel
- Healthcare Information Technology Standards Panel (HITSP)
- American Piping and Machinery Certification Agency
Each of the groups is engaged in identifying, coordinating and harmonizing voluntary standards related to these areas. In 2009, ANSI and (NIST) formed the Nuclear Energy Standards Coordinating Collaboration (NESCC). NESCC is a collaborative initiative to identify and meet the current need for standards in the nuclear industry.
Standards
Of the standards adopted by the institute, the following are known:
Contrary to popular misconception, ANSI did not adopt the 8-bit code page standards, although it was involved in the development of the ISO-8859-1 encoding and possibly some others.
Notes
- About ANSI
- RFC
- ANSI: Historical overview (indefinite) . ansi.org. Retrieved 31 October 2016.
- History of ANSI
It is worth noting that all designations of pressure classes according to ANSI have a certain meaning, namely the value of pressure, but only in other units than we are used to. All numbers after ANSI indicate the value of Nominal (Nominal) Pressure: ANSI 150, ANSI 300, ANSI 600, ANSI 900, ANSI 1500, ANSI 2500 and ANSI 4500. For example, ANSI 150 means that the nominal pressure is 150 psi. In English, this is written as Pound-force per Square Inch, or PSI for short.
Accordingly, in this way it is possible to make an independent conversion from pounds per square inch to bar (100 kPa) or MPa. For an independent calculation of the exact one, you will need to know that 1 PSI \u003d 6894.76 Pa. All ANSI pressure calculations in bar and Pascals can be done when there is time and need for accurate data, at the same time, most standard ANSI pressure class values already have standard bar and MPa values. To simplify, we have compiled a short table for your reference:
Table of ANSI pressure classes with conversion to Bar and MPa
|
ANSI pressure class |
||
Sometimes even a fairly experienced specialist will not immediately tell you what a particular value of pressure or length in one system corresponds to values in another system of quantities.
To alleviate you this task, we offer tables of the relationship between pressure and length in the European and American systems with small explanations. But first, a few words about the standards themselves.
DIN is the German standard (stands for Deutsches Institut für Normung, that is, developed by the German Institute for Standardization), which is developed strictly within the framework of the provisions of the International Organization for Standardization - ISO (International Organization for Standardization).
ANSI is the standard adopted in the United States of America. stands for American National Standards Institute, which is the American National Standards Institute standard.
Accordingly, the ANSI standards are determined by this very institution, and far not always between standards DIN and ANSI can trace the exact compliance in various fields.
Converting pressure units from ANSI to DIN
Everything is simple here: if according to the standard ANSI opposite the pressure is the number 150 - this means that the nominal (for which the valve is designed) pressure is 20 bar, 300 - 50 bar, etc. Maximum value for ANSI class– 2500 will be equal to 420 bar according to the European standard DIN.
Using this table, not difficult convert pressure values and vice versa: from DIN in ANSI, although our engineers need much more less often.
Converting units of length from the American system to the European (Russian)
As is known, Americans everything is measured in inches and feet, and we Europeans- millimeters, centimeters and meters, that is, like the vast majority of countries in the world, we live in metric system of units.
How to convert inches to millimeters? In fact, there is nothing complicated about this either, just remember that 1 inch equals 25.4 mm. However, often the digit after the decimal point neglect and for good measure indicate that 1 inch = 25mm.
Thus, if, for example, the cross section of the inlet is 2 inches according to the American system of measures, then, by translating this value into our system of measures according to the above rule, we get 50 mm or, more precisely, 51 mm (rounding 50.8 according to the rules) .
It remains to add that the diameter in technical characteristics are marked in Latin letters DN and is often indicated in inches, and the pressure is denoted by the letters PN and is most often indicated in bars- in any case, we use exactly this marking as the most comfortable.
And the following table will help you calculate not only exact the number of millimeters in one inch (with an accuracy of a thousandth of a millimeter), but it will also help you find out how many millimeters are contained in, for example, 2.5 inches.
To do this, we find the column 2 "" (2 inches), and on the left we look for the value 1/2. Total 2.5 inches = 63.501 mm, which can be rounded up to 64 mm, and, for example, 6.25 inches (that is, 6 and 1/4) = 158.753 mm or 159 mm.
|
| Inches "" to millimeters |
|||||||
|
| ||||||||
|
| ||||||||
Reg.ru: domains and hosting
The largest registrar and hosting provider in Russia.
Over 2 million domain names in service.
Promotion, mail for domain, solutions for business.
More than 700 thousand customers around the world have already made their choice.
*Mouseover to pause scrolling.
Back forward
Encodings: useful information and a brief retrospective
I decided to write this article as a small review on the issue of encodings.
We will understand what encoding is in general and touch a little on the history of how they appeared in principle.
We will talk about some of their features and also consider the points that allow us to work with encodings more consciously and avoid the appearance on the site of the so-called krakozyabrov, i.e. unreadable characters.
So let's go...
What is an encoding?
Simply put, encoding is a table of character mappings that we can see on the screen, to certain numeric codes.
Those. each character that we enter from the keyboard, or see on the monitor screen, is encoded by a certain sequence of bits (zeros and ones). 8 bits, as you probably know, are equal to 1 byte of information, but more on that later.
The appearance of the characters themselves is determined by the font files that are installed on your computer. Therefore, the process of displaying text on the screen can be described as a constant matching of sequences of zeros and ones to some specific characters that are part of the font.
The progenitor of all modern encodings can be considered ASCII.
This abbreviation stands for American Standard Code for Information Interchange(American standard encoding table for printable characters and some special codes).
it single byte encoding, which originally contained only 128 characters: letters of the Latin alphabet, Arabic numerals, etc.

Later it was expanded (initially it did not use all 8 bits), so it became possible to use not 128, but 256 (2 to 8) different characters that can be encoded in one byte of information.
This improvement made it possible to add to ASCII symbols of national languages, in addition to the already existing Latin alphabet.
There are a lot of options for extended ASCII encoding, due to the fact that there are also a lot of languages in the world. I think that many of you have heard of such an encoding as KOI8-R is also an extended ASCII encoding, designed to work with Russian characters.
The next step in the development of encodings can be considered the appearance of the so-called ANSI encodings.
Essentially they were the same extended versions of ASCII, however, various pseudo-graphic elements were removed from them and typographic symbols were added, for which there were not enough "free spaces" previously.
An example of such an ANSI encoding is the well-known Windows-1251. In addition to typographic symbols, this encoding also included letters of the alphabets of languages close to Russian (Ukrainian, Belarusian, Serbian, Macedonian and Bulgarian).
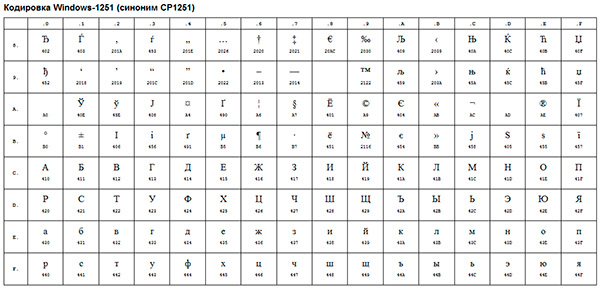
ANSI encoding is the collective name for. In fact, the actual encoding when using ANSI will be determined by what is specified in the registry of your operating system Windows. In the case of Russian, this will be Windows-1251, however, for other languages, it will be a different kind of ANSI.
As you understand, a bunch of encodings and the lack of a single standard did not bring to good, which was the reason for frequent meetings with the so-called krakozyabry- an unreadable meaningless set of characters.
The reason for their appearance is simple - it is attempt to display characters encoded with one encoding table using another encoding table.
In the context of web development, we may encounter bugs when, for example, Russian text is mistakenly saved in the wrong encoding that is used on the server.
Of course, this is not the only case when we can get unreadable text - there are a lot of options here, especially when you consider that there is also a database in which information is also stored in a certain encoding, there is a database connection mapping, etc.
The emergence of all these problems served as an incentive to create something new. It was supposed to be an encoding that could encode any language in the world (after all, with the help of one-byte encodings, with all the desire, it is impossible to describe all characters, say, Chinese, where there are clearly more than 256), any additional special characters, and typography.
In a word, it was necessary to create a universal encoding that would solve the problem of bugs once and for all.
Unicode - universal text encoding (UTF-32, UTF-16 and UTF-8)
The standard itself was proposed in 1991 by a non-profit organization "Unicode Consortium"(Unicode Consortium, Unicode Inc.), and the first result of his work was the creation of an encoding UTF-32.
Incidentally, the abbreviation UTF stands for Unicode Transformation Format(Unicode Conversion Format).
In this encoding, to encode one character, it was supposed to use as many as 32 bits, i.e. 4 bytes of information. If we compare this number with single-byte encodings, then we will come to a simple conclusion: to encode 1 character in this universal encoding, you need 4 times more bits, which "weights" the file 4 times.
It is also obvious that the number of characters that could potentially be described using this encoding exceeds all reasonable limits and is technically limited to a number equal to 2 to the power of 32. It is clear that this was a clear overkill and wastefulness in terms of the weight of the files, so this encoding was not widely used.
It was replaced by a new development - UTF-16.
As the name implies, in this encoding one character is encoded no longer 32 bits, but only 16(i.e. 2 bytes). Obviously, this makes any character twice "lighter" than in UTF-32, but also twice as "heavier" than any character encoded using a single-byte encoding.
The number of characters available for encoding in UTF-16 is at least 2 to the power of 16, i.e. 65536 characters. Everything seems to be fine, besides, the final value of the code space in UTF-16 has been expanded to more than 1 million characters.
However, this encoding did not fully satisfy the needs of developers. Let's say if you write using exclusively Latin characters, then after switching from the extended version of the ASCII encoding to UTF-16, the weight of each file doubled.
As a result, another attempt was made to create something universal, and this something has become the well-known UTF-8 encoding.
UTF-8- this is multibyte character encoding with variable character length. Looking at the name, you might think, by analogy with UTF-32 and UTF-16, that 8 bits are used to encode one character, but this is not so. More precisely, not quite so.
This is because UTF-8 provides the best compatibility with older systems that used 8-bit characters. To encode a single character in UTF-8 is actually used 1 to 4 bytes(hypothetically possible up to 6 bytes).
In UTF-8, all Latin characters are encoded with 8 bits, just like in ASCII encoding.. In other words, the basic part of the ASCII encoding (128 characters) has moved to UTF-8, which allows you to "spend" only 1 byte on their representation, while maintaining the universality of the encoding, for which everything was started.
So, if the first 128 characters are encoded with 1 byte, then all other characters are already encoded with 2 bytes or more. In particular, each Cyrillic character is encoded with exactly 2 bytes.
Thus, we got a universal encoding that allows us to cover all possible characters that need to be displayed without "heavier" files unnecessarily.
With BOM or without BOM?
If you have worked with text editors(by code editors), for example Notepad++, phpDesigner, rapid PHP etc., then they probably paid attention to the fact that when setting the encoding in which the page will be created, you can usually choose 3 options:
ANSI
-UTF-8
- UTF-8 without BOM


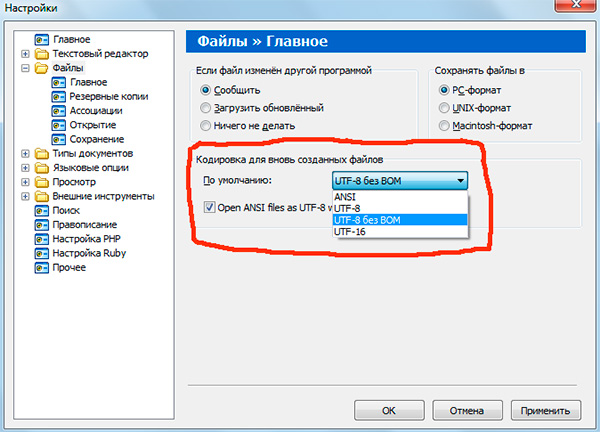
I will say right away that it is always worth choosing last option - UTF-8 without BOM.
So what is BOM and why don't we need it?
BOM stands for Byte Order Mark. This is a special Unicode character used to indicate endianness. text file. According to the specification, its use is optional, but if BOM is used, it must be set at the beginning of the text file.
We will not go into the details of the work BOM. For us, the main conclusion is the following: using this service character together with UTF-8 prevents programs from reading the encoding normally, resulting in script errors.
ANSI is a character display standard developed by the American National Standards Institute (code 1251). The ANSI standard uses only one byte to represent each character, and is therefore limited to a maximum of 256 characters, including punctuation. Codes 32 to 126 follow the ASCII standard. ASCII (code 688) was used in DOS, ANSI is used in Windows.
Literature
Arkhangelsky A.Ya. Programming in C++ Builder6. Ed. BINOM, 2004.
Arkhangelsky A.Ya. C++Builder6. Reference manual. Moscow, Ed. BINOM, 2004.
Kimmel P. Borland C++5 "BHV-St. Petersburg, 2001.
Klimova L.M. C++ Practical programming. Solution of typical tasks. "KUDITS-IMAGE", M.2001.
Kultin N. С/С++ in tasks and examples. St. Petersburg "BHV-Petersburg", 2003.
Pavlovskaya T.A. C/C++ Programming in a high-level language. Peter, Moscow-St. Petersburg-… 2005
Pavlovskaya T.A., Shchupak Yu.A. C++. Object-oriented programming. Workshop. SPb., Peter, 2005.
Podbelsky V.V. C++ language Finance and statistics, Moscow, 2003.
Polyakov A.Yu., Brusentsev V.A. Methods and algorithms computer graphics in examples in Visual C++. SPb BHI-Petersburg, 2003
Savitch W. Language C++ course of object-oriented programming. Williams Publishing House. Moscow-St. Petersburg-Kyiv, 2001
Wellin S. How Not to Program in C++. "Peter". Moscow-St. Petersburg-Nizhny Novgorod-Voronezh-Novosibirsk-Rostov-on-Don-Yekaterinburg-Samara-Kyiv-Kharkov-Minsk, 2004.
Shieldt G. Complete reference in C++. Ed. House "Williams" Moscow-St. Petersburg-Kyiv, 2003.
Schildt G. Self-tutor C/C++. St. Petersburg, BHV-Petersburg, 2004.
Schildt G. Programmer's Guide to C/C++ Ed. House "Williams" Moscow-St. Petersburg-Kyiv, 2003.
Shimanovich.L. С/С++ in examples and tasks. Minsk, New knowledge, 2004.
Stern V. Fundamentals of C++. Methods of software engineering. Ed. Lori.
Why is garbage displayed instead of Russian letters in the console application?
and right! The text of the program you typed in your native editor visual studio, using code page 1251, and text output in the console application is using code page 866. What to do with this disgrace? As you know, from any stalemate there are at least 3 exits. Let's consider them in order.
Exit 1
Type the text of the program in the editor of any console file manager.
But what about syntax highlighting, displaying help on the selected function using F1, and other little charms that brighten up the bleak life of a simple programmer? No, this is not an option for us.
Exit 2
If you started writing a console program from scratch, it may suit you. Let's rewrite our little masterpiece like this:
|
#include "stdafx.h" #include "windows.h" int main(int argc, char* argv) char s="Hello everyone!"; printf("%s\n", s); |
The keyword here is CharToOem - it is this function that will convert our string to the desired code page. With the output of our program, everything is fine now.
But the next question arises - what to do if you need to recompile your old 100,000-line DOS program written in Borland C++ 3.1 into a Windows console application, in which such a situation occurs in every second line. But you still have to adjust it to the MS compiler, and you also want to optimize a couple of pieces of code ...
Here it probably makes sense to use the knight's move, in the sense