Vyhledávací systém Google (www.google.com) nabízí mnoho možností vyhledávání. Všechny tyto funkce jsou neocenitelným vyhledávacím nástrojem pro začínajícího uživatele internetu a zároveň ještě mocnější zbraní invaze a ničení v rukou lidí se zlými úmysly, mezi které patří nejen hackeři, ale i nepočítačové zločince. a dokonce i teroristé.
(9475 zobrazení za 1 týden)
Denis Batrankov
denisNOSPAMixi.ru
Pozornost:Tento článek není návodem k akci. Tento článek je napsán pro vás, správce WEB serveru, abyste ztratili falešný pocit, že jste v bezpečí, a konečně pochopili záludnost tohoto způsobu získávání informací a pustili se do ochrany vašeho webu.
Úvod
Například jsem našel 1670 stránek za 0,14 sekundy!
2. Zadáme další řádek, například:
inurl:"auth_user_file.txt"o něco méně, ale to už stačí pro bezplatné stažení a pro hádání hesel (pomocí stejného John The Ripper). Níže uvedu několik dalších příkladů.
Musíte si tedy uvědomit, že vyhledávač Google navštívil většinu internetových stránek a uložil informace na nich obsažené do mezipaměti. Tyto informace uložené v mezipaměti vám umožňují získat informace o webu a obsahu webu bez přímého spojení s webem, stačí se ponořit do informací, které jsou interně uloženy společností Google. Navíc, pokud informace na webu již nejsou dostupné, mohou být informace v mezipaměti stále zachovány. K této metodě stačí znát nějaký klíč Slova Google. Tato technika se nazývá Google Hacking.
Poprvé se informace o Google Hacking objevily na mailing listu Bugtruck před 3 lety. V roce 2001 toto téma nastolil francouzský student. Zde je odkaz na tento dopis http://www.cotse.com/mailing-lists/bugtraq/2001/Nov/0129.html. Uvádí první příklady takových žádostí:
1) Index /admin
2) Index /hesla
3) Index /mail
4) Index / +banques +filetype:xls (pro Francii...)
5) Index / +passwd
6) Index souboru/password.txt
Toto téma vyvolalo velký hluk v anglické části internetu poměrně nedávno: po článku Johnnyho Longa zveřejněném 7. května 2004. Pro úplnější studium Google Hacking vám doporučuji přejít na stránky tohoto autora http://johnny.ihackstuff.com. V tomto článku vás chci jen informovat.
Kdo to může použít:
- Novináři, špióni a všichni lidé, kteří rádi strkají nos do cizích věcí, toho mohou využít k hledání kompromitujících důkazů.
- Hackeři hledající vhodné cíle pro hackování.
Jak Google funguje.
Chcete-li pokračovat v konverzaci, dovolte mi připomenout některá klíčová slova používaná v dotazech Google.
Hledejte pomocí znaménka +
Google podle něj nedůležitá slova z vyhledávání vyloučí. Například tázací slova, předložky a členy v anglický jazyk: například are, of, where. Zdá se, že v ruštině Google považuje všechna slova za důležitá. Pokud je slovo z vyhledávání vyloučeno, pak o něm Google píše. Aby Google mohl začít vyhledávat stránky s těmito slovy, musíte před ně přidat znaménko + bez mezery před slovo. Například:
eso + základny
Hledat podle znamení -
Pokud Google najde velké množství stránek, ze kterých chcete vyloučit stránky s určitými tématy, můžete Google donutit, aby hledal pouze stránky, které neobsahují určitá slova. Chcete-li to provést, musíte tato slova označit tak, že před každé dáte znak - bez mezery před slovem. Například:
rybaření - vodka
Hledejte pomocí znaku ~
Možná budete chtít vyhledat nejen zadané slovo, ale také jeho synonyma. Chcete-li to provést, uveďte před slovo symbol ~.
Nalezení přesné fráze pomocí dvojitých uvozovek
Google hledá na každé stránce všechny výskyty slov, která jste napsali do řetězce dotazu, a nezáleží mu na relativní pozici slov, hlavní je, že všechna zadaná slova jsou na stránce ve stejnou dobu ( toto je výchozí akce). Chcete-li najít přesnou frázi, musíte ji dát do uvozovek. Například:
"knižní zarážka"
Chcete-li mít alespoň jedno ze zadaných slov, musíte zadat logická operace výslovně: NEBO. Například:
bezpečnost knihy NEBO ochrana
Kromě toho můžete použít znak * ve vyhledávacím řetězci k označení libovolného slova a. reprezentovat jakoukoli postavu.
Hledání slov pomocí dalších operátorů
Existovat vyhledávací operátory, které jsou uvedeny ve vyhledávacím řetězci ve formátu:
operátor:hledaný_term
Mezery vedle dvojtečky nejsou potřeba. Pokud za dvojtečku vložíte mezeru, zobrazí se chybová zpráva a před ní je Google použije jako pravidelný řetězec Pro vyhledávání.
Existují skupiny dalších operátorů vyhledávání: jazyky - uveďte, v jakém jazyce chcete vidět výsledek, datum - omezte výsledky za poslední tři, šest nebo 12 měsíců, výskyty - uveďte, kde v dokumentu je třeba hledat řetězec: všude, v názvu, v URL, doménách - prohledat zadaný web nebo naopak vyloučit z vyhledávání, bezpečné vyhledávání - zablokovat weby obsahující zadaný typ informací a odstranit je ze stránek s výsledky vyhledávání.
Některé operátory však nepotřebují další parametr, například dotaz " cache: www.google.com" lze volat jako úplný vyhledávací řetězec a některá klíčová slova naopak vyžadují hledané slovo, například " site:www.google.com nápověda". Ve světle našeho tématu se podívejme na následující operátory:
Operátor |
Popis |
Vyžaduje doplňkový parametr? |
hledat pouze stránky uvedené v hledaném výrazu |
||
hledat pouze v dokumentech typu search_term |
||
najít stránky obsahující hledaný výraz v názvu |
||
najít stránky obsahující všechna slova search_term v názvu |
||
najít stránky obsahující ve své adrese slovo search_term |
||
najít stránky obsahující všechna slova search_term v jejich adrese |
Operátor web: omezuje vyhledávání pouze na zadaný web a můžete zadat nejenom Doménové jméno ale také IP adresu. Zadejte například:
Operátor typ souboru: omezuje vyhledávání na soubory určitého typu. Například:
Od data zveřejnění článku může Google vyhledávat do 13 různé formáty soubory:
- Adobe Portable Document Format (pdf)
- Adobe PostScript (ps)
- Lotus 1-2-3 (týden 1, týden 2, týden 3, týden 4, týden 5, týden, týden, týden)
- Lotus Word Pro (lwp)
- MacWrite (mw)
- Microsoft Excel(xls)
- Microsoft PowerPoint (ppt)
- Microsoft Word(doc)
- Microsoft Works (wks, wps, wdb)
- Microsoft Write (wri)
- Formát RTF (rtf)
- Záblesk rázové vlny(swf)
- Text (ans, txt)
Operátor odkaz: zobrazí všechny stránky, které ukazují na zadanou stránku.
Vždy musí být zajímavé vidět, kolik míst na internetu o vás ví. Zkoušíme:
Operátor mezipaměti: zobrazuje verzi webu uloženou v mezipaměti Google tak, jak vypadala google nejnovější navštívil tuto stránku jednou. Vezmeme všechny často se měnící stránky a podíváme se:
Operátor titul: hledá zadané slovo v názvu stránky. Operátor allintitle: je rozšíření - hledá všech zadaných pár slov v názvu stránky. Porovnat:
intitle:let na mars
intitle:flight intitle:on intitle:mars
allintitle:let na mars
Operátor inurl: způsobí, že Google zobrazí všechny stránky obsahující zadaný řetězec v adrese URL. allinurl: hledá všechna slova v URL. Například:
allinurl:acid_stat_alerts.php
Tento příkaz je užitečný zejména pro ty, kteří nemají SNORT – alespoň vidí, jak to funguje na reálném systému.
Metody hackování Google
Zjistili jsme tedy, že pomocí kombinace výše uvedených operátorů a klíčových slov může začít sbírat každý nezbytné informace a hledat zranitelnosti. Tyto techniky jsou často označovány jako Google Hacking.
mapa stránek
Pomocí příkazu site: můžete zobrazit všechny odkazy, které Google na webu našel. Stránky, které jsou dynamicky vytvářeny skripty, se obvykle neindexují pomocí parametrů, takže některé weby používají filtry ISAPI, aby odkazy nebyly ve tvaru /článek.asp?num=10&dst=5, ale s lomítky /článek/abc/num/10/dst/5. To se provádí, aby bylo zajištěno, že web je obecně indexován vyhledávači.
Zkusme to:
stránky: www.whitehouse.gov whitehouse
Google si myslí, že každá stránka na webu obsahuje slovo whitehouse. To je to, co používáme k získání všech stránek.
Existuje také zjednodušená verze:
web: whitehouse.gov
A nejlepší na tom je, že soudruzi z whitehouse.gov ani nevěděli, že jsme se podívali na strukturu jejich webu a dokonce se podívali i do stránek uložených v mezipaměti, které si Google pro sebe stáhl. Toho lze využít ke studiu struktury webů a prohlížení obsahu, aniž by si toho člověk všiml.
Výpis souborů v adresářích
WEB servery mohou zobrazovat seznamy adresářů serverů namísto obvyklých HTML stránky. To se obvykle provádí, aby uživatelé museli vybrat a stáhnout konkrétní soubory. V mnoha případech však správci nemají v úmyslu zobrazovat obsah adresáře. K tomu dochází v důsledku nesprávné konfigurace serveru nebo jeho nedostatku domovská stránka v adresáři. Díky tomu má hacker šanci najít v adresáři něco zajímavého a použít to pro své účely. K nalezení všech takových stránek si stačí všimnout, že všechny obsahují v názvu slova: index of. Protože ale index slov neobsahuje pouze takové stránky, musíme dotaz upřesnit a vzít v úvahu klíčová slova na samotné stránce, takže dotazy jako:
intitle:index.nadřazeného adresáře
intitle:index.of name size
Vzhledem k tomu, že většina výpisů v adresáři je záměrná, můžete mít napoprvé potíže najít nesprávně umístěné výpisy. Ale alespoň už můžete použít výpisy k definování WEB verze serveru, jak je popsáno níže.
Získání verze WEB serveru.
Znalost verze WEB serveru je vždy užitečná před zahájením jakéhokoli hackerského útoku. Opět díky Google je možné získat tyto informace bez připojení k serveru. Pokud se pozorně podíváte na výpis adresáře, uvidíte, že je tam zobrazen název WEB serveru a jeho verze.
Apache1.3.29 – ProXad Server na trf296.free.fr Port 80
Zkušený správce může tyto informace změnit, ale zpravidla je to pravda. K získání těchto informací tedy stačí odeslat žádost:
intitle:index.of serveru.at
Abychom získali informace pro konkrétní server, upřesníme požadavek:
intitle:index.of server.at site:ibm.com
Nebo naopak, hledáme servery běžící na konkrétní verzi serveru:
intitle:index.of Apache/2.0.40 Server at
Tuto techniku může hacker použít k nalezení oběti. Pokud má například exploit pro určitou verzi WEB serveru, může jej najít a vyzkoušet stávající exploit.
Verzi serveru můžete také získat tak, že se podíváte na stránky, které jsou standardně nainstalovány při instalaci nové verze WEB serveru. Chcete-li například zobrazit testovací stránku Apache 1.2.6, stačí napsat
intitle:Test.stránky.pro.Apache to.fungovalo!
Navíc některé Operační systémy během instalace okamžitě nainstalují a spustí WEB server. Někteří uživatelé si to však ani neuvědomují. Samozřejmě, pokud vidíte, že někdo neodstranil výchozí stránku, je logické předpokládat, že počítač nebyl podroben žádné konfiguraci a je pravděpodobně zranitelný vůči útokům.
Zkuste hledat stránky IIS 5.0
allintitle:Vítejte ve Windows 2000 Internet Services
V případě IIS můžete určit nejen verzi serveru, ale také verzi Windows a Service Pack.
Dalším způsobem, jak zjistit verzi WEB serveru, je vyhledat manuály (stránky nápovědy) a příklady, které lze standardně nainstalovat na web. Hackeři našli poměrně dost způsobů, jak tyto komponenty využít k získání privilegovaného přístupu na web. To je důvod, proč musíte tyto součásti odstranit na místě výroby. Nemluvě o tom, že přítomností těchto komponent můžete získat informace o typu serveru a jeho verzi. Najdeme například příručku Apache:
inurl:manuální moduly direktiv Apache
Použití Google jako CGI skeneru.
CGI skener nebo WEB skener je nástroj pro vyhledávání zranitelných skriptů a programů na serveru oběti. Tyto nástroje potřebují vědět, co mají hledat, k tomu mají celý seznam zranitelných souborů, například:
/cgi-bin/cgiemail/uargg.txt
/random_banner/index.cgi
/random_banner/index.cgi
/cgi-bin/mailview.cgi
/cgi-bin/maillist.cgi
/cgi-bin/userreg.cgi
/iissamples/ISSamples/SQLQHit.asp
/SiteServer/admin/findvserver.asp
/scripts/cphost.dll
/cgi-bin/finger.cgi
Každý z těchto souborů můžeme najít pomocí Google, navíc pomocí slov index of nebo inurl s názvem souboru ve vyhledávací liště: můžeme najít stránky se zranitelnými skripty, například:
allinurl:/random_banner/index.cgi
S dalšími znalostmi by hacker mohl zneužít zranitelnost skriptu a využít tuto zranitelnost k tomu, aby skript obsluhoval jakýkoli soubor uložený na serveru. Například soubor s hesly.
Jak se chránit před hackery přes Google.
1. Nenahrávejte důležitá data na WEB server.
I když jste data zveřejnili dočasně, můžete na ně zapomenout nebo někdo bude mít čas tato data najít a vzít, než je vymažete. Nedělej to. Existuje mnoho dalších způsobů přenosu dat, které je chrání před krádeží.
2. Zkontrolujte svůj web.
Pomocí popsaných metod prozkoumejte své stránky. Pravidelně na svém webu kontrolujte nové metody, které se objevují na webu http://johnny.ihackstuff.com. Pamatujte, že pokud chcete své akce automatizovat, musíte získat zvláštní povolení od společnosti Google. Pokud si pozorně přečtete http://www.google.com/terms_of_service.html, pak se zobrazí fráze: Bez předchozího výslovného souhlasu společnosti Google nesmíte do systému Google odesílat automatizované dotazy jakéhokoli druhu.
3. Možná nebudete potřebovat Google k indexování vašeho webu nebo jeho části.
Google vám umožňuje odstranit odkaz na váš web nebo jeho část z jeho databáze a také odstranit stránky z mezipaměti. Kromě toho můžete zakázat vyhledávání obrázků na vašem webu, zakázat zobrazování krátkých fragmentů stránek ve výsledcích vyhledávání Všechny možnosti pro smazání webu jsou popsány na stránce http://www.google.com/remove.html. K tomu musíte potvrdit, že jste skutečně vlastníkem tohoto webu nebo vložit na stránku tagy resp
4. Použijte soubor robots.txt
Je známo že vyhledávače podívejte se do souboru robots.txt v kořenovém adresáři webu a neindexujte ty části, které jsou označeny slovem Zakázat. Pomocí toho můžete zabránit indexování části webu. Chcete-li se například vyhnout indexování celého webu, vytvořte soubor robots.txt obsahující dva řádky:
User-agent: *
zakázat: /
Co se ještě stane
Aby se vám život nezdál jako med, tak na závěr řeknu, že existují stránky, které sledují ty lidi, kteří pomocí výše uvedených metod hledají díry ve skriptech a WEB servery. Příkladem takové stránky je
Aplikace.
Trochu sladké. Vyzkoušejte sami jednu z následujících možností:
1. #mysql dump filetype:sql - hledání výpisů databáze data mySQL
2. Souhrnná zpráva o zranitelnosti hostitele – ukáže vám, jaké zranitelnosti našli ostatní lidé
3. phpMyAdmin běžící na inurl:main.php – toto vynutí zavřít ovládání pomocí panelu phpmyadmin
4. Není určeno k důvěrné distribuci
5. Podrobnosti požadavku na proměnné serveru řídicího stromu
6. Běh v dětském režimu
7. Tuto zprávu vytvořil WebLog
8. intitle:index.of cgiirc.config
9. filetype:conf inurl:firewall -intitle:cvs - možná někdo potřebuje konfigurační soubory firewallu? :)
10. intitle:index.of finance.xls - hmm....
11. intitle:Index chatů dbconvert.exe - icq chat logs
12. intext:Tobias Oetiker dopravní analýza
13. intitle:Statistiky použití pro Generated by Webalizer
14. intitle:statistika pokročilé webové statistiky
15. intitle:index.of ws_ftp.ini - konfigurace ws ftp
16. inurl:ipsec.secrets uchovává sdílená tajemství - Tajný klíč- dobrý nález
17. inurl:main.php Vítejte v phpMyAdmin
18. inurl:server-info Informace o serveru Apache
19. site:edu admin známky
20. ORA-00921: neočekávaný konec SQL příkazu - získat cesty
21. intitle:index.of trillian.ini
22. intitle:Index of pwd.db
23. intitle:index.lid.lst
24. intitle:index.of master.passwd
25.inurl:passlist.txt
26. intitle:Index of .mysql_history
27. intitle:index of intext:globals.inc
28. intitle:index.správců.pwd
29. intitle:Index.of etc stínu
30. intitle:index.secring.pgp
31. inurl:config.php název_dbu dbpass
32. inurl:provést typ souboru:ini
Školicí středisko "Informzaschita" http://www.itsecurity.ru - přední specializované centrum v oblasti vzdělávání informační bezpečnost(Licence Moskevského výboru pro vzdělávání č. 015470, státní akreditace č. 004251). Jediný oprávněný Tréninkové centrum společnosti internetová bezpečnost Systems a Clearswift v Rusku a zemích SNS. Autorizované školicí středisko společnosti Microsoft (specializace zabezpečení). Školicí programy jsou koordinovány se Státní technickou komisí Ruska, FSB (FAPSI). Potvrzení o studiu a vládní dokumenty o profesním rozvoji.
SoftKey je jedinečná služba pro kupující, vývojáře, prodejce a affiliate partnery. Navíc se jedná o jeden z nejlepších online obchodů se softwarem v Rusku, na Ukrajině, v Kazachstánu, který zákazníkům nabízí široký sortiment, mnoho platebních metod, rychlé (často okamžité) vyřízení objednávky, sledování procesu plnění objednávky v osobní sekci, různé slevy z obchodu a výrobců ON.
V článku o jsem se podíval na příklady a kódy pro zobrazení některých doplňkových informačních prvků na stránkách příspěvků: související poznámky, názvy značek/kategorií atd. Podobnou funkcí jsou také odkazy na předchozí a další příspěvky WordPress. Tyto odkazy budou užitečné při navigaci návštěvníků webu a jsou také dalším způsobem. Proto se je snažím přidávat do každého svého projektu.
Při realizaci úkolu nám pomohou 4 funkce, o kterých pojednám níže:
Protože mluvíme o stránce příspěvku, v 99 % případů budete muset upravit soubor šablony single.php(nebo ten, kde vaše téma nastavuje výstupní formát pro jednotlivé články). Funkce se používají ve smyčce. Pokud chcete odstranit další / předchozí příspěvky ve WordPressu, vyhledejte odpovídající kód ve stejném souboru šablony a smažte jej (nebo okomentujte).
funkci next_post_link
Ve výchozím nastavení se generuje odkaz na poznámku, která má novější datum vytvoření bezprostředně po aktuálním (protože všechny příspěvky jsou uspořádány v chronologickém pořadí). Takto to vypadá v kódu a na webu:
Syntaxe funkce:
- formát(řetězec) - definuje obecný formát generovaného odkazu, kde pomocí proměnné % odkazu můžete nastavit nějaký text před a za něj. Ve výchozím nastavení je to pouze odkaz se šipkou: '%link "'
- odkaz(string) — kotva odkazu na další příspěvek ve WordPressu, parametr %title nahrazuje jeho nadpis.
- ve_stejném_termínu(boolean) - určuje, zda budou v práci uvažovány pouze prvky z aktuální kategorie. Platné hodnoty true / false (1 / 0), výchozí je druhá možnost.
- vyloučené_pojmy(řetězec nebo pole) — zadejte ID kategorií blogu, poznámky, z nichž budou vyloučeny z výběru. Pole je povoleno pole(2, 5, 4) nebo zápis do řetězce odděleného čárkami. Užitečné při práci s GoGetLinks, když potřebujete zakázat zobrazování reklamních příspěvků v tomto bloku.
- taxonomie(řetězec) - obsahuje název taxonomie, ze které jsou převzaty následující záznamy, pokud proměnná $in_same_term = true.
Soudě z výše uvedeného snímku obrazovky je jasné, že všechny tyto parametry jsou volitelné. Zde je příklad použití funkce na jednom z mých webů:
(další článek)%link →","%title", FALSE, 152) ?>
Zde nastavím svůj formát pro zobrazení odkazu + vyřadím z výběru všechny prvky patřící do sekce ID = 152.
Pokud potřebujete zobrazit další příspěvek ve stejné kategorii ve WordPressu, bude se vám hodit kód níže (ignoruje sekci ID = 33):
Pokud chcete pracovat pouze s aktuální konkrétní taxonomií, zadejte její název v parametrech (například testimonial):
>", PRAVDA, " ", "posudek"); ?>
funkci previous_post_link
Princip práce s předchozími příspěvky WordPressu je podobný popisu výše, stejně jako syntaxe. Vypadá to takto:
Příslušný kód:
- formát(string) - nastavuje formát, za který je zodpovědná proměnná %link (přidat text/tagy před a za ni). Výchozí hodnota je '% odkaz'.
- odkaz(řetězec) — kotva odkazu, pro vložení názvu typu %title.
- ve_stejném_termínu(boolean) – pokud je true, zobrazí se pouze objekty ze stejné sekce blogu.
- vyloučené_pojmy- odstraňte nepotřebné kategorie, uveďte ID oddělené čárkou (jako řetězec) nebo polem.
- taxonomie(řetězec) – Určuje taxonomii předchozího výběru příspěvku ve WordPressu, pokud je povoleno $in_same_term.
V jednom ze svých blogů používám:
%odkaz", "<< Предыдущая", TRUE, "33"); ?>
Zde uděláme tučné písmo + místo nadpisu prvku se napíše určitá fráze (i když v odkazování je lepší použít nadpis). Jsou zobrazeny pouze objekty aktuální kategorie, kromě objektu s ID = 33.
funkce_post_navigation
Toto řešení kombinuje oba odkazy na předchozí a následující WordPress příspěvky. To se provádí pro pohodlí, nahrazuje volání dvou funkcí jednou. Pokud potřebujete vytisknout HTML kód bez zobrazení, použijte get_the_post_navigation().
Syntaxe_post_navigation je co nejjednodušší:
Kde $args je sada různých volitelných parametrů:
- $prev_text— kotva předchozího odkazu (standardně %title).
- $další_text- podobný textu odkazu, ale k dalšímu příspěvku (původně %title).
- $in_same_term(true/false) - umožňuje zobrazit články pouze z aktuální taxonomie.
- $excluded_terms— vyloučená ID oddělená čárkami.
- $taxonomie— název taxonomie pro výběr, pokud in_same_term = true.
- $screen_reader_text- název celého bloku (standardně - Navigace příspěvku).
Vidíme tedy, že jsou zde stejné proměnné jako v předchozích „jednotlivých“ funkcích previous_post_link, next_post_link: kotvy, výběr podle taxonomií atd. Použitím řešení bude váš kód jen kompaktnější a nemá smysl opakovat stejné parametry dvakrát.
Podívejme se na nejjednodušší situaci, kdy potřebujete zobrazit prvky ze stejné kategorie:
"next: %title", "next_text" => "předchozí: %title", "in_same_term" => true, "taxonomy" => "category", "screen_reader_text" => "Další ke čtení")); ?>
posts_nav_link funkce
Pokud tomu dobře rozumím, dá se použít nejen pro zobrazení v jednom příspěvku, ale i v kategoriích, měsíčních poznámkách atp. To znamená, že v single.php bude zodpovědný za odkazy na předchozí/následující články WordPress a v archivech bude zodpovědný za navigaci na stránce.
Syntaxe pro posts_nav_link je:
- $ sep— oddělovač zobrazený mezi odkazy (dříve::, nyní -).
- $prelabel— text odkazu předchozích prvků (výchozí: « Předchozí stránka).
- $nxtlabel- text pro další stránku / příspěvky (Next Page ").
Tady zajímavý příklad s obrázky místo textových odkazů:
| "
,
" |
", ""); ?>
Jen nezapomeňte nahrát obrázky prev-img.png a next-img.png do adresáře snímky ve vašem . Myslím, že stejným způsobem se přidává další HTML kód, pokud například potřebujete při zarovnávání použít nějaký DIV nebo třídu.
Celkový. U navigace existuje i několik dalších různých funkcí, které v kodexu najdete. Doufám, že tyto jsou víceméně jasné. Pokud jde o posts_nav_link, abych byl upřímný, nejsem si jistý, zda vám umožňuje zobrazit předchozí a následující příspěvky na jedné stránce, protože. Netestoval jsem to, i když je to v popisu uvedeno. Myslím, že v tomto případě je efektivnější a žádoucí použít the_post_navigation, která je novější a má mnohem více parametrů.
Pokud máte nějaké dotazy ohledně navigace mezi příspěvky nebo dodatky, napište níže.
Přijímání soukromých dat nemusí vždy znamenat hackování – někdy jsou zveřejněna ve veřejné doméně. Znalost Nastavení Google a trocha vynalézavosti vám umožní najít spoustu zajímavých věcí – od čísel kreditních karet až po dokumenty FBI.
VAROVÁNÍ
Veškeré informace jsou poskytovány pouze pro informační účely. Redakce ani autor nenesou odpovědnost za případné škody způsobené materiály tohoto článku.Všechno je dnes připojeno k internetu, málo se starají o omezení přístupu. Mnoho soukromých dat se proto stává kořistí vyhledávačů. Spider roboti se již neomezují pouze na webové stránky, ale indexují veškerý obsah dostupný na webu a neustále přidávají důvěrné informace do svých databází. Naučit se tato tajemství je snadné – stačí vědět, jak se na ně zeptat.
Hledání souborů
Ve schopných rukou Google rychle najde vše, co je na webu špatné, jako jsou osobní údaje a soubory pro oficiální použití. Často jsou schované jako klíč pod kobercem: neexistují žádná skutečná omezení přístupu, data jen leží vzadu na webu, kam odkazy nevedou. Poskytuje pouze standardní webové rozhraní Google základní nastavení pokročilé vyhledávání, ale i ty postačí.
Existují dva operátory, které můžete použít k omezení vyhledávání Google na soubory určitého typu: filetype a ext . První nastavuje formát, který vyhledávač určí podle záhlaví souboru, druhý - příponu souboru, bez ohledu na jeho vnitřní obsah. Při vyhledávání v obou případech je třeba zadat pouze příponu. Zpočátku bylo vhodné použít operátor ext v případech, kdy pro soubor neexistovaly žádné specifické formátovací funkce (například pro hledání konfiguračních souborů ini a cfg, které mohou obsahovat cokoli). Nyní se algoritmy Google změnily a mezi operátory není žádný viditelný rozdíl – výsledky jsou ve většině případů stejné.

Filtrování výstupu
Ve výchozím nastavení Google vyhledává slova a obecně jakékoli znaky zadané ve všech souborech na indexovaných stránkách. Rozsah vyhledávání můžete omezit doménou nejvyšší úrovně, konkrétním webem nebo umístěním požadované sekvence v samotných souborech. Pro první dvě možnosti se používá výpis webu, za nímž následuje název domény nebo vybraného webu. Ve třetím případě vám celá sada operátorů umožňuje vyhledávat informace v polích služeb a metadatech. Například allinurl najde specifikované v těle samotných odkazů, allinanchor - v textu poskytnutém značkou , allintitle - v záhlaví stránek, allintext - v těle stránek.
Pro každého operátora existuje lehčí verze s kratším názvem (bez předpony all). Rozdíl je v tom, že allinurl najde odkazy se všemi slovy, zatímco inurl najde pouze odkazy s prvním z nich. Druhé a následující slova z dotazu se mohou objevit kdekoli na webových stránkách. Operátor inurl se také liší od jiného podobného operátoru ve významu - site. První z nich také umožňuje najít libovolnou sekvenci znaků v odkazu na požadovaný dokument (například /cgi-bin/), což je široce používáno pro hledání komponent se známými zranitelnostmi.
Pojďme si to vyzkoušet v praxi. Vezmeme allintextový filtr a přimějeme, aby dotaz vrátil seznam čísel kreditních karet a ověřovacích kódů, jejichž platnost vyprší až po dvou letech (nebo když jejich majitele omrzí krmit všechny v řadě).
Allintext: číslo karty datum vypršení platnosti /2017 cvv 
Když si ve zprávách přečtete, že se mladý hacker „naboural do serverů“ Pentagonu nebo NASA a ukradl utajované informace, pak je to ve většině případů právě tato elementární technika používání Googlu. Předpokládejme, že nás zajímá seznam zaměstnanců NASA a jejich kontaktní údaje. Určitě takový seznam je v elektronické podobě. Pro pohodlí nebo z důvodu nedopatření může ležet i na samotném webu organizace. Je logické, že v tomto případě na něj nebudou žádné odkazy, protože je určen pro interní použití. Jaká slova mohou být v takovém souboru? Alespoň - pole "adresa". Všechny tyto předpoklady je snadné otestovat.

inurl:nasa.gov filetype:xlsx "adresa"

Používáme byrokracii
Takové nálezy jsou příjemnou maličkostí. Opravdu solidní úlovek pochází z podrobnější znalosti Google Webmaster Operators, samotného webu a struktury toho, co hledáte. Když znáte podrobnosti, můžete snadno filtrovat výstup a upřesňovat vlastnosti souborů, které potřebujete, abyste ve zbytku získali opravdu cenná data. Je legrační, že byrokracie zde přichází na pomoc. Vytváří typické formulace, které usnadňují vyhledávání tajných informací, které náhodně unikly na web.
Například razítko Distribution statement, které je povinné v kanceláři amerického ministerstva obrany, znamená standardizovaná omezení distribuce dokumentu. Písmeno A označuje veřejná vydání, ve kterých není nic tajného; B - určeno pouze pro interní použití, C - přísně důvěrné atd. až po F. Samostatně je zde písmeno X, které označuje zvláště cenné informace, které představují státní tajemství nejvyšší úrovně. Takové dokumenty nechť vyhledávají ti, kteří to mají dělat ve službě, a my se omezíme na soubory s písmenem C. Podle DoDI 5230.24 je takové označení přiděleno dokumentům obsahujícím popis kritických technologií, které spadají pod kontrolu exportu. Takto pečlivě střežené informace můžete najít na stránkách v doméně nejvyšší úrovně .mil přidělené americké armádě.
"PROHLÁŠENÍ O DISTRIBUCI C" inurl:navy.mil 
Je velmi výhodné, že v doméně .mil jsou shromažďovány pouze stránky Ministerstva obrany USA a jeho smluvních organizací. Výsledky vyhledávání omezené na doménu jsou výjimečně čisté a názvy mluví samy za sebe. Je prakticky zbytečné pátrat po ruských tajemstvích tímto způsobem: v doménách .ru a .rf vládne chaos a názvy mnoha zbraňových systémů znějí botanické (PP „Kiparis“, samohybná děla „Acacia“) či dokonce báječné (TOS "Pinocchio").

Pečlivým prozkoumáním jakéhokoli dokumentu z webu v doméně .mil můžete zobrazit další značky pro upřesnění vyhledávání. Například odkaz na exportní omezení „Sec 2751“, což je také pohodlné pro vyhledávání zajímavých technických informací. Čas od času je odstraněn z oficiálních stránek, kde se kdysi objevil, takže pokud nemůžete sledovat zajímavý odkaz ve výsledcích vyhledávání, použijte mezipaměť Google (operátor mezipaměti) nebo webovou stránku Internet Archive.
Stoupáme do mraků
Kromě náhodně odtajněných dokumentů z vládních ministerstev občas v mezipaměti Google vyskakují odkazy na osobní soubory z Dropboxu a dalších služeb pro ukládání dat, které vytvářejí „soukromé“ odkazy na veřejně publikovaná data. S alternativními a vlastnoručně vyrobenými službami je to ještě horší. Například následující dotaz najde data všech klientů Verizon, kteří mají nainstalovaný server FTP a aktivně používají směrovač na svém směrovači.
Allinurl:ftp://verizon.net
Takových chytrých lidí je nyní více než čtyřicet tisíc a na jaře 2015 jich bylo řádově více. Místo Verizon.net můžete nahradit jméno jakéhokoli známého poskytovatele a čím slavnější je, tím větší může být úlovek. Prostřednictvím vestavěného FTP serveru můžete vidět soubory na externím disku připojeném k routeru. Obvykle se jedná o NAS pro vzdálenou práci, osobní cloud nebo nějaký druh stahování souborů typu peer-to-peer. Veškerý obsah takových médií je indexován Googlem a dalšími vyhledávači, takže k souborům uloženým na externích discích se dostanete přes přímý odkaz.

Nahlížející konfigurace
Před velkoobchodní migrací do cloudu vládly jako vzdálená úložiště jednoduché FTP servery, které také postrádaly zranitelnost. Mnohé z nich jsou aktuální i dnes. Například oblíbený program WS_FTP Professional ukládá konfigurační data, uživatelské účty a hesla do souboru ws_ftp.ini. Je snadné jej najít a přečíst, protože všechny položky jsou uloženy v prostém textu a hesla jsou po minimálním zmatku zašifrována pomocí algoritmu Triple DES. Ve většině verzí stačí zahodit první bajt.

Dešifrování takových hesel je snadné pomocí nástroje WS_FTP Password Decryptor nebo bezplatné webové služby.

Když mluvíme o hacknutí libovolného webu, obvykle to znamená získání hesla z protokolů a záloh konfiguračních souborů CMS nebo e-commerce aplikací. Pokud znáte jejich typickou strukturu, můžete klíčová slova snadno označit. Řádky jako ty nalezené v ws_ftp.ini jsou extrémně běžné. Například Drupal a PrestaShop mají vždy ID uživatele (UID) a odpovídající heslo (pwd) a všechny informace jsou uloženy v souborech s příponou .inc. Můžete je hledat takto:
"pwd=" "UID=" ext:inc
Odhalujeme hesla z DBMS
V konfiguračních souborech SQL serverů jména a adresy E-mailem uživatelé jsou uloženi jako prostý text a místo hesel se zapisují jejich MD5 hash. Jejich dešifrování, přísně vzato, je nemožné, ale můžete najít shodu mezi známými páry hash-heslo.

Až dosud existují DBMS, které ani nepoužívají hash hesel. Konfigurační soubory kteréhokoli z nich lze jednoduše zobrazit v prohlížeči.
Intext:DB_PASSWORD filetype:env

Se vzhledem na serverech místo oken konfigurační soubory částečně zabíraly registr. V jeho větvích můžete prohledávat úplně stejným způsobem s použitím reg jako typu souboru. Například takto:
Filetype:reg HKEY_CURRENT_USER "Heslo"=
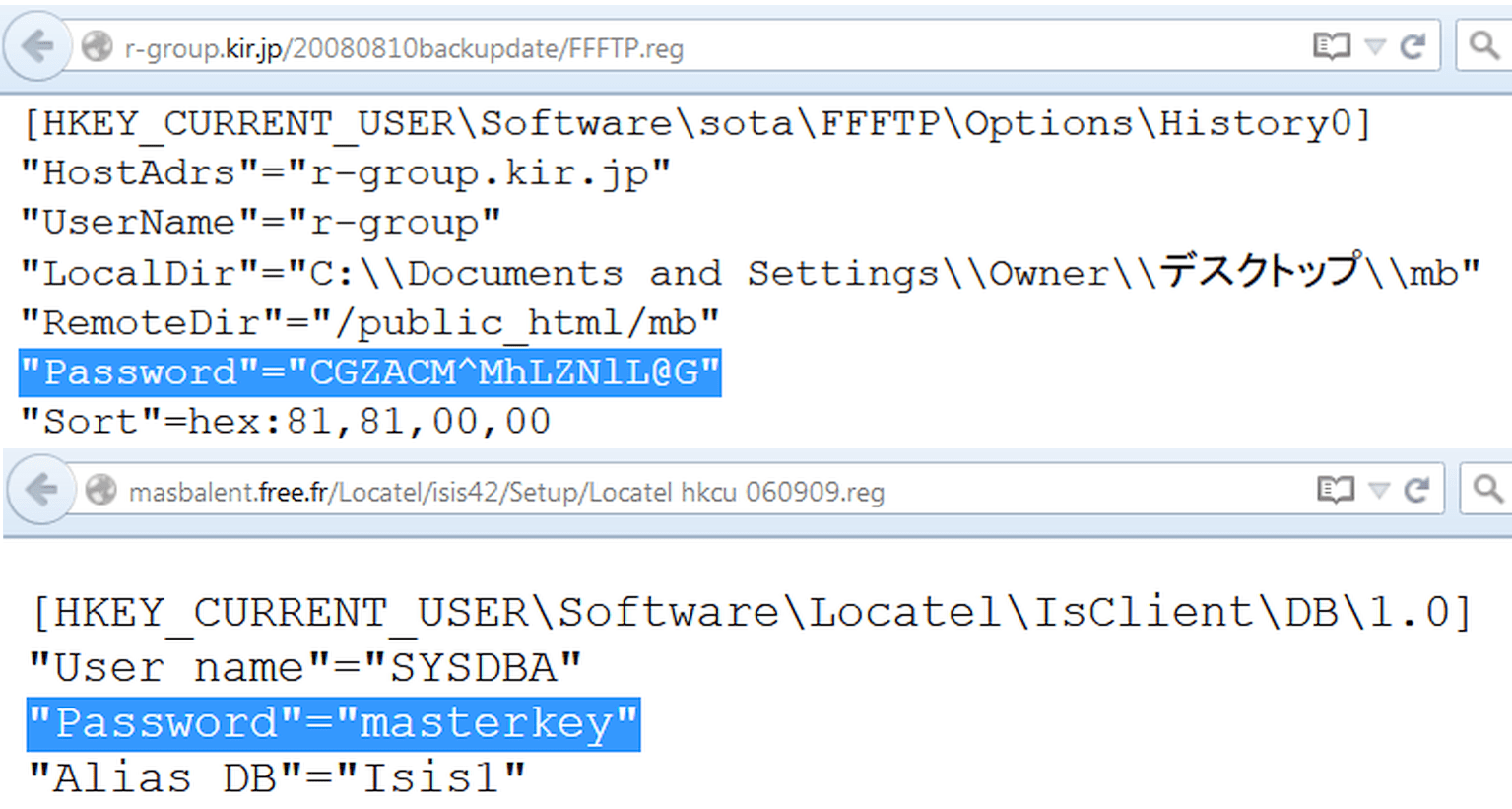
Nezapomeňte na Obvious
Někdy je možné se k utajovaným informacím dostat pomocí náhodného otevření a zachycení v zorném poli údaje google. Ideální možností je najít seznam hesel v nějakém běžném formátu. Uložte informace o účtu do textový soubor, Word dokument nebo elektronické excelové tabulky Mohou jen zoufalci, ale těch je vždy dost.
Filetype:xls inurl:password

Na jedné straně existuje mnoho prostředků, jak takovým incidentům předejít. Je nutné specifikovat adekvátní přístupová práva v htaccess, záplatovat CMS, nepoužívat levé skripty a uzavírat ostatní díry. Existuje také soubor se seznamem vyloučení robots.txt, který vyhledávačům zakazuje indexovat soubory a adresáře v něm uvedené. Na druhou stranu, pokud se struktura robots.txt na některém serveru liší od standardní, pak je okamžitě jasné, co se na něm snaží skrýt.

Seznamu adresářů a souborů na libovolném webu předchází standardní index zápisu. Protože se musí objevit v názvu pro servisní účely, má smysl omezit jeho vyhledávání na operátora intitle. Zajímavé věci lze najít v adresářích /admin/, /personal/, /etc/ a dokonce i /secret/.

Sledujte aktualizace
Relevance je zde nesmírně důležitá: staré zranitelnosti se uzavírají velmi pomalu, ale Google a jeho výsledky vyhledávání se neustále mění. Je dokonce rozdíl mezi filtrem „poslední vteřiny“ (&tbs=qdr:s na konci adresy URL požadavku) a filtrem „v reálném čase“ (&tbs=qdr:1).
Časový rozsah data poslední aktualizace Implicitně je také uveden soubor Google. Prostřednictvím grafického webového rozhraní můžete vybrat jedno z typických období (hodinu, den, týden atd.) nebo nastavit časové období, ale tento způsob není vhodný pro automatizaci.
Podle typu adresní řádek lze jen hádat o způsobu, jak omezit výstup výsledků pomocí konstrukce &tbs=qdr: . Písmeno y za ním určuje limit jednoho roku (&tbs=qdr:y), m ukazuje výsledky za poslední měsíc, w za týden, d za poslední den, h za poslední hodinu, n za minutu, a s pro dej mi sekundu. Nejnovější výsledky, které Google právě oznámil, lze nalézt pomocí filtru &tbs=qdr:1.
Pokud potřebujete napsat ošemetný skript, bude užitečné vědět, že časové období se v Googlu nastavuje v juliánském formátu přes operátor daterange. Například takto můžete najít seznam PDF dokumenty se slovem důvěrné nahrané od 1. ledna do 1. července 2015.
Důvěrný typ souboru: pdf rozsah dat: 2457024-2457205
Rozsah je uveden ve formátu juliánského data bez desetinných míst. Překládat je ručně z gregoriánského kalendáře je nepohodlné. Je jednodušší použít převodník data.
Opět cílení a filtrování
Kromě určení dalších operátorů v vyhledávací dotaz lze je odeslat přímo v těle odkazu. Například vlastnost filetype:pdf odpovídá konstruktu as_filetype=pdf. Je tedy vhodné nastavit jakákoli upřesnění. Řekněme, že výstup výsledků pouze z Honduraské republiky se nastaví přidáním konstrukce cr=countryHN do URL vyhledávání, ale pouze z města Bobruisk - gcs=Bobruisk . Úplný seznam naleznete v sekci pro vývojáře.
Automatizační nástroje Google jsou navrženy tak, aby usnadňovaly život, ale často ještě více komplikují práci. Například město uživatele je určeno IP adresou uživatele prostřednictvím WHOIS. Na základě těchto informací Google nejen vyrovnává zatížení mezi servery, ale také mění výsledky vyhledávání. V závislosti na regionu se pro stejný dotaz dostanou na první stránku různé výsledky a některé z nich se mohou ukázat jako zcela skryté. Cítit se jako kosmopolita a vyhledávat informace z jakékoli země pomůže jeho dvoupísmenný kód za direktivou gl=country . Například kód pro Nizozemsko je NL, zatímco Vatikán a Severní Korea svůj vlastní kód v Googlu nemají.
Výsledky vyhledávání jsou často poseté i po použití několika pokročilých filtrů. V tomto případě je snadné dotaz upřesnit přidáním několika výjimečných slov (každému z nich předchází znaménko mínus). Například bankovnictví , jména a výukový program se často používají se slovem Osobní. V čistších výsledcích vyhledávání se tedy nezobrazí učebnicový příklad dotazu, ale upřesněný:
Intitle:"Index /Osobní/" -jména -náuka -bankovnictví
Poslední příklad
Sofistikovaný hacker se vyznačuje tím, že si vše potřebné zajišťuje sám. Například VPN je pohodlná věc, ale buď drahá, nebo dočasná a s omezeními. Zaregistrovat se sám pro sebe je příliš drahé. Je dobře, že existují skupinové odběry a s pomocí Google je snadné se stát součástí skupiny. K tomu stačí najít konfigurační soubor Cisco VPN, který má poněkud nestandardní příponu PCF a rozpoznatelnou cestu: Program Files\Cisco Systems\VPN Client\Profiles . Jedna žádost a připojíte se například k přátelskému personálu univerzity v Bonnu.
Typ souboru: pcf vpn NEBO Skupina

INFO
Google najde konfigurační soubory s hesly, ale mnoho z nich je zašifrováno nebo nahrazeno hashe. Pokud vidíte řetězce pevné délky, okamžitě vyhledejte službu dešifrování.Hesla jsou uložena v zašifrované podobě, ale Maurice Massard již napsal program na jejich dešifrování a poskytuje jej zdarma prostřednictvím thecampusgeeks.com.
V Nápověda Google stovky odlišné typyútoky a penetrační testy. Existuje mnoho možností pro oblíbené programy, hlavní databázové formáty, četné zranitelnosti v PHP, cloudy a tak dále. Pokud přesně víte, co hledáte, mnohem snáze získáte informace, které potřebujete (zejména informace, které jste nechtěli zveřejnit). Žádný Shodan single nevyživuje zajímavé nápady, ale jakákoli databáze indexovaných síťových zdrojů!
Rozhraní Facebooku je zvláštní a místy zcela nelogické. Ale náhodou tam byli skoro všichni, se kterými komunikuji, takže to musím vydržet.
Spousta věcí na Facebooku není samozřejmých. Snažil jsem se v tomto příspěvku shromáždit to, co jsem nenašel hned, a mnozí to pravděpodobně ještě nenašli.
Stuha
Ve výchozím nastavení Facebook generuje zdroj oblíbených příspěvků. Zároveň na různé počítače může to být úplně jinak. Chcete-li přinutit Facebook, aby vygeneroval „normální“ časovaný zdroj, klikněte na zaškrtnutí vpravo od slova „Zprávy“ a vyberte „Nedávné“.Bohužel v mobilní aplikace pro Android je feed tvořen pouze oblíbeností.
Čištění pásky
Na Facebooku si vždy přidám každého, kdo se zeptá, do přátel, ale nechci ve feedu číst žádné nesmysly. Chcete-li ze svého zdroje odstranit nepotřebné publikace, není třeba nikoho odstraňovat z přátel, stačí zakázat předplatné. Jakmile ve zdroji uvidíte něco zbytečného, klikněte na zaškrtnutí vpravo a vyberte „Odhlásit odběr ...“. Poté se příspěvky tohoto uživatele ve vašem zdroji již nikdy neobjeví.
Oznámení
Když zanecháte jakýkoli komentář k libovolnému příspěvku nebo fotografii, Facebook vás začne upozorňovat na všechny nové komentáře. Chcete-li se odhlásit, musíte vypnout oznámení. U různých objektů se to provádí v různá místa. Se stavem je vše jednoduché – klikněte na zaškrtnutí vpravo od stavu a vyberte „Nedostávat upozornění“.


Bohužel se nemůžete odhlásit z odběru komentářů v mobilní aplikaci pro Android.
Vyhledávání podle zpráv
Facebook má vyhledávání soukromých zpráv, ale málokdo ví, kde se skrývá. Klikněte na tlačítko zprávy a poté klikněte na „zobrazit vše“ v dolní části okna, které se otevře.
Otevře se rozhraní pro zasílání zpráv s druhým vyhledávacím panelem nahoře.

Zde můžete hledat jakákoli slova ve všech soukromých zprávách napsaných za celou dobu používání Facebooku.
Bojový posel
Facebook to vyžaduje mobilní zařízení existovala samostatná aplikace pro zasílání zpráv - facebookový messenger. Spousta lidí ho nemá moc ráda. Prozatím existuje způsob, jak pokračovat v zasílání zpráv na samotném Facebooku. Když Facebook opět odmítne zobrazovat zprávy vyžadující instalaci Messengeru, přejděte do správce aplikací (v Androidu - Nastavení systému - Aplikace), najděte tam Facebook a klikněte na tlačítko "Vymazat data". Poté spusťte Facebook a znovu zadejte své uživatelské jméno a heslo. Zprávy pak budou chvíli fungovat, i když Facebook občas vyskočí okno s výzvou k instalaci Messengeru.Protokol činnosti
Na Facebooku je často velmi těžké něco najít. Trochu pomáhá následující schéma. Pokud uvidíte něco, co by se vám mohlo později hodit, dejte like. V budoucnu bude tento like moci najít publikaci v protokolu aktivit. Chcete-li časopis otevřít, klikněte na malé zaškrtnutí vpravo horním rohu rozhraní a v nabídce, která se otevře, vyberte "Protokol akcí".
Vložte publikaci
Každý příspěvek na Facebooku má odkaz „Vložit příspěvek“. Vytváří kód, který lze vložit na jakoukoli stránku, kam můžete vložit html (včetně LiveJournalu). Bohužel se zdá být možnost vložit video uzavřená. Před týdnem to fungovalo, ale nyní se v jakémkoli zobrazení zobrazuje "Tento příspěvek na Facebooku již není dostupný. Možná byl smazán nebo byla změněna jeho nastavení ochrany osobních údajů."Zakázat automatické přehrávání videa
Ve výchozím nastavení Facebook automaticky přehrává všechna videa ve feedu bez zvuku. Na mobilních zařízeních to může být problém, protože to spotřebovává hodně dat.V prohlížeči je automatické přehrávání videa zakázáno takto: klikněte na zaškrtnutí v pravém horním rohu, tam jsou nastavení, pak - video.

V Androidu - klikněte na tři pruhy vpravo v liště ikon, tam "Nastavení aplikace" - "Automatické přehrávání videa" - nastavte na "Vypnuto." nebo "Pouze Wi-Fi". V druhém případě se videa budou automaticky přehrávat pouze při připojení přes wi-fi.
Přechod k publikaci
Chcete-li přejít z kanálu na konkrétní publikaci, stačí kliknout na datum publikace a odkaz na publikaci získáte kliknutím pravým tlačítkem myši na datum a výběrem položky "Kopírovat odkaz" tam. Díky za tuto radu samon , zz_z_z , Borhomey .
Tajemný Facebook má jistě mnohem více tajemství, ke kterým jsem se ještě nedostal.
Pokud víte o dalších facebookových tajemstvích, napište do komentářů, příspěvek doplním.
Uložené
Dobrý den. Dnes budeme hovořit o ochraně a přístupu k bezpečnostním kamerám. Je jich mnoho a používají se k různým účelům. Jako vždy použijeme standardní databázi, která nám umožní takové kamery najít a uhodnout k nim hesla. Teorie Většina zařízení není po instalaci nakonfigurována ani aktualizována. Proto naše cílové publikum být pod oblíbenými porty 8000, 8080 a 554. Pokud potřebujete prohledat síť, je lepší tyto porty okamžitě přidělit. Metoda č. 1 Pro názorný příklad můžete vidět zajímavé dotazy ve vyhledávačích Shodan a Сensys. Zvažte několik dobré příklady s jednoduchými požadavky. has_screenshot:true port:8000 // 183 výsledků; has_screenshot:true port:8080 // 1025 výsledků; has_screenshot:true port:554 // 694 výsledků; takhle jednoduchým způsobem máte přístup k velkému počtu otevřených kamer, které jsou umístěny v zajímavá místa: obchody, nemocnice, čerpací stanice atd. Pojďme se podívat na pár zajímavých možností. Ordinace Soukromá kdesi v hlubinách Evropy Učebna někde v Čeljabinském obchodě Dámské oblečení Tímto jednoduchým způsobem můžete najít spoustu zajímavých objektů, které jsou volně přístupné. Nezapomeňte, že k získání údajů podle země můžete použít filtr země. has_screenshot:true port:8000 country:ru has_screenshot:true port:8080 country:ru has_screenshot:true port:554 country:ru Metoda #2 Můžete použít vyhledávání pro standardní sociální sítě. K tomu je lepší při prohlížení snímků z kamer používat názvy stránek, zde je výběr nejzajímavějších možností: inurl:/view.shtml inurl:ViewerFrame?Mode= inurl:ViewerFrame?Mode=Obnovit inurl:view/ index.shtml inurl:view/ view.shtml intitle:”live view” intitle:axis intitle:liveapplet all in title:”Network Camera Network Camera” intitle:axis intitle:”video server” intitle:liveapplet inurl:LvAppl intitle:” EvoCam” inurl:”webcam. html” intitle:”Live NetSnap Cam-Server feed” intitle:”Live View / - AXIS 206M” intitle:”Live View / - AXIS 206W” intitle:”Live View / - AXIS 210″ inurl :indexFrame.shtml Axis intitle: start inurl:cgistart intitle:”WJ-NT104 Main Page” intitle:snc-z20 inurl:home/ intitle:snc-cs3 inurl:home/ intitle:snc-rz30 inurl:home/ intitle:” Síťová kamera sony snc-p1″ intitle:”síťová kamera sony snc-m1″ intitle:”Síťová kamera Toshiba” uživatelské přihlašovací jméno:”Konzola i-Catcher - Web Monitor” Sklizeň odměn a nalezení kanceláře společnosti na letišti Pojďme přidat další port do sbírky a můžete dokončit metodu # 3 Tato metoda je cílová. Používá se, když máme buď jeden bod a potřebujeme uhodnout heslo, nebo chceme spustit databázi pomocí standardních hesel a najít platné výsledky. Pro tyto účely je Hydra perfektní. Chcete-li to provést, musíte si připravit slovník. Můžete běhat a hledat standardní hesla pro routery. Pojďme se podívat konkrétní příklad. Existuje model fotoaparátu DCS-2103. Vyskytuje se poměrně často. Funguje to přes port 80. Použijme příslušná data a najdeme potřebné informace v shadanu. Dále shromažďujeme všechny IP potenciálních cílů, které nás zajímají. Dále vytvoříme seznam. Shromažďujeme seznam hesel a vše použijeme pomocí utility hydra. K tomu musíme do složky přidat slovník, seznam IP adres a spustit následující příkaz: hydra -l admin -P pass.txt -o good.txt -t 16 -vV -M targets.txt http- get V kořenové složce by měl být soubor pass.txt s hesly, přihlášení používáme jednoho admina s parametrem -l, pokud potřebujete nastavit slovník pro přihlášení, tak je potřeba přidat soubor do kořenového adresáře a zaregistrovat se to s parametrem -L. Shodné výsledky budou uloženy v souboru good.txt. Seznam IP adres je nutné přidat do kořenového adresáře se souborem targets.txt. Poslední fráze v příkazu http-get je zodpovědná za připojení přes port 80. Příklad programu Zadání příkazu a spuštění Na závěr bych chtěl přidat pár informací o skenování. Chcete-li získat síťová čísla, můžete využít vynikající službu. Dále je třeba tyto mřížky zkontrolovat na přítomnost portů, které potřebujeme. Skenery doporučovat nebudu, ale řeknu, že stojí za to přejít k takovým a podobným skenerům jako masscan, vnc scanner a další. Může být napsán na základě známého nástroje nmap. Hlavním úkolem je skenovat rozsah a najít aktivní IP s potřebnými porty. Závěr Nezapomeňte, že kromě standardního zobrazení můžete pořídit více fotografií, nahrát video a stáhnout si ho pro sebe. Můžete také ovládat kameru a otáčet se požadovaným směrem. A nejzajímavější je možnost zapnout zvuky a mluvit na některých kamerách. Co se zde dá poradit? Dát silné heslo přístup a nezapomeňte předat porty.