…Although the syntax of HTML is relatively simple to learn,…there"s, still a lot of elements, attributes and…other concepts that you"re going to need to learn and keep track of.…While this course is intended to introduce you to the essentials of HTML, it"s…really not designed to teach you every single element and attribute available.…So with that in mind, I want to give you a couple of online HTML resources,…that can really help you as you begin learning HTML, and…can serve as valuable references later on, as you"re authoring your own pages.…Now we"re going to start, at the specifications themselves.…
And this is something, two documents that you should definitely have bookmarked.…So, this is the W3Cs version of HTML5.…You can see they have a latest Publisher Version.…You can go see the Editor"s Draft,…if you want to see what "s coming down, down the pipe.…And, this is pretty large.…If I scroll down, you can see that here "s just the Table of Contents.…And I"m not even going to scroll through all of them.…
Resume Transcript Auto-Scroll
Updated
3/30/2017Released
3/16/2015HTML is the programming language that powers the web. And like any language, once you master it, you can begin to create your own content, whether that"s simple websites or complex web applications. This course provides an in-depth look at the essentials: the syntax of HTML and best practices for senior staff author James Williamson reviews the structure of a typical HTML document, and shows how to section pages and format your content with HTML.Plus, learn how to create links and lists, and find out how HTML works with CSS and JavaScript to create rich, engaging user experiences.
Topics include:
- Why is HTML important?
- Exploring an HTML document
- Formatting content
- Display images
- Using nav, article, and div elements
- Linking to pages and downloadable content
- Creating lists
- Controlling styling (fonts, colors, and more)
- Writing basic scripts
: I always wanted to understand this, but its significance was so small that there was always a reason not to do it :)
And you were wondering: URL - what is it?
I always come across this, but I still didn’t want to understand the difference between the terms URI, URL, URN, and then suddenly a post (unfortunately, it has already sunk into oblivion), I decided - I’ll read it myself, and tell others, although, as mentioned above, nothing will change from this, but I sometimes like to spell, so read the sensible translator:
Have you ever paid attention to the address bar in your browser? What's this? URI, URL or URN? Many of us do not distinguish between URI, URL, URN, and some of us have never even heard of the terms URI and URN, everyone just uses the term URL. Let's try to figure this out together.
Explanation of abbreviations
URI - Uniform Resource Identifier (uniform identifier resource)
URL - Uniform Resource Locator (unified location finder resource)
URN - Uniform Resource Name (uniform name resource)
Attention, here the truth lies in the little things, but so far nothing is clear, some kind of mess. Let's go further.
Definition
URI: Indicates the name and address of a resource on the web. Generally divided into URL and URN, so URL and URN are the components of a URI.
URL: The address of some resource on the web. The URL defines the location of the resource and how to access it.
URN: The name of some resource in the web. The point of a URN is that it only defines the name of a specific item that can be found in multiple specific places.
There is nothing better than a concrete example
URI = http://site/2009/09/uri-url-urn.html
URL = http://site
URL=/2009/09/uri-url-urn.html
Summing up
URI is the concept of an abstract identifier, while URL and URN are concrete implementations of addresses and names.
I hope everything is clear to everyone. Be smart!
The perception of each of us is individual, therefore - argue and read the discussions in the comments to the article, there are a lot of interesting things.
As a rule, many webmasters upload their sites to the host immediately after they are created. At the same time, they mostly focus on the correctness of the meaning of the text content, rather than on the correctness of the internal code of the pages.
Site Validation
But there are other factors that can and do affect the position of the site. And they include, among other things, technical factors. Well, the validation of the site also belongs to the technical ones. So what is it?
If a in simple terms, then site validation is a check of the site code for technical compliance and errors. Well, for example, you forgot to use the closing tag - /html. In the latest HTML5, visually nothing will change. However, this is a code error.
When writing code, other errors are possible. And again, modern language hyper markup will endure a lot. For example, "forgetting" the closing tag /head. Again, you won't see the difference. But she is))
In fact, when writing a website, there can be quite a lot of mistakes. And worse, some of these errors may also show up visually. Well, maybe the blocks will float, maybe alignment, or maybe something else. Potential errors, thousands. And not all of them are striking.
What is the danger?
Well, it would seem, well, what's wrong with that? Yes, it must be said that often such errors are not visible. Or rather, invisible to humans. But the pages of our site can be visited not only by people, but also by search spiders that completely scan the site. And every error that they find on the site, they transmit to the servers of search engines such as Yandex or Google.
And search engines, in turn, seeing that the site has a lot of code errors, may well conclude that the site is bad. And that means they will not raise it in the search. Well, this will already mean that goodbye visitors from the search.
Yes, it must be admitted that a certain pessimization of the site due to validation errors is quite rare. But this is quite possible, which means that validation must be worked on. And what needs to be done for this? Of course, the first step is to find the errors.
But since manually this is a very time-consuming and unreliable business, then to search for errors, they use special services, the so-called "Validators".
Validator Markup Validation Service.
This service checks the correctness of HTML and XHTML codes, which are the basis of most pages when creating almost any site, and determine its internal structure. This validator service can be accessed by following the link http://validator.w3.org
But there is a prerequisite here, which also applies to other validators: the checked site or its checked pages must be uploaded to the hosting. Otherwise, the validator will not "know" the site address and will not be able to check anything. Now you can already consider how to work on this validator.
After entering the page of this service, its entire functional picture will be displayed. But most of what is depicted and written does not apply to the main check, and all your attention should be paid only to the input window for the address of the page being checked:
That's exactly where you need to start.
Actually, checking the validation of a site is extremely simple, like our entire mortal world: in the address window of the service, you need to write the site address, i.e. its URL and then click "Check". After such a simple action, the validator will “puff” for a few seconds and issue the following:
This means that there are no errors in the page code and you can be absolutely calm.
But there may also be such an undesirable option:

This is already worse and means that there are some errors in the internal code of the page being checked. However, this is not fatal at all: you just need to scroll the page below and all the errors found during the verification process will be written in detail there.

In addition, the validator will not only list the errors found, but also show exactly on which line of the internal code these errors are located. So you won't have to look for them for a long time. Here, without exaggerating anything, we can firmly say that this validor works perfectly.
But that's not all: the validator not only indicates the location of the detected code error, but also gives fairly complete recommendations on how to eliminate these errors. Of course, for this you do not have to be lazy and carefully read everything written.
As a short and generalized conclusion, we can say the following:
- this validator service works great and can check the site very quickly.
- Well, a small but very nice addition: site validation is free of charge.
- Now we can move on to the next step: this is checking the CSS code.
CSS Validation Service
In general, this is the second function of the above service, but it is “sharpened” not for checking HTML and XHTML code, but specifically for checking the correctness of the code css style located on the outer table. And to get to the service page, you need to follow the link http://jigsaw.w3.org/css-validator .
By the way, here it is worth noting something pleasant: checking on this service is absolutely free. So do not pull money out of your wallet - let it lie until the right moment. However, let's move on to the methodology of working on this second service.
In general, all work on the CSS validator is absolutely identical to checking for code cleanliness. Therefore, there is no need to provide a separate image of the address bar of the validator. Just a little lower we will briefly consider the order of the check itself and that's it.
For this you need to address bar write URL CSS tables, such as "http://my site/style.css" and then press the button with the Russian inscription "Check". Accordingly, this validator will also “puff” for a few seconds and give the desired result:
This means that the CSS table is written correctly and no errors were found in it.
And here there is also a pleasant surprise: if you scroll down the page a little lower, then the optimized code for your CSS table will be written there, from which all unnecessary inscriptions will be removed and all code tags will be arranged in the sequence that meets the optimal working requirements of all search engines. All that remains is to copy this perfect code sample and paste it into the CSS table.
It is quite possible that something like this could happen:

This means that some errors were found in the CSS code, but you should not be afraid of this at all. Just below that red line, the validator will tell you exactly which tag is misspelled. It remains only to find these tags in the style sheet and make the necessary corrections.

And of course, after that, upload the corrected style sheet to the host and, if there is a green line, you can happily copy the optimized CSS table style code. It is quite clear that then it is best to change old code to a new and optimized one.
Brief summary.
The two most basic and mandatory website validation checks have been discussed above. Without these checks, you should not even open indexing for search engines in robots.txt Otherwise, the site may be ignored for indexing search engines and will be considered defective with appropriate sanctions.
To prevent this from happening, you need to spend just a few minutes to be absolutely calm and completely confident in the technical condition of your site and all its pages. Of course, it is also necessary to make additional checks of links and anchors, the visibility of the site on mobile devices and parameters of other codes. Only then can the site be considered ready for its full functioning and for successful and fast promotion in TOP.
I would like to say in advance that all other checks are as quick and simple as those discussed above - you just need to carefully read the procedure for working with the validator.
Added on 04/19/2018
Common Validity Errors When Validating HTML Code
Decided to update the article. HTML errors codes that are often found on sites. In any case, I had a lot of them)). The validator highlights errors in yellow.
1) Error: Character reference was not terminated by a semicolon.

Error: the character was not interrupted by a semicolon - accordingly, it must be added.
2) Warning: Section lacks heading. Consider using h2-h6 elements to add identifying headings to all sections.
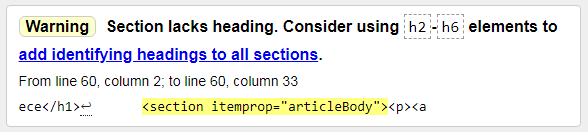
Warning: This section has no title. Consider using h2-h6 elements to add identifying headings to all sections. Everything is clear here, you need to add at least one subtitle. This is not even a mistake, but a recommendation.
3) Error: Element noindex not allowed as child of element p in this context.
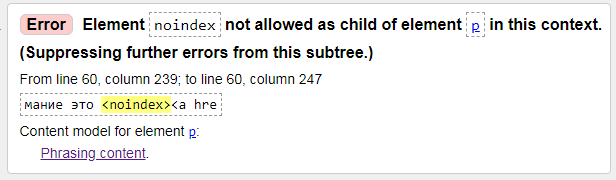
Error: noindex element not allowed as child element p element in this context. (Suppress further errors from this subtree.)
The solution is simple, you need to comment out the noindex tag, the view will look like this:
4) Error: The center element is obsolete.
Error: the "center" tag is outdated - it must be replaced, if we are talking about img, then you can use the align attribute. If something else is centered, then replace it with a div.
5) An img element must have an alt attribute, except under certain

Error: The img element must have an alt attribute - everything is clear here, you need to add an alt attribute, even if it is empty, the error will go away.
6) The width attribute on the td element is obsolete. Use CSS instead.
Error: Attribute 'width' on element 'td' is deprecated

7) The type attribute is unnecessary for javascript resources

Error: The type attribute is not needed for javascript resources. The solution is simply to remove everything unnecessary and leave only the “script” tag.
8) The align attribute on the img element is obsolete.

Error: The align attribute on the img element is deprecated. Make image alignment divs.
The ResourceBundle.Control class has a set of external methods that are called by the ResourceBundle.getBundle() method when searching for and loading bundles. Once you've created your Control class, you can change the default loading and caching behavior.
In this case, you need to create an implementation of two methods of the Control class: getFormats() and newBundle() . The getFormats() method is responsible for maintaining XML format, and newBundle() operates on a bundle of resources. The base Control class has helper methods for converting base set names to actual resource names.
This implementation of the ResourceBundle.Control class includes a subclass of XMLResourceBundle . This subclass is used to load data from XML file and using them in the ResourceBundle method.
The following is a description of the Control class and an implementation of the ResourceBundle method:
import java.io.*;
import java.net.*;
import java.util.*;
Public class XMLResourceBundleControl extends ResourceBundle.Control(
private static String XML = "xml" ;
Public List getFormats(String baseName ) (
return Collections.singletonList(XML) ;
}
Public ResourceBundle newBundle( String baseName, Locale locale,
String format, ClassLoader loader, boolean reload)
throws IllegalAccessException, InstantiationException, IOException{
if ((baseName == null ) || (locale == null ) || (format == null )
|| (loader == null )) (
throw new NullPointerException();
}
ResourceBundle bundle = null ;
if (format.equals(XML))(
String bundleName = toBundleName(baseName, locale ) ;
String resourceName = toResourceName(bundleName, format ) ;
url= loader.getResource(resourceName) ;
if (url != null ) (
URLConnection connection = url.openConnection()
;
if (connection != null ) (
if (reload) (
connection.setUseCaches(false) ;
}
InputStream stream = connection.getInputStream()
;
if (stream != null ) (
BufferedInputStream bis = new BufferedInputStream(
stream);
bundle = new XMLResourceBundle(bis) ;
bis.close();
}
}
}
}
return bundle;
}
Private static class XMLResourceBundle extends ResourceBundle(
private Properties props;
XMLResourceBundle(InputStream stream ) throws IOException(
props = new Properties();
props.loadFromXML(stream) ;
}
Protected Object handleGetObject (String key ) (
return props.getProperty(key) ;
}
Public Enumeration getKeys()(
Set handleKeys = props.stringPropertyNames()
;
return Collections. enumeration (handleKeys ) ;
}
}
Public static void main(String args ) (
("Test2" ,
new XMLResourceBundleControl()) ;
string= bundle.getString("HelpKey" ) ;
System.out.println ("HelpKey: " + string ) ;
}
}
This implementation includes a three-line test program:
ResourceBundle bundle = ResourceBundle.getBundle("Test2", new XMLResourceBundleControl()) ;
String string = bundle.getString("HelpKey" ) ;
System.out.println ("HelpKey: " + string ) ;
The most interesting here is the first line. You need to pass your Control to the getBundle() method. After that, you can use the set as in any other case.
The following is an example XML file Test2.xml:
http://java.sun.com/dtd/properties.dtd"
>
The result of executing the XMLResourceBundleControl program will be:
> java XMLResourceBundleControl HelpKey: Help
The above implementation does not use the getTimeToLive() and needsReload() methods:
public long getTimeToLive( String baseName, Locale locale)
public boolean needsReload( String baseName,
locale,
string format,
class loader,
resource bundle,
long loadTime )
The getTimeToLive() method returns the lifetime for resource bundles created with ResourceBundle.Control . Resource sets are cached to speed up the reload process. Thus, when reloading a set, it will be in the cache. A positive time-to-live value will set, in milliseconds, how long the set will remain in the cache without revalidation. The default value returned by the getTimeToLive() method is TTL_NO_EXPIRATION_CONTROL , which disables cache expiration checking. If you don't want to cache the set, then return TTL_DONT_CACHE . If the return value is 0, then the bundle is cached, but it is checked every time the getBundle() method is called. To clear the cache, call the static clearCache() method of the ResourceBundle class. It has an optional ClassLoader argument that allows you to clear caches created by a specific loader.
The needsReload() method determines whether the cached set needs to be reloaded. A value of true means that the set needs to be reloaded, and false that it does not need to be reloaded. You can control whether a resource set needs to be reloaded by overloading the needsReload() method. For example, if you want the resource set to always be reloaded, the needsReload() method should always return true . In this case, the getTimeToLive() method must always return the value 0. Otherwise, the set will persist longer than expected.
For getting additional information For information about the improvements to Mustang's internationalization processes, you can refer to John Okoner, Sun Software Developer's blog at