Based on: demo USE options in Informatics for 2015, http://wiki.vspu.ru/
To encode a certain sequence consisting of the letters A, B, C, D and D, an uneven binary code, which makes it possible to uniquely decode the resulting binary sequence. Here is the code: A - 0; B - 100; B - 1010; G - 111; D - 110. It is required to reduce the length of the code word for one of the letters so that the code can still be decoded unambiguously. The codes of the remaining letters should not change. How can I do that?
In order to understand what is required of us, let's deal with each word in this assignment. Coding, sequence - these are familiar and well-understood words for all of us, and we perfectly understand what they mean. And now, after listing the letters, we are faced with the not-so-familiar phrase NON-UNIFORM binary code. Uneven binary encoding- encoding in which the characters of some primary alphabet are encoded by combinations of characters of the binary alphabet (ie 0 and 1), and the length of the codes and, accordingly, the duration of the transmission of an individual code, may differ. This idea of binary coding is the basis of the Huffman Code, in which the character that occurs most often in the sequence receives a very small code, and the character that occurs least often receives, on the contrary, a very long code, thereby reducing the amount of information.
Suppose we have a string "tor here ter", for which, in its current form, one byte is spent for each character. This means that the entire line takes up 11*8 = 88 bits of memory. After encoding, the string will take 27 bits.

To get a code for each character of the string "thor here ter", based on its frequency, we need to build a tree (graph) such that each leaf of this tree will contain a character. The tree will be built from leaves to the root, in the sense that characters with a lower frequency will be further from the root than characters with a higher one.
To build a tree, we will use a slightly modified priority queue - the elements with the lowest priority will be extracted from it first, and not the highest. This is necessary to build a tree from the leaves to the root.
And so, we calculate the frequency of characters T R gap O U E
| Symbol | Frequency |
| T | 4 |
| R | 2 |
| " " | 2 |
| At | 1 |
| O | 1 |
| E | 1 |
After calculating the frequencies, we will create binary tree nodes for each sign and add them to the queue, using the frequency as a priority:
Now we take the first two elements from the queue and link them, creating a new node in the tree, in which they will both be children, and the priority of the new node will be equal to the sum of their priorities. After that, we add the resulting new node back to the queue.

We repeat the same steps and as a result we get:


After linking the branches into one tree, we will get the following codes for our symbols

T - 00; P - 10; space -01; O - 1110; U - 110; E - 1111 more details can be read
Task 1 USE:
To encode a certain sequence consisting of the letters A, B, C, D and D, a non-uniform binary code is used, which makes it possible to uniquely decode the resulting binary sequence. Here is the code: A - 0; B - 100; B - 1010; G - 111; D - 110. It is required to reduce the length of the code word for one of the letters so that the code can still be decoded unambiguously. The codes of the remaining letters should not change. How can I do that?
The lesson is devoted to how to solve the 5th task of the exam in computer science
The 5th topic is characterized as tasks of a basic level of complexity, the execution time is about 2 minutes, the maximum score is 1
- Coding- this is the presentation of information in a form convenient for its storage, transmission and processing. The rule for transforming information to such a representation is called code.
- Coding happens uniform and uneven:
- with uniform coding, all characters correspond to codes of the same length;
- with uneven coding different characters correspond to codes of different lengths, which makes it difficult to decode.
Example: We encrypt the letters A, B, C, D using binary coding with a uniform code and count the number of possible messages:
So we got uniform code, because the length of each code word is the same for all codes (2).
Encoding and decoding messages
Decoding (decoding) is the restoration of a message from a sequence of codes.
To solve problems with decoding, you need to know the Fano condition:
Fano condition: no codeword must be the beginning of another codeword (which ensures unambiguous decoding of messages from the beginning)
Prefix code is a code in which no code word coincides with the beginning of another code word. Messages using such a code are unambiguously decoded.

Unambiguous decoding is provided:



Solution of 5 tasks of the exam
USE 5.1: To encode the letters O, B, D, P, A, we decided to use the binary representation of the numbers 0, 1, 2, 3 and 4, respectively (with one insignificant zero preserved in the case of a single-digit representation).
Encode the sequence of letters WATERFALL in this way and write the result in octal code.
✍ Solution:
- Let's translate the numbers into binary codes and put them in line with our letters:
Result: 22162
The decision of the exam of this task in computer science, video:
Consider another analysis of the 5 tasks of the exam:
USE 5.2: For 5 letters of the Latin alphabet, their binary codes are given (for some letters - from two bits, for some - from three). These codes are presented in the table:
| a | b | c | d | e |
|---|---|---|---|---|
| 000 | 110 | 01 | 001 | 10 |
What set of letters is encoded by the binary string 1100000100110 ?
✍ Solution:
- First, we check the Fano condition: no code word is the beginning of another code word. The condition is correct.
- We break the code from left to right according to the data presented in the table. Then we translate it into letters:
✎ 1 solution:
Result: b a c d e.
✎ Solution 2:
 110
000 01
001 10
110
000 01
001 10
Result: b a c d e.
In addition, you can watch the video of the solution to this USE task in computer science:
Let's solve the following 5 task:
USE 5.3:
To transmit numbers over a noisy channel, a parity code is used. Each of its digits is written in binary representation, with leading zeros added up to a length of 4 , and the sum of its elements modulo 2 is added to the resulting sequence (for example, if we pass 23 , we get the sequence 0010100110).
Determine what number was transmitted over the channel in the form 01100010100100100110 .
✍ Solution:
- Consider example from the problem statement:
Answer: 6 5 4 3
You can watch the video of the solution to this USE task in computer science:
USE 5.4:
To encode a certain sequence consisting of the letters K, L, M, H, we decided to use a non-uniform binary code that satisfies the Fano condition. The code word 0 was used for the letter H, and the code word 10 was used for the letter K.
What is the smallest possible total length of all four codewords?
✍ Solution:
✎ 1 solution based on logical reasoning:
- Let's find the shortest possible code words for all letters.
- code words 01 and 00 cannot be used, since then the Fano condition is violated (they start from 0, and 0 - this is H).
- Let's start with two-digit code words. Let's take for the letter L codeword 11 . Then for the fourth letter it is impossible to choose a code word without violating the Fano condition (if you then take 110 or 111, then they start with 11).
- So, you need to use three-digit code words. Let's encode the letters L and M code words 110 and 111 . The Fano condition is met.
✎ Solution 2:
 (N) -> 0 -> 1 character (K) -> 10 -> 2 characters (L) -> 110 -> 3 characters (M) -> 111 -> 3 characters
(N) -> 0 -> 1 character (K) -> 10 -> 2 characters (L) -> 110 -> 3 characters (M) -> 111 -> 3 characters Answer: 9
USE in Informatics 5 task 2017 FIPI option 2 (edited by Krylov S.S., Churkina T.E.):
Messages containing only 4 letters are transmitted over the communication channel: A, B, C, D; for transmission, a binary code is used that allows unambiguous decoding. For letters A, B, C, the following code words are used: A: 101010, B: 011011, C: 01000.
Г, at which the code will allow unambiguous decoding. least numerical value.
✍ Solution:
- The smallest codes might look like 0 and 1 (single bit). But this would not satisfy the Fano condition ( BUT starts from one 101010 , B starts from scratch - 011011 ).
- The next smallest code would be a two letter word 00 . Since it is not a prefix of any of the presented code words, then G = 00.
Result: 00
USE in Informatics 5 task 2017 FIPI option 16 (edited by Krylov S.S., Churkina T.E.):
To encode a certain sequence consisting of the letters A, B, C, D and E, we decided to use a non-uniform binary code that allows you to uniquely decode the binary sequence that appears on the receiving side of the communication channel. Code used: A - 01, B - 00, C - 11, D - 100.
Specify what code word the letter D should be encoded with. Length this code word must be least of all possible. The code must satisfy the unambiguous decoding property. If there are several such codes, indicate the code with the smallest numerical value.
✍ Solution:
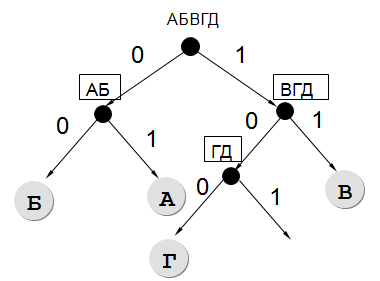
Result: 101
A more detailed analysis of the lesson can be viewed on the video of the Unified State Examination in Informatics 2017:
USE in Informatics 5 task 2017 FIPI option 17 (Krylov S.S., Churkina T.E.):
To encode a certain sequence consisting of the letters A, B, C, D, D and E, we decided to use a non-uniform binary code that allows you to uniquely decode the binary sequence that appears on the receiving side of the communication channel. Code used: A - 0, B - 111, C - 11001, D - 11000, D - 10.
Specify what code word the letter E should be encoded with. The length of this code word must be the smallest possible. The code must satisfy the unambiguous decoding property. If there are several such codes, indicate the code with the smallest numerical value.
✍ Solution:
 1 - not suitable (all letters except A start with 1) 10 - not suitable (corresponding to code D) 11 - not suitable (beginning of codes B, C and D) 100 - not suitable (code D - 10 - is the beginning of this code) 101 - not suitable (code D - 10 - is the beginning of this code) 110 - not suitable (beginning of codes C and D) 111 - not suitable (corresponds to code B) 1000 - not suitable (code D - 10 - is the beginning of this code) 1001 - not suitable (code D - 10 - is the beginning of this code) 1010 - not suitable (code D - 10 - is the beginning of this code) 1011 - not suitable (code D - 10 - is the beginning of this code) 1100 - not suitable ( beginning of code C and D) 1101 - suitable
1 - not suitable (all letters except A start with 1) 10 - not suitable (corresponding to code D) 11 - not suitable (beginning of codes B, C and D) 100 - not suitable (code D - 10 - is the beginning of this code) 101 - not suitable (code D - 10 - is the beginning of this code) 110 - not suitable (beginning of codes C and D) 111 - not suitable (corresponds to code B) 1000 - not suitable (code D - 10 - is the beginning of this code) 1001 - not suitable (code D - 10 - is the beginning of this code) 1010 - not suitable (code D - 10 - is the beginning of this code) 1011 - not suitable (code D - 10 - is the beginning of this code) 1100 - not suitable ( beginning of code C and D) 1101 - suitable
Result: 1101
A more detailed solution to this task is presented in the video tutorial:
5 task. Demo version of the Unified State Examination 2018 Informatics (FIPI):
Encrypted messages containing only ten letters are transmitted over the communication channel: A, B, E, I, K, L, R, C, T, U. An uneven binary code is used for transmission. Code words are used for nine letters. 
Specify the shortest code word for the letter B, under which the code will satisfy the Fano condition. If there are several such codes, indicate the code with least numerical value.
✍ Solution:
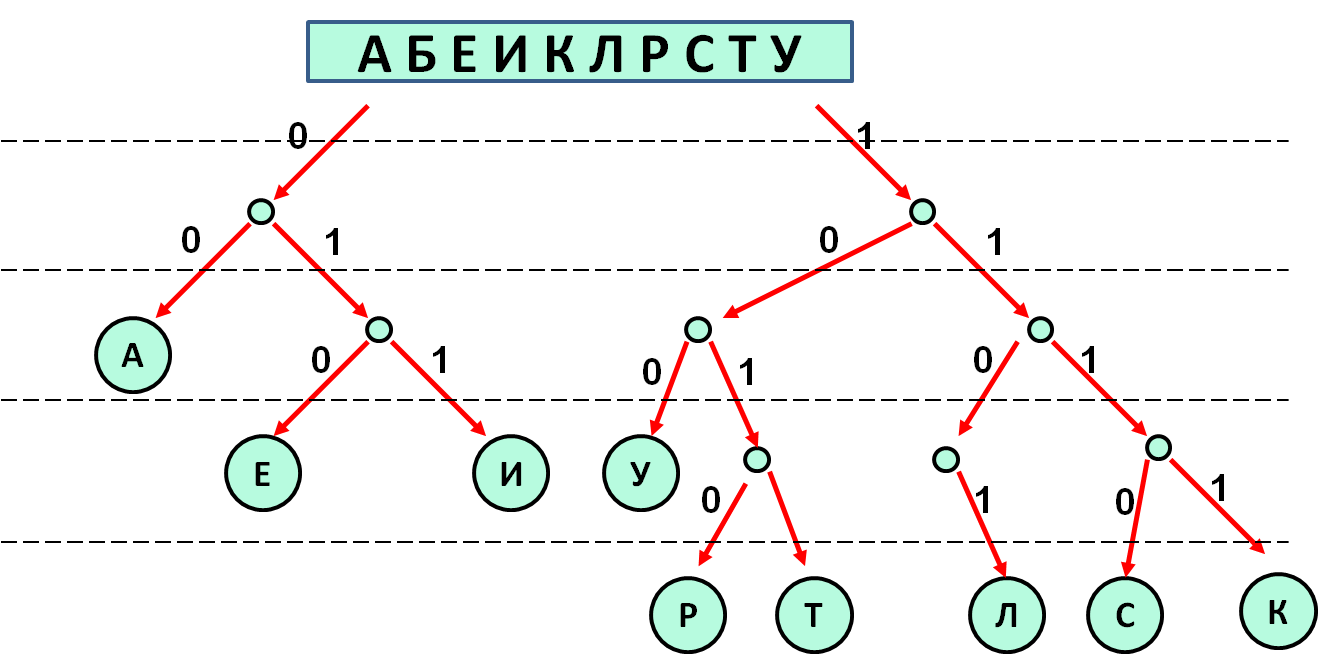
Result: 1100
For a detailed solution of this 5 task from the USE demo version of 2018, see the video:
Task 5_9. Typical exam options 2017. Option 4 (Krylov S.S., Churkina T.E.):
Encrypted messages containing only four letters are transmitted over the communication channel: A, B, C, G; for transmission, a binary code is used that allows unambiguous decoding. For letters BUT, B, AT code words are used:
A: 00011 B: 111 C: 1010
Specify the shortest code word for the letter G, at which the code will allow unambiguous decoding. If there are several such codes, indicate the code with least numerical value.
✍ Solution:

Result: 00
Task 5_10. Training option No. 3 dated 01.10.2018 (FIPI):
Messages containing only letters are transmitted over the communication channel: A, E, D, K, M, R; for transmission, a binary code is used that satisfies the Fano condition. The following codes are known to be used:
E - 000 D - 10 K - 111
Specify the smallest possible length of the encoded message DEDMAKAR.
In the answer, write a number - the number of bits.
✍ Solution:
 D E D M A C A R 10 000 10 001 01 111 01 110
D E D M A C A R 10 000 10 001 01 111 01 110
Result: 20
See the solution to the problem:
Exercise:
1)
To encode the letters A, B, C, D, we decided to use two-digit sequential binary numbers (from 00 to 11respectively). If in this way we encode a sequence of GBAB symbols and write the result inhexadecimal number system, you get:
1) 132
16 2)
D2 16 3) 3102 16 4) 2D 16
Solution and answer:
From the condition respectively:
A - 00
B - 01
AT 10 O'CLOCK
G - 11
GBAV = 11010010 - translate this binary notation into hexadecimal system and get D2
Answer: 2
2) To encode the letters A, B, C, D, we decided to use two-digit sequential binary numbers (from 00 to 11, respectively). If we encode the GBVA character sequence in this way and write the result in hexadecimal code, we get:
1) 138 16 2) DBCA 16 3) D8 16 4) 3120 16
Solution and answer:
By condition:
A = 00
B = 01
B = 10
G = 11
Means:
GBVA = 11011000 in binary. Convert to hexadecimal and get D8
Answer: 3
3)
For 5 letters of the Latin alphabet, their binary codes are given (for some letters - from two bits, for some - from three). These codes are presented in the table:
a b c d e
000 110 01 001 10
Determine which set of letters is encoded by the binary string 1100000100110
1) badade 2) badde 3)
bacde 4) bacdb
Solution and answer:
The first letter is b because the binary code is 110
The second letter is a, since the binary code is 000
The third letter is c, since the binary code is 01
The fourth letter is d, because the binary code is 001
The fifth letter is e, since the binary code is 10
Outcome: bacde, which corresponds to option number 3.
Answer: 3
4)
To encode the letters A, B, C, D, four-bit sequential binary numbers from 1000 to 1011 are used, respectively. If in this way we encode a sequence of BGAW symbols and write the result in octal code, we get:
1) 175423 2)
115612 3) 62577 4) 12376
Solution and answer:
By condition:
A = 1000
B = 1001
B = 1010
G = 1011
BGAV = 1001101110001010, now you should convert this number from binary to octal and get the answer.
1001101110001010 2 = 115612 8
Answer: 2
5)
To encode the letters A, B, C, D, three-digit sequential binary numbers starting from 1 (from 100 to 111, respectively) are used. If we encode the sequence of CDAB characters in this way and write the result in hexadecimal code, we get:
1) A52 16 2) 4C8 16 3) 15D 16 4)
DE5 16
Solution and answer:
Condition: Respectively
A=100
B=101
C=110
D=111
CDAB = 110111100101, convert the binary number to hexadecimal:
110111100101 2 = DE5 16
Answer: 4
6)
To encode the letters K, L, M, N, four-bit sequential binary numbers from 1000 to 1011 are used, respectively. If we encode the KMLN character sequence in this way and write the result in octal code, we get:
1) 84613 8 2)
105233 8 3) 12345 8 4) 776325 8
Solution and answer:
Condition: respectively
K=1000
L=1001
M=1010
N=1011
KMLN = 1000101010011011, convert to octal:
1000101010011011 2 = 105233 8
Answer: 2
7) For 5 letters of the Latin alphabet, their binary codes are given (for some letters - from two bits, for some - from three). These codes are presented in the table:
A b c d e
100 110 011 01 10
Determine which set of letters is encoded by the binary string 1000110110110 if it is known that all letters in the sequence are different:
1) cbade 2)
acdeb 3) acbed 4) bacde
Solution and answer:
Let's write the binary code in the form of bits: By enumeration options to avoid repeating letters.
It turns out: 100 011 01 10 110
Consequently: acdeb
Answer: 2
8)
For 6 letters of the Latin alphabet, their binary codes are given (for some letters from two bits, for some - from three). These codes are presented in the table:
A B C D E F
00 100 10 011 11 101
Determine which sequence of 6 letters is encoded by the binary string 011111000101100.
1) DEFBAC 2) ABDEFC 3)
DECAFB 4) EFCABD
Solution and answer:
We will solve by enumeration, since the letters in the answers are not repeated, which means that the codes should not be repeated:
We get:
011 11 10 00 101 100
Respectively: DECAFB
Answer: 3
9)
To encode the letters A, B, C, D, four-bit consecutive binary numbers starting from 1 (from 1001 to 1100, respectively) are used. If we encode the CADB character sequence in this way and write the result in hexadecimal code, we get:
1)
AF52 16 2)
4CB8 16 3)
F15D16 4)
B9CA 16
Solution and answer: respectively..
A-1001
B-1010
C-1011
D-1100
So: CADB = 1011100111001010, we will convert 1011100111001010 from binary to hexadecimal:
1011 1001 1100 1010 2 = B9CA 16 ,
which corresponds to the fourth option.
Answer: 4
10)
A B C D
00 11 010 011
If we encode the VGAGBV character sequence in this way and write the result in hexadecimal code, we get:
1) CDADBC 16 2) A7C4 16 3) 412710 16 4)
4S7A 16
Solution and answer:
VGAGBV = 0100110001111010, convert to hexadecimal:
0100 1100 0111 1010 2 = 4C7A 16
Answer: 4
11)
To encode a message consisting only of the letters A, B, C and D, a binary code that is uneven in length is used:
A B C D
00 11 010 011
If we encode the GAVBVG character sequence in this way and write the result in hexadecimal code, we get:
1)
62D3 16 2) 3D26 16 3) 31326 16 4) 62133 16
Solution and answer:
GAVBVG = 0110001011010011 2 - Convert to hexadecimal system:
0110 0010 1101 0011 2 = 62D3 16
Answer: 1
12) To encode a message consisting only of the letters A, B, C and D, an uneven length is used
binary code:
A B C D
00 11 010 011
If in this way we encode the sequence of characters GBWAVG and write the result in hexadecimal
code, you get:
1) 71013 16 2) DBCACD 16 3) 31A7 16 4)
7A13 16
Solution and answer:
GBVAVG = 0111101000010011 2 - convert to hexadecimal.
0111 1010 0001 0011 2 = 7A13 16
Answer: 4
13)
To encode a message consisting only of the letters A, B, C and D, a binary code that is uneven in length is used:
A B C D
00 11 010 011
If we encode the GAVBGV character sequence in this way and write the result in hexadecimal code, we get:
1) DACBDC 16 2) AD26 16 3) 621310 16 4)
62DA 16
Solution and answer: respectively..
GAVBGV = 0110001011011010 2 , convert to hexadecimal:
0110 0010 1101 1010 2 = 62DA 16
Answer: 4
14)
To encode a message consisting only of the letters A, B, C, D and E, a binary code of uneven length is used:
A B C D E
000 11 01 001 10
Which (only one!) of the four received messages was transmitted without errors and can be decoded:
1)
110000010011110
2) 110000011011110
3) 110001001001110
4) 110000001011110
Solution and answer:
Let's take the first code:
11 000 001 001 11 10 = BADDBE
Second code:
11 000 001 10 11 110 = misspelled at the end.
Third code:
11 000 10 01 001 110 = misspelled at the end.
Fourth code:
11,000,000 10 11 110 = misspelled at the end.
Answer: 1
15)
coding: A-00, B-11, V-010, G-011. A message is transmitted through the communication channel: WAGBGV. Encode a message
given code. Convert the resulting binary sequence to hexadecimal.
1) AD34 2)
43DA 3) 101334 4) CADBCD
Solution and answer:
VAGBGV = 0100001111011010 2 , translate into hexadecimal system:
0100 0011 1101 1010 2 = 43DA 16
Answer: 2
16)
For transmission over a communication channel of a message consisting only of the letters A, B, C, D, it was decided to use a code that is uneven in length: A=1, B=01, C=001. How should the letter G be encoded so that the code length is minimal and the encoded message can be unambiguously divided into letters?
1) 0001 2)
000 3) 11 4) 101
Solution and answer:
In order for the message to be decoded, it is required that neither code is the beginning of another, longer code.
1, 3 and 4 options are not suitable, they are the beginning of other codes.
Option 2 - is not the beginning of other codes.
Answer: 2
17) For transmission over a communication channel of a message consisting only of the letters A, B, C, D, it was decided to use a code that is uneven in length: A=0, B=100, C=101. How should the letter G be encoded so that the code length is minimal and the encoded message can be unambiguously divided into letters?
1) 1 2) 11 3) 01 4) 010
Similar to task number 16.
Answer: 2
18) A black and white bitmap is encoded line by line, starting from the left top corner and ending in the lower right corner. When encoded, 1 denotes black and 0 denotes white.
For compactness, the result was written in the octal number system. Choose the correct code entry.
1) 57414 2) 53414 3)
53412 4) 53012
Solution and answer:
After encoding we get given code:
101011100001010 2 , translate this code into octal:
101 011 100 001 010 2 = 53412 8
Answer: 3
19) To transmit over a communication channel a message consisting only of the characters A, B, C and D, a character-by-character
coding: A-0, B-11, V-100, G-011. A message is transmitted through the communication channel: GBAVAVG. Encode a message
given code. Convert the resulting binary sequence to octal code.
1) DBACACD 2) 75043 3) 7A23 4) 3304043
Solution and answer: Accordingly:
GBAAVG = 0111101000100011 2 , convert to octal system.
0 111 101 000 100 011 2 \u003d 75043 8, the first zero is not significant.
Answer: 2
20) A 5-bit code is used to transmit data over a communication channel. The message contains only
letters A, B and C, which are encoded by the following code words:
A - 11010, B - 00110, C - 10101.
Transmission may be interrupted. However, some errors can be corrected. Any two of these three code words differ from each other in at least three positions. Therefore, if the transmission of a word has an error in no more than one position, then an educated guess can be made about which letter was transmitted. (They say that “the code corrects one error.”) For example, if the code word 10110 is received, it is considered that the letter B was transmitted. (The difference from the code word for B is only in one position, for the remaining code words there are more differences.) If the received If the code word differs from the code words for the letters A, B, C in more than one position, then it is considered that an error has occurred (it is denoted by 'x').
Message 00111 11110 11000 10111 received. Decode this message - choose the correct option.
1) BAAx
2)
BAAV
3) xxxx
4) xAAx
Solution:
1) 00111 = B because 1 error in the last digit.
2) 11110 = A, as there is 1 error in the third digit.
3) 11000 = A, since there is 1 error in the fourth digit.
4) 10111 = B because 1 error in the fourth digit
00111 11110 11000 10111 = BAAV.
Answer: 2
GBPOU of the city of Moscow "Sports and Pedagogical College"
Department of sports and tourism of the city of Moscow
Informatics and ICT teacher: Makeeva E.S.
USE tasks. Coding text information
Task 1
Assuming that each character is encoded by one byte, estimate the size of the next sentence (in bits) in the encodingASCII: http:// www. fipi. en
Task 2
In KOI-8 encoding, each character is encoded with 8 bits. Determine the information size (in bytes) of the following sentence:Mail . en - mail server. Give your answer only as a number.
Task 3
Each character inUnicodeencoded as a two-byte word. Determine the information volume (in bits) of the following phrase A.P. Chekhov in this encoding:What is incomprehensible is a miracle. Give your answer only as a number.
Task 4
AT text editor included text encoding KOI-8 (1 byte per 1 character). The boy typed in a few words. How many characters are typed in the editor if the total amount of information typed by the boy is 592 bits?
Task 5
Information volume of the offerYou won't spoil the porridge with oil. is 50 bytes. Determine how many bits encode one character. Give your answer only as a number.
Task 6
How many times will the information volume of a page of text decrease (the text does not contain formatting control characters) when it is converted from Unicode encoding (the encoding table contains 65,536 characters) to the Windows encoding (the encoding table contains 256 characters)? Give your answer only as a number.
Task 7
Code table CP1251 (Windows Cyrillic) is used. How many kilobytes will a plain text file take if there are 200 pages of text, 32 lines per page, and an average of 48 characters per line? Give your answer only as a number.
Task 8
The optical character recognition system allows you to convert scanned images of document pages into text format at a speed of 4 pages per minute and uses an alphabet with a capacity of 65,536 characters. How much information (in kilobytes) will a text document, each page of which contains 40 lines of 50 characters, carry after 10 minutes of application operation?Give your answer only as a number.
Task 9
A message in Greek containing 150 characters was written in 16-bit codeUnicode. What is the information size of the message in bytes? Give your answer only as a number.
Task 10
The automatic device carried out automatic recoding of the information message in Russian from a 16-bit representationUnicodeinto 8-bit KOI-8 encoding. Before recoding, the information volume of the message was 30 bytes. Determine the information volume of the message (in bits) after recoding. Give your answer only as a number.
USE tasks. Encoding of text information.
Task 1
The automatic device recoded the information message in Russian, originally written in 16-bit Unicode code, into 8-bit KOI-8 encoding. In this case, the information message has decreased by 640 bits. What is the length of the message in characters?
Task 2
The automatic device recoded an information message in Russian with a length of 50 characters, originally recorded in a 2-byte Unicode code, into an 8-bit KOI-8 encoding. By how many bits was the message length reduced?
Task 3
The automatic device recoded an information message in Russian with a length of 55 characters, originally recorded in a 2-byte Unicode code, into an 8-bit KOI-8 encoding. By how many bits was the message length reduced? Write only the number in your answer.
Task 4
The automatic device recoded an information message in Russian with a length of 100 characters, originally recorded in a 2-byte Unicode code, into an 8-bit KOI-8 encoding. By how many bits was the message length reduced? Write only the number in your answer.
Task 5
The message in Russian was originally written in 16-bit Unicode. When it was recoded into the 8-bit KOI-8 encoding, the information message decreased by 80 bits. How many characters does the message contain?
Task 6
The message in Russian was originally written in 16-bit Unicode. When it was recoded into the 8-bit KOI-8 encoding, the information message decreased by 320 bits. How many characters does the message contain?
Task 7
Text Document, consisting of 10240 characters, was stored in 8-bit KOI-8 encoding. This document has been converted to 16-bit Unicode. Specify how many additional KB will be required to store the document. Write only the number in your answer.
Task 8
A text document consisting of 11264 characters was stored in 8-bit KOI-8 encoding. This document has been converted to 16-bit Unicode. Specify how many additional KB will be required to store the document. Write only the number in your answer.
Task 9
The message in Russian was originally written in 16-bit Unicode. The automatic device carried out its conversion into 8-bit encodingWindows1251. At the same time, the informational message has decreased by 320 bytes. Specify the length of the message in characters.
Task 10
Electronic user mailbox wrote a letter in Russian, choosing the encodingUnicode. But then he decided to use the 8-bit KOI-8 encoding. At the same time, the information volume of his letter decreased by 2 Kbytes. What is the length of the message in characters?
USE tasks. Graphic information encoding
Task 1
A black and white (no grayscale) raster graphic image has a size of 10x10 pixels. How much memory in bits will this image take up? Write only the number in your answer.
Task 2
A black and white (no grayscale) raster graphic image has a size of 20x20 pixels. How much memory in bytes will this image take up? Write only the number in your answer.
Task 3
A color (with a palette of 256 colors) raster graphic image has a size of 10x10 pixels. How much memory in bits will this image take up? Write only the number in your answer.
Task 4
During bitmap conversion graphic image the number of colors has decreased from 65,536 to 16. How many times has the information volume of the graphic file decreased?
Task 5
In the process of converting a raster graphic file, the number of colors decreased from 1024 to 32. How many times has the information volume of the file decreased?
Task 6
for storage bitmap 32×32 pixels in size took 512 bytes of memory. What is the maximum possible number of colors in an image's palette? Write only the number in your answer.
Task 7
To store a bitmap image of 64 × 64 pixels, 3 kilobytes of memory were allocated. What is the maximum possible number of colors in an image's palette? Write only the number in your answer.
Task 8
What is the amount of memory in kilobytes that should be allocated to store a 240×192 pixel bitmap if the image palette contains 65,000 colors? Write only the number in your answer.
Task 9
Monitor screen resolution 1024x768 pixels, color depth - 16 bits. What is the required amount of video memory (in megabytes) for this graphics mode? Write only the number in your answer.
Task 10
How much memory, in kilobytes, should be allocated to store a 640×480 pixel bitmap if there are 16 million colors in the image's palette? Write only the number in your answer.
USE tasks. Audio encoding.
Task 1
analog sound signal was sampled first using 65,536 signal strength levels (audio CD sound quality) and then using 256 signal strength levels (radio broadcast sound quality). How many times do the information volumes of digitized audio signals differ?Write only the number in your answer.
Task 2
Two-channel (stereo) audio is recorded at a sampling frequency of 16 kHz and 24-bit resolution. The recording lasts 8 minutes, its results are written to a file, data compression is not performed. Which of the following values is closest to the size of the resulting file?
Task 3
Two-channel (stereo) sound recording with a sampling frequency of 16 kHz and 24-bit resolution was carried out for 5 minutes. Data compression was not performed. Which of the following values is closest to the size of the resulting file?
Task 4
Two-channel (stereo) sound recording with a sampling frequency of 32 kHz and 24-bit resolution was carried out for 5 minutes. Data compression was not performed. Which of the following values is closest to the size of the resulting file?
Task 5
A single-channel (mono) sound recording was carried out with a sampling frequency of 32 kHz and 32-bit resolution. As a result, a 20 MB file was obtained, no data compression was performed. Which of the following values is closest to the time during which the recording was made?
Task 6
A single-channel (mono) sound recording was carried out with a sampling frequency of 32 kHz and 32-bit resolution. As a result, a 40 MB file was obtained, no data compression was performed. Which of the following values is closest to the time during which the recording was made?
Task 7
A two-channel (stereo) sound recording was made with a sampling frequency of 16 kHz and 24-bit resolution. As a result, a 30 MB file was obtained, no data compression was performed. Which of the following values is closest to the time that the recording was made?
Task 8
Two-channel (stereo) sound recording with a sampling frequency of 16 kHz and 24-bit resolution was carried out for 10 minutes. Data compression is not performed. Which of the following values is closest to the size of the resulting file?
Task 9
The user needs to record a digital audio file (mono) with a duration of 1 minute and a resolution of 16 bits. What should be the sampling rate if the user has 2.6 MB of memory?
Task 10
A digital audio file (mono) has a duration of 1 minute. However, it occupies 2.52 MB. With what sample rate is the sound recorded if the bit depth of the sound card is 8 bits?
Test. Option 1
Task 1
The phrase in Russian was encoded with a 16-bit codeUnicode:
“It’s not a shame not to know something, but it’s a shame not to want to learn” (Socrates)
What is the information volume of this phrase (quoted) in bytes. Write only the number in your answer.
Task 2
A text document consisting of 20480 characters was stored in 8-bit KOI-8 encoding. This document has been converted to 16-bit Unicode. Specify how many additional KB will be required to store the document. Write only the number in your answer.
Task 3
What is the amount of memory in kilobytes that must be allocated to store a 128×128 pixel bitmap if the image palette contains 64 colors? Write only the number in your answer.
Task 4
To store a bitmap image of 160 × 128 pixels, 5 kilobytes of memory were allocated. What is the maximum possible number of colors in an image's palette? Write only the number in your answer.
Task 5
A digital audio file (mono) occupies 2.7 MB of memory, 16-bit resolution. At what sampling rate is the sound recorded if the duration of the sound is 1 minute?
Test. Option 2
Task 1
Each character inUnicodeencoded as a two-byte word. Estimate the information volume of the following sentence in bytes.
"Tab - section (page) of the dialog box"
Write only the number in your answer.
Task 2
Some message was originally written in 16-bit Unicode. When it was recoded into the 8-bit KOI-8 encoding, the information message decreased by 1040 bits. Specify the length of the message in characters. Write only the number in your answer.
Task 3
What is the amount of memory in kilobytes that should be allocated to store a 128×128 pixel bitmap if there are 256 colors in the image palette? Write only the number in your answer.
Task 4
To store a bitmap image of 64 × 64 pixels, 3 kilobytes of memory were allocated. What is the maximum possible number of colors in an image's palette? Write only the number in your answer.
Task 5
The amount of free memory on the disk is 10.1 MB, the bit depth of the sound card is 16 bits. How long can an audio file (stereo) recorded at 44.1 kHz sample rate be?
Answers to the tasks of the exam:
| 1 | 144 | 400 | 300 | 156 | 300 | 120 |
||||
| 2 | 400 | 440 | 800 | 320 | 2048 |
|||||
| 3 | 100 | 800 | 1,5 | 900 |
||||||
| 4 | ||||||||||
| Counter. slave. | 118 | |||||||||
| Counter. slave. | 130 |
Information and its coding
Different approaches to the definition of the concept of "information". Types of information processes. Information aspect in human activity
Information(lat. information- clarification, presentation, set of information) - a basic concept in computer science, which cannot be given a strict definition, but can only be explained:
- information is new facts, new knowledge;
- information is information about objects and phenomena environment that increase the level of human awareness;
- information is information about objects and phenomena of the environment, which reduce the degree of uncertainty of knowledge about these objects or phenomena when making certain decisions.
The concept of "information" is general scientific, that is, it is used in various sciences: physics, biology, cybernetics, informatics, etc. At the same time, in each science this concept associated with various systems concepts. So, in physics, information is considered as anti-entropy (a measure of orderliness and complexity of a system). In biology, the concept of "information" is associated with the expedient behavior of living organisms, as well as with studies of the mechanisms of heredity. In cybernetics, the concept of "information" is associated with control processes in complex systems.
The main socially significant properties of information are:
- utility;
- accessibility (comprehensibility);
- relevance;
- completeness;
- authenticity;
- adequacy.
In human society, information processes are continuously taking place: people perceive information from the surrounding world with the help of the senses, comprehend it and accept it. certain decisions which, being embodied in real actions, influence the world around.
information process is the process of collecting (receiving), transmitting (exchanging), storing, processing (transforming) information.
Collection of information- this is the process of searching and selecting the necessary messages from various sources (working with special literature, reference books; conducting experiments; observations; polling, questioning; searching in information and reference networks and systems, etc.).
Transfer of information is the process of moving messages from a source to a receiver along a transmission channel. Information is transmitted in the form of signals - sound, light, ultrasonic, electrical, textual, graphic, etc. Transmission channels can be airspace, electrical and fiber optic cables, individuals, human nerve cells, etc.
Data storage is the process of fixing messages on a material carrier. Now paper, wooden, fabric, metal and other surfaces, film and photographic films, magnetic tapes, magnetic and laser discs, flash cards, etc.
Data processing is the process of obtaining new messages from existing ones. Information processing is one of the main ways to increase its quantity. As a result of processing, messages of other types can be obtained from a message of one type.
Data protection is the process of creating conditions that prevent accidental loss, damage, modification of information or unauthorized access to it. Ways to protect information are to create it backups, storage in a secure room, providing users with appropriate access rights to information, encrypting messages, etc.
Language as a way of presenting and transmitting information
Depending on the way of perception signs are divided into:
- visual (letters and numbers, mathematical signs, musical notes, road signs, etc.);
- auditory (oral speech, calls, sirens, beeps, etc.);
- tactile (Braille alphabet for the blind, touch gestures, etc.);
- olfactory;
- taste.
For long-term storage, signs are recorded on storage media.
Signs are used to convey information. signals(traffic light signals, school bell sound, etc.).
According to the way of communication between form and meaning signs are divided into:
- iconic- their shape is similar to the displayed object (for example, the icon of the "My Computer" folder on the "Desktop" of the computer);
- symbols— the relationship between their form and meaning is established by generally accepted convention (for example, letters, mathematical symbols ∫, ≤, ⊆, ∞; symbols of chemical elements).
Sign systems are used to represent information. languages. The basis of any language is alphabet- a set of characters from which the message is formed, and a set of rules for performing operations on characters.
Languages are divided into:
- natural(colloquial) - Russian, English, German, etc.;
- formal- encountered in special areas of human activity (for example, the language of algebra, programming languages, electrical circuits and etc.)
Number systems can also be seen as formal languages. So, the decimal number system is a language whose alphabet consists of ten digits 0..9, the binary number system is a language whose alphabet consists of two digits - 0 and 1.
Methods for measuring the amount of information: probabilistic and alphabetical
The unit for measuring the amount of information is bit. 1 bit is the amount of information contained in a message that halves the uncertainty of knowledge about something.
The relationship between the number of possible events N and the amount of information I is determined by Hartley formula:
For example, let the ball be in one of the four boxes. Thus, there are four equally probable events (N = 4). Then by Hartley's formula 4 = 2 I . Hence I = 2. That is, the message about which box the ball is in contains 2 bits of information.
Alphabetical approach
With an alphabetical approach to determining the amount of information, one abstracts from the content (meaning) of information and considers it as a sequence of signs of a certain sign system. The character set of a language (alphabet) can be thought of as different possible events. Then, if we assume that the appearance of characters in the message is equally likely, using the Hartley formula, we can calculate how much information each character carries:
For example, in Russian there are 32 letters (the letter ё is not usually used), i.e. the number of events will be 32. Then the information volume of one character will be equal to:
I = log 2 32 = 5 bits.
If N is not an integer power of 2, then log 2 N is not an integer, and I must be rounded up. When solving problems in this case, I can be found as log 2 N", where N′ is the nearest power of two to N — such that N′ > N.
For example, in English language 26 letters The information volume of one symbol can be found as follows:
N = 26; N" = 32; I = log 2 N" = log 2 (2 5) = 5 bits.
If the number of alphabetic characters is N, and the number of characters in the message record is M, then the information volume of this message is calculated by the formula:
I = M log 2 N.
Examples of problem solving
Example 1 The light board consists of light bulbs, each of which can be in one of two states (“on” or “off”). What is the minimum number of light bulbs that must be on the scoreboard so that it can transmit 50 different signals?
Solution. With the help of n light bulbs, each of which can be in one of two states, 2 n signals can be encoded. 25< 50 < 2 6 , поэтому пяти лампочек недостаточно, а шести хватит.
Answer: 6.
Example 2 The meteorological station monitors air humidity. The result of one measurement is an integer from 0 to 100, which is written using the minimum possible number of bits. The station made 80 measurements. Determine the information volume of the observation results.
Solution. In this case, the alphabet is a set of integers from 0 to 100. There are 101 such values in total. Therefore, the information volume of the results of one measurement is I = log 2 101. This value will not be integer. Let's replace the number 101 with the nearest power of two greater than 101. This number is 128 = 27. We take for one measurement I = log 2 128 = 7 bits. For 80 measurements, the total information volume is:
80 7 = 560 bits = 70 bytes.
Answer: 70 bytes.
Probabilistic approach
The probabilistic approach to measuring the amount of information is used when possible events have different probabilities of realization. In this case, the amount of information is determined according to the Shannon formula:
$I=-∑↙(i=1)↖(N)p_ilog_2p_i$,
where $I$ is the amount of information;
$N$ is the number of possible events;
$p_i$ is the probability of the $i$th event.
For example, let when throwing an asymmetrical tetrahedral pyramid, the probabilities of individual events will be equal:
$p_1=(1)/(2), p_2=(1)/(4), p_3=(1)/(8), p_4=(1)/(8)$.
Then the amount of information that will be obtained after the implementation of one of them can be calculated using the Shannon formula:
$I=-((1)/(2) log_2(1)/(2)+(1)/(4) log_2(1)/(4)+(1)/(8) log_2(1 )/(8)+(1)/(8) log_2(1)/(8))=(14)/(8)$ bits $= 1.75 $bits.
Units for measuring the amount of information
The smallest unit of information is bit(English) binary digit (bit) is a binary unit of information).
Bit is the amount of information required to unambiguously determine one of two equally likely events. For example, a person receives one bit of information when he finds out whether the train he needs is late with the arrival or not, whether it was frosty at night or not, student Ivanov is present at the lecture or not, etc.
In computer science, it is customary to consider sequences of 8 bits in length. Such a sequence is called byte.
Derived units for measuring the amount of information:
1 byte = 8 bits
1 kilobyte (KB) = 1024 bytes = 2 10 bytes
1 megabyte (MB) = 1024 kilobytes = 220 bytes
1 gigabyte (GB) = 1024 megabytes = 230 bytes
1 terabyte (TB) = 1024 gigabytes = 240 bytes
Information transfer process. Types and properties of information sources and receivers. Signal, encoding and decoding, causes of information distortion during transmission
Information is transmitted in the form of messages from some source information to her receiver through communication channel between them.
The source of information can be a living being or technical device. The source sends the transmitted message, which is encoded into the transmitted signal.
Signal is a material-energy form of information presentation. In other words, signal is a carrier of information, one or more parameters of which, by changing, display a message. Signals can be analog(continuous) or discrete(impulse).
The signal is sent over a communication channel. As a result, a received signal appears at the receiver, which is decoded and becomes the received message.
The transmission of information over communication channels is often accompanied by interference that causes distortion and loss of information.
Examples of problem solving
Example 1 To encode the letters A, Z, R, O, two-digit binary numbers 00, 01, 10, 11 are used, respectively. In this way, the word ROSE was encoded and the result was written in hexadecimal code. Specify the resulting number.
Solution. Let's write down the sequence of codes for each symbol of the word ROSE: 10 11 01 00. If we consider the resulting sequence as a binary number, then in the hexadecimal code it will be: 1011 0100 2 = B4 16.
Answer: B4 16 .
Information transfer rate and communication channel bandwidth
Reception / transmission of information can occur with different speed. The amount of information transmitted per unit of time is information transfer rate, or information flow rate.
The speed is expressed in bits per second (bps) and their multiples of Kbps and Mbps, as well as in bytes per second (bps) and their multiples of Kbps and Mbps.
The maximum rate of information transfer over a communication channel is called throughput channel.
Examples of problem solving
Example 1 The data transfer rate over an ADSL connection is 256,000 bps. File transfer via this compound took 3 min. Specify the size of the file in kilobytes.
Solution. The file size can be calculated by multiplying the information transfer rate by the transfer time. Let's express the time in seconds: 3 min = 3 ⋅ 60 = 180 s. Let's express the speed in kilobytes per second: 256000 bps = 256000: 8: 1024 KB/s. When calculating the file size, to simplify the calculations, we select powers of two:
File size = (256000:8:1024) ⋅ (3 ⋅ 60) = (2 8 ⋅ 10 3:2 3:2 10) ⋅ (3 ⋅ 15 ⋅ 2 2) = (2 8 ⋅ 125 ⋅ 2 3:2 3: 2 10) ⋅ (3 ⋅ 15 ⋅ 2 2) = 125 ⋅ 45 = 5625 KB.
Answer: 5625 KB.
Representation of numerical information. Addition and multiplication in different number systems
Representation of numerical information using number systems
To represent information in a computer, a binary code is used, the alphabet of which consists of two digits - 0 and 1. Each digit of the machine binary code carries an amount of information equal to one bit.
Notation is a system of writing numbers using a specific set of digits.
The number system is called positional, if the same digit has a different value, which is determined by its place in the number.
Positional is the decimal number system. For example, in the number 999, the number "9", depending on the position, means 9, 90, 900.
The Roman numeral system is non-positional. For example, the value of the number X in the number XXI remains unchanged when its position in the number varies.
The position of a digit in a number is called discharge. The digit of the number increases from right to left, from lower to higher digits.
The number of different digits used in the positional number system is called its basis.
Expanded form of a number is a record that is the sum of the products of the digits of a number and the value of the positions.
For example: 8527 = 8 ⋅ 10 3 + 5 ⋅ 10 2 + 2 ⋅ 10 1 + 7 ⋅ 10 0 .
An expanded form of writing numbers of an arbitrary number system has the form
$∑↙(i=n-1)↖(-m)a_iq^i$,
where $X$ is a number;
$a$ - digits of the numerical record corresponding to the digits;
$i$ - index;
$m$ is the number of digits of the fractional part;
$n$ is the number of digits of the number of the integer part;
$q$ is the base of the number system.
For example, let's write the expanded form of the decimal number $327.46$:
$n=3, m=2, q=10.$
$X=∑↙(i=2)↖(-2)a_iq^i=a_2 10^2+a_1 10^1+a_0 10^0+a_(-1) 10^(-1)+ a_(-2) 10^(-2)=3 10^2+2 10^1+7 10^0+4 10^(-1)+6 10^(-2)$
If the base of the number system used is greater than ten, then for the digits enter symbol with a bracket at the top or a letter designation: B - binary system, O - octal, H - hexadecimal.
For example, if in the duodecimal number system 10 \u003d A, and 11 \u003d B, then the number 7A,5B 12 can be painted like this:
7A,5B 12 \u003d B ⋅ 12 -2 + 5 ⋅ 2 -1 + A ⋅ 12 0 + 7 ⋅ 12 1.
There are 16 digits in the hexadecimal number system, denoted 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F, which corresponds to the following numbers in the decimal number system: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15. Number examples: 17D,ECH; F12AH.
Translation of numbers in positional number systems
Converting numbers from an arbitrary number system to decimal
To convert a number from any positional number system to decimal, it is necessary to use the expanded form of the number, replacing, if necessary, the letter designations with the corresponding numbers. For example:
1101 2 = 1 ⋅ 2 3 + 1 ⋅ 2 2 + 0 ⋅ 2 1 + 1 ⋅ 2 0 = 13 10 ;
17D,ECH = 12 ⋅ 16 -2 + 14 ⋅ 16 -1 + 13 ⋅ 160 + 7 ⋅ 16 1 + 1 ⋅ 16 2 = 381.921875.
Converting numbers from the decimal number system to the given one
To convert an integer from a decimal number system to a number of any other number system, successively divide by an integer by the base of the number system until zero is obtained. The numbers that appear as the remainder of division by the base of the system are a sequential record of the digits of the number in the selected number system from the least significant digit to the most significant. Therefore, to write the number itself, the remainders of the division are written in reverse order.
For example, let's translate decimal number 475 to binary number system. To do this, we will sequentially perform integer division by the base new system calculus, i.e. by 2:
Reading the remainder from the division from the bottom up, we get 111011011.
Examination:
1 ⋅ 2 8 + 1 ⋅ 2 7 + 1 ⋅ 2 6 + 0 ⋅ 2 5 + 1 ⋅ 2 4 + 1 ⋅ 2 3 + 0 ⋅ 2 2 + 1 ⋅ 2 1 + 1 ⋅ 2 0 = 1 + 2 + 8 + 16 + 64 + 128 + 256 = 475 10 .
To convert decimal fractions to a number of any number system, multiply by the base of the number system in sequence until fractional part product will not be zero. The integer parts obtained are the digits of the number in the new system, and they must be represented by the digits of this new number system. Whole parts are subsequently discarded.
For example, let's translate the decimal fraction 0.375 10 into the binary number system:

The result obtained is 0.011 2 .
Not every number can be exactly expressed in the new number system, so sometimes only the required number of fractional digits is calculated.
Converting numbers from binary to octal and hexadecimal and vice versa
Eight digits are used to write octal numbers, that is, in each digit of a number, 8 recording options are possible. Each bit of an octal number contains 3 bits of information (8 = 2 І; І = 3).
Thus, in order to convert a number from the octal number system to a binary code, it is necessary to represent each digit of this number as a triad of binary characters. Extra zeros in high-order bits are discarded.
For example:
1234,777 8 = 001 010 011 100,111 111 111 2 = 1 010 011 100,111 111 111 2 ;
1234567 8 = 001 010 011 100 101 110 111 2 = 1 010 011 100 101 110 111 2 .
When converting a binary number to an octal number system, each triad of binary digits must be replaced by an octal digit. In this case, if necessary, the number is aligned by adding zeros before the integer part or after the fractional part.
For example:
1100111 2 = 001 100 111 2 = 147 8 ;
11,1001 2 = 011,100 100 2 = 3,44 8 ;
110,0111 2 = 110,011 100 2 = 6,34 8 .
Sixteen digits are used to write hexadecimal numbers, that is, 16 notation options are possible for each digit of the number. Each bit of a hexadecimal number contains 4 bits of information (16 = 2 І ; І = 4).
Thus, to convert a binary number to hexadecimal, you need to break it into groups of four digits and convert each group to a hexadecimal digit.
For example:
1100111 2 = 0110 0111 2 = 67 16 ;
11,1001 2 = 0011,1001 2 = 3,9 16 ;
110,0111001 2 = 0110,0111 0010 2 = 65,72 16 .
To convert a hexadecimal number to a binary code, each digit of this number must be represented by four binary digits.
For example:
1234,AB77 16 = 0001 0010 0011 0100.1010 1011 0111 0111 2 = 1 0010 0011 0100.1010 1011 0111 0111 2 ;
CE4567 16 = 1100 1110 0100 0101 0110 0111 2 .
When converting a number from one arbitrary number system to another, you need to perform an intermediate conversion to a decimal number. When converting from octal to hexadecimal and vice versa, the auxiliary binary code of the number is used.
For example, let's translate the ternary number 211 3 into the septal number system. To do this, we first convert the number 211 3 to decimal, writing its expanded form:
211 3 = 2 ⋅ 3 2 + 1 ⋅ 3 1 + 1 ⋅ 3 0 = 18 + 3 + 1 = 22 10 .
Then we will translate the decimal number 22 10 into the septenary number system by dividing it entirely by the base of the new number system, i.e. by 7:
So, 211 3 = 31 7 .
Examples of problem solving
Example 1 In a number system with some base, the number 12 is written as 110. Indicate this base.
Solution. Let's designate the desired base n. By the rule of writing numbers in positional number systems 12 10 = 110 n = 0 ·n 0 + 1 · n 1 + 1 · n 2 . Let's make an equation: n 2 + n \u003d 12. Let's find the natural root of the equation (the negative root is not suitable, because the base of the number system, by definition, is a natural number greater than one): n = 3. Let's check the answer: 110 3 = 0 3 0 + 1 3 1 + 1 3 2 = 0 + 3 + 9 = 12 .
Answer: 3.
Example 2 Indicate, separated by commas, in ascending order, all the bases of the number systems in which the entry of the number 22 ends in 4.
Solution. The last digit in a number is the remainder of dividing the number by the base of the number system. 22 - 4 \u003d 18. Find the divisors of the number 18. These are the numbers 2, 3, 6, 9, 18. The numbers 2 and 3 are not suitable, because in the number systems with bases 2 and 3 there is no number 4. So, the desired bases are the numbers 6, 9 and 18. Let's check the result by writing the number 22 in the indicated number systems: 22 10 \u003d 34 6 \u003d 24 9 \u003d 14 18.
Answer: 6, 9, 18.
Example 3 Indicate, separated by commas, in ascending order, all numbers not exceeding 25, the entry of which in the binary system ends in 101. Write the answer in the decimal number system.
Solution. For convenience, we use the octal number system. 101 2 = 5 8 . Then the number x can be represented as x \u003d 5 8 0 + a 1 8 1 + a 2 8 2 + a 3 8 3 + ..., where a 1, a 2, a 3, ... are octal digits . The desired numbers should not exceed 25, so the expansion should be limited to the first two terms (8 2 > 25), i.e. such numbers should have the representation x = 5 + a 1 8. Since x ≤ 25, valid values a 1 will be 0, 1, 2. Substituting these values into the expression for x, we get the desired numbers:
a1 = 0; x = 5 + 0 8 = 5;.
a 1 =1; x = 5 + 1 8 = 13;.
a 1 = 2; x = 5 + 2 8 = 21;.
Let's check:
13 10 = 1101 2 ;
21 10 = 10101 2 .
Answer: 5, 13, 21.
Arithmetic operations in positional number systems
The rules for performing arithmetic operations on binary numbers are given by addition, subtraction and multiplication tables.
The rule for performing the addition operation is the same for all number systems: if the sum of the added digits is greater than or equal to the base of the number system, then the unit is transferred to the next digit on the left. When subtracting, if necessary, make a loan.
Execution example additions: add the binary numbers 111 and 101, 10101 and 1111:

Execution example subtractions: subtract the binary numbers 10001 - 101 and 11011 - 1101:

Execution example multiplications: multiply the binary numbers 110 and 11, 111 and 101:

Similarly, arithmetic operations are performed in octal, hexadecimal and other number systems. In this case, it should be taken into account that the amount of transfer to the next digit when adding and borrowing from the highest digit when subtracting is determined by the value of the base of the number system.
For example, let's add the octal numbers 368 and 158 and subtract the hexadecimal numbers 9C16 and 6716:

While doing arithmetic operations over the numbers presented in different systems calculus, you must first translate them into the same system.
Representation of numbers in a computer
Fixed point format
In computer memory, integers are stored in the format fixed point: each digit of the memory cell corresponds to the same digit of the number, the “comma” is outside the bit grid.
To store non-negative integers, 8 bits of memory are allocated. The minimum number corresponds to eight zeros stored in eight bits of the memory cell and is equal to 0. The maximum number corresponds to eight ones and is equal to
1 ⋅ 2 7 + 1 ⋅ 2 6 + 1 ⋅ 2 5 + 1 ⋅ 2 4 + 1 ⋅ 2 3 + 1 ⋅ 2 2 + 1 ⋅ 2 1 + 1 ⋅ 2 0 = 255 10 .
Thus, the range of non-negative integers is from 0 to 255.
For an n-bit representation, the range will be from 0 to 2n - 1.
Signed integers are stored in 2 bytes (16 bits). The most significant bit is assigned to the sign of the number: if the number is positive, then 0 is written to the sign bit, if the number is negative - 1. This representation of numbers in a computer is called direct code.
Used to represent negative numbers additional code. It allows you to replace the arithmetic operation of subtraction with the operation of addition, which greatly simplifies the work of the processor and increases its speed. The complementary code of the negative number A stored in n cells is 2 n − |A|.
Algorithm for obtaining an additional code of a negative number:
1. Write down the direct code of the number in n binary digits.
2. Get return number code. (The reverse code is formed from the direct code by replacing zeros with ones, and ones with zeros, except for the digits of the sign bit. For positive numbers, the reverse code is the same as the direct one. It is used as an intermediate link to obtain an additional code.)
3. Add one to the received return code.
For example, we get the two's complement code -2014 10 for a sixteen-bit representation:
With algebraic addition binary numbers using the complementary code, positive terms are represented in the direct code, and negative terms in the complementary code. These codes are then summed up, including the sign bits, which are treated as high bits. When transferring from a sign bit, the transfer unit is discarded. As a result, an algebraic sum is obtained in a direct code if this sum is positive, and in an additional code if the sum is negative.
For example:
1) Find the difference 13 10 - 12 10 for an eight-bit representation. Let's represent the given numbers in the binary system:
13 10 = 1101 2 and 12 10 = 1100 2 .
Let's write the direct, reverse and additional codes for the number -12 10 and the direct code for the number 13 10 in eight bits:
We will replace subtraction with addition (for the convenience of controlling the sign bit, we conditionally separate it with the sign "_"):

Since there was a transfer from the sign bit, we discard the first unit, and as a result we get 00000001.
2) Find the difference 8 10 - 13 10 for an eight-bit representation.
Let's write the direct, reverse and additional codes for the number -13 10 and the direct code for the number 8 10 in eight bits:
We replace subtraction with addition:

There is one in the sign bit, which means that the result is obtained in an additional code. Let's go from the additional code to the reverse, subtracting one:
11111011 - 00000001 = 11111010.
Let's move on from return code to direct, inverting all digits except for the sign (most significant) digit: 10000101. This is a decimal number -5 10 .
Since in the n-bit representation of a negative number A in the additional code, the most significant bit is allocated to store the sign of the number, the minimum negative number is: A = -2 n-1 , and the maximum: |A| = 2 n-1 or A = -2 n-1 - 1.
Define the range of numbers that can be stored in random access memory in the format signed long integers(To store such numbers, 32 bits of memory are allocated). The minimum negative number is
A \u003d -2 31 \u003d -2147483648 10.
The maximum positive number is
A \u003d 2 31 - 1 \u003d 2147483647 10.
The advantages of the fixed-point format are the simplicity and clarity of the representation of numbers, the simplicity of algorithms for the implementation of arithmetic operations. The disadvantage is a small range of representable numbers, which is insufficient for solving most applied problems.
floating point format
Real numbers are stored and processed in a computer in a format with floating point, which uses the exponential notation of numbers.
A number in exponential format is represented as follows:
where $m$ is the mantissa of the number (a proper non-zero fraction);
$q$ is the base of the number system;
$n$ is the order of the number.
For example, the decimal number 2674.381 in exponential form would be written like this:
2674,381 = 0,2674381 ⋅ 10 4 .
A floating point number can occupy 4 bytes in memory ( conventional accuracy) or 8 bytes ( double precision). When writing a number, bits are allocated to store the sign of the mantissa, the sign of the exponent, the exponent, and the mantissa. The last two values determine the range of the numbers and their accuracy.
Let's define the range (order) and precision (mantissa) for the format of ordinary precision numbers, that is, four-byte ones. Of the 32 bits, 8 are allocated to store the exponent and its sign, and 24 are allocated to store the mantissa and its sign.
Let's find the maximum value of the order of the number. Of the 8 bits, the most significant bit is used to store the sign of the order, the remaining 7 are used to record the order value. So the maximum value is 1111111 2 = 127 10 . Since numbers are represented in binary notation,
$q^n = 2^(127)≈ 1.7 10^(38)$.
Similarly, the maximum value of the mantissa is
$m = 2^(23) - 1 ≈ 2^(23) = 2^((10 2.3)) ≈ 1000^(2.3) = 10^((3 2.3)) ≈ 10^7$.
Thus, the range of ordinary precision numbers is $±1.7 · 10^(38)$.
Encoding of text information. ASCII encoding. The main used Cyrillic encodings
The correspondence between a set of characters and a set of numeric values is called character encoding. When text information is entered into a computer, it is encoded in binary. The character code is stored in the computer's RAM. In the process of displaying a character on the screen, the reverse operation is performed - decoding, i.e., the transformation of the character code into its image.
The specific numeric code assigned to each character is fixed in code tables Oh. The same character in different code tables can correspond to different numeric codes. The necessary text conversions are usually performed by special converter programs built into most applications.
As a rule, one byte (eight bits) is used to store a character code, so character codes can take a value from 0 to 255. Such encodings are called single-byte. They allow 256 characters (N = 2 I = 2 8 = 256). The table of single-byte character codes is called ASCII (American Standard Code for Information Interchange)— American Standard Code for Information Interchange). The first part of the ASCII code table (from 0 to 127) is the same for all IBM-PC compatible computers and contains:
- control character codes;
- codes of numbers, arithmetic operations, punctuation marks;
- some Special symbols;
- codes of large and small Latin letters.
The second part of the table (codes from 128 to 255) is different in various computers. It contains codes of letters of the national alphabet, codes of some mathematical symbols, codes of symbols of pseudographics. For Russian letters, five different code tables are currently used: KOI-8, SR1251, SR866, Mac, ISO.
Recently, a new international standard has become widespread Unicode. It takes two bytes (16 bits) to encode each character, so it can encode 65536 different characters (N = 2 16 = 65536). Character codes can take a value from 0 to 65535.
Examples of problem solving
Example. The following phrase is encoded using Unicode encoding:
I want to go to university!
Assess the information content of this phrase.
Solution. This phrase contains 31 characters (including spaces and punctuation). Since Unicode encodes 2 bytes of memory per character, the entire phrase would need 31 ⋅ 2 = 62 bytes, or 31 ⋅ 2 ⋅ 8 = 496 bits.
Answer: 32 bytes or 496 bits.