Prędzej czy później (lepiej oczywiście, jeśli wcześnie) każdy użytkownik zadaje sobie pytanie, jak długo zainstalował się na nim komputer ciężko dysk i czy nadszedł czas, aby poszukać dla niego zamiennika. Nie ma w tym nic dziwnego, skoro dyski twarde z racji ich cechy konstrukcyjne są najmniej niezawodne wśród komponentów komputerowych. Jednocześnie to właśnie na dysku twardym większość użytkowników przechowuje lwią część najróżniejszych informacji: dokumentów, zdjęć, różnego oprogramowania itp., w wyniku czego nieoczekiwana awaria dysku jest zawsze tragedią. Oczywiście często można odzyskać informacje na zewnętrznie „martwych” dyskach twardych, ale możliwe jest, że ta operacja będzie cię kosztować nieźle i będzie cię kosztować dużo nerwów. Dlatego o wiele skuteczniejsze jest zapobieganie utracie danych.
Jak? Bardzo proste... Po pierwsze, nie zapomnij o zwykłym utworzyć kopię zapasową dane, a po drugie, monitoruj stan dysków za pomocą specjalistycznych narzędzi. Rozważymy kilka programów takiego planu pod kątem zadań do rozwiązania w tym artykule.
Kontrola parametrów SMART i temperatury
Wszystkie nowoczesne dyski twarde, a nawet dyski półprzewodnikowe (SSD) obsługują S.M.A.R.T. ( z angielskiego. Self-Monitoring, Analysis, and Reporting Technology - technologia samodzielnego monitorowania, analizy i raportowania), która została opracowana przez największych producentów dyski twarde poprawić niezawodność swoich produktów. Technologia ta opiera się na ciągłym monitorowaniu i ocenie stanu dysku twardego przez wbudowany sprzęt autodiagnostyczny (specjalne czujniki), a jej głównym celem jest szybkie wykrycie ewentualnej awarii dysku.
Monitorowanie stanu dysku twardego w czasie rzeczywistym
Szereg rozwiązań informacyjno-diagnostycznych do diagnostyki i testowania sprzętu, a także specjalne narzędzia monitorujące, wykorzystuje S.M.A.R.T. monitorować aktualny stan różnych życiowych ważne parametry opisujący niezawodność i wydajność dysków twardych. Odczytują odpowiednie parametry bezpośrednio z czujników i czujników termicznych, w które wyposażone są wszystkie nowoczesne dyski twarde, analizują otrzymane dane i wyświetlają je w formie zwięzłego raportu tabelarycznego z listą atrybutów. Jednocześnie niektóre narzędzia (Hard Drive Inspector, HDDlife, Crystal Disk Info itp.) nie ograniczają się do wyświetlania tabeli atrybutów (których wartości są niezrozumiałe dla nieprzygotowanych użytkowników) i dodatkowo wyświetlają krótkie informacje o stanie dysku w bardziej zrozumiałej formie.
Diagnozowanie stanu dysku twardego za pomocą tego rodzaju narzędzi jest tak proste, jak łuskanie gruszek - wystarczy zapoznać się z krótkimi podstawowymi informacjami o zainstalowanych dyskach twardych: z podstawowymi danymi o dyskach w Hard Drive Inspector, pewnym warunkowym procentem stanu dysku twardego w HDDlife , wskaźnik „Stan techniczny” w Crystal Disk Info (ryc. 1) itp. Każdy z tych programów zapewnia minimum niezbędnych informacji o każdym z dysków twardych zainstalowanych w komputerze: dane o modelu dysku twardego, jego objętości, temperaturze pracy, przepracowanych godzinach, a także poziomie niezawodności i wydajności. Informacje te pozwalają na wyciągnięcie pewnych wniosków na temat działania przewoźnika.
Ryż. 1. Krótka informacja o „kondycji” działającego dysku twardego
Należy skonfigurować uruchamianie narzędzia do monitorowania w momencie uruchamiania systemu operacyjnego, dostosować odstępy czasu między sprawdzaniem atrybutów S.M.A.R.T., a także włączyć wyświetlanie temperatury i „poziomu kondycji” dysków twardych w zasobniku systemowym. Następnie, aby kontrolować stan dysków, użytkownik będzie musiał tylko od czasu do czasu zerknąć na wskaźnik w zasobniku systemowym, gdzie będzie wyświetlany krótka informacja o stanie dostępnych w systemie dysków: ich poziomie „kondycji” i temperaturze (rys. 2). Nawiasem mówiąc, temperatura robocza jest nie mniej ważnym wskaźnikiem niż warunkowy wskaźnik stanu dysku twardego, ponieważ dyski twarde mogą nagle ulec awarii z powodu banalnego przegrzania. Dlatego jeśli dysk twardy nagrzewa się powyżej 50°C, rozsądniej byłoby zapewnić mu dodatkowe chłodzenie.
Ryż. 2. Wyświetlanie stanu dysku twardego
w zasobniku systemowym z programem HDDlife
Należy zauważyć, że niektóre z tych narzędzi zapewniają integrację z Eksplorator Windows, aby ikony dysków lokalnych wyświetlały zieloną ikonę, jeśli są w dobrym stanie, a ikona zmienia kolor na czerwony, jeśli wystąpią problemy. Więc prawdopodobnie nie będziesz w stanie zapomnieć o stanie swoich dysków twardych. Przy takim stałym monitorowaniu nie będziesz mógł przegapić momentu, w którym zaczną pojawiać się problemy z dyskiem, ponieważ jeśli narzędzie wykryje krytyczne zmiany w S.M.A.R.T. i/lub temperatury, dokładnie powiadomi o tym użytkownika (komunikatem na ekranie, komunikatem dźwiękowym itp. - rys. 3). Dzięki temu będzie można z góry mieć czas na skopiowanie danych z budzącego strach nośnika.

Ryż. 3. Przykładowy komunikat o konieczności natychmiastowej wymiany dysku
Wykorzystanie rozwiązań monitorujących S.M.A.R.T. w praktyce do monitorowania stanu dysków twardych jest całkowicie proste, ponieważ wszystkie takie narzędzia działają w tle i wymagają minimum zasobów sprzętowych, więc ich działanie w żaden sposób nie zakłóci głównego przepływu pracy.
Kontrola atrybutów S.M.A.R.T.
Zaawansowani użytkownicy oczywiście raczej nie ograniczą się do oceny stanu dysków twardych, przeglądając krótki werdykt jednego z przedstawionych powyżej narzędzi. Jest to zrozumiałe, ponieważ dekodując atrybuty S.M.A.R.T. możliwe jest zidentyfikowanie przyczyny awarii i, jeśli to konieczne, rozważne podjęcie dodatkowych działań. To prawda, że aby niezależnie kontrolować atrybuty S.M.A.R.T., będziesz musiał przynajmniej krótko zapoznać się z S.M.A.R.T.
Dyski twarde obsługujące tę technologię zawierają inteligentne procedury autodiagnostyki, dzięki czemu są w stanie „zgłosić” swój aktualny stan. Te informacje diagnostyczne są dostarczane jako zbiór atrybutów, tj. specyficznych cech dysku twardego używanych do analizy jego wydajności i niezawodności.
B o Większość ważnych atrybutów ma takie samo znaczenie dla napędów wszystkich producentów. Wartości tych atrybutów podczas normalnej pracy dysku mogą się różnić w określonych odstępach czasu. Dla każdego parametru producent określił pewną minimalną bezpieczną wartość, której nie można przekroczyć w normalnych warunkach pracy. Jednoznaczne określenie krytycznych i niekrytycznych parametrów S.M.A.R.T do diagnostyki. problematyczny. Każdy z atrybutów ma swoją wartość informacyjną i wskazuje na taki lub inny aspekt pracy przewoźnika. Przede wszystkim jednak należy zwrócić uwagę na następujące atrybuty:
- Raw Read Error Rate - częstotliwość błędów odczytu danych z dysku z powodu awarii sprzętu;
- Spin Up Time - średni czas rozpędzania wrzeciona dysku;
- Reallocated Sector Count - liczba operacji remapowania sektora;
- Seek Error Rate - częstotliwość występowania błędów pozycjonowania;
- Liczba ponownych prób rozkręcenia — liczba ponownych prób rozkręcenia dysków do prędkości operacyjnej, jeśli pierwsza próba się nie powiedzie;
- Current Pending Sector Count - liczba niestabilnych sektorów (czyli sektorów oczekujących na procedurę remapowania);
- Offline Scan Uncorrectable Count — całkowita liczba nieskorygowanych błędów podczas operacji odczytu/zapisu sektora.
Zazwyczaj S.M.A.R.T. są wyświetlane w formie tabelarycznej z nazwą atrybutu (Attribute), jego identyfikatorem (ID) oraz trzema wartościami: aktualna (Value), minimalny próg (Threshold) i najniższa wartość atrybutu dla całego czasu jazdy (Najgorszy) , a także wartość bezwzględną atrybutu (surowe). Każdy atrybut ma bieżącą wartość, która może być dowolną liczbą z zakresu od 1 do 100, 200 lub 253 (nie ma ogólnego standardu górnych granic wartości atrybutów). Wartości Value i Najgorsze dla zupełnie nowego dysku twardego są takie same (ryc. 4).

Ryż. 4. Atrybuty S.M.A.R.T. na nowym dysku twardym
Pokazano na ryc. 4 informacje pozwalają stwierdzić, że dla teoretycznie sprawnego dysku twardego wartości aktualna (wartość) i najgorsza (najgorsza) powinny być jak najbardziej zbliżone do siebie, a wartość surowa dla większości parametrów (z wyjątkiem parametrów: Power-On Time, HDA Temperature i kilka innych) powinny być bliskie zeru. Obecna wartość może się zmieniać w czasie, co w większości przypadków odzwierciedla pogorszenie ciężko dysk opisany przez atrybut. Widać to na ryc. 5, który pokazuje fragmenty tabeli atrybutów S.M.A.R.T. dla tego samego dysku - dane są odbierane w odstępie półrocznym. Jak widać, w nowszej wersji S.M.A.R.T. zwiększona stopa błędów podczas odczytu danych z dysku (Raw Read Error Rate), których pochodzenie wynika ze sprzętu dysku, oraz stopa błędów podczas pozycjonowania bloku głowic magnetycznych (Seek Error Rate), co może wskazywać na przegrzanie dysku twardego i jego niestabilnej pozycji w koszu. Jeśli bieżąca wartość dowolnego atrybutu zbliża się do wartości progowej lub staje się niższa niż próg, dysk twardy jest uważany za zawodny i należy go pilnie wymienić. Np. spadek wartości atrybutu Czas rozpędzania (średni czas rozpędu wrzeciona dysku) poniżej wartości krytycznej, z reguły świadczy o całkowitym zużyciu mechaniki, w wyniku czego dysk nie jest już w stanie utrzymać prędkości obrotowej określonej przez producenta. Dlatego konieczne jest monitorowanie stanu dysku twardego i okresowe (np. raz na 2-3 miesiące) przeprowadzanie S.M.A.R.T. i zapisz otrzymane informacje w pliku tekstowym. W przyszłości dane te można będzie porównać z obecnymi i wyciągnąć pewne wnioski dotyczące rozwoju sytuacji.

Ryż. 5. Tabele atrybutów S.M.A.R.T uzyskiwane w odstępach półrocznych
(nowsza wersja S.M.A.R.T. poniżej)
Przeglądając atrybuty S.M.A.R.T., należy przede wszystkim zwrócić uwagę na parametry krytyczne, a także parametry wyróżnione wskaźnikami innymi niż kolor bazowy (zwykle niebieski lub zielony). W zależności od aktualnego stanu atrybutu w S.M.A.R.T. w tabeli jest zwykle oznaczony takim lub innym kolorem, co ułatwia zrozumienie sytuacji. W szczególności w programie Hard Drive Inspector kolorem wskaźnika może być zielony, żółto-zielony, żółty, pomarańczowy lub czerwony - kolory zielony i żółto-zielony wskazują, że wszystko jest w porządku (wartość atrybutu nie zmieniła się lub zmieniła się nieznacznie), a kolory żółty, pomarańczowy i czerwony sygnalizują niebezpieczeństwo (najgorszy jest czerwony, co oznacza, że wartość atrybutu osiągnęła wartość krytyczną). Jeśli którykolwiek z krytycznych parametrów jest oznaczony czerwoną ikoną, musisz pilnie wymienić dysk twardy.
Spójrzmy na tabelę atrybutów S.M.A.R.T. tego samego dysku w programie Hard Drive Inspector, których krótką ocenę za pomocą narzędzi monitorujących podano wcześniej. Z ryc. 6 pokazuje, że wartości wszystkich atrybutów są normalne, a wszystkie parametry są zaznaczone na zielono. Narzędzia HDDlife i Crystal Disk Info pokażą podobny obraz. To prawda, że bardziej profesjonalne rozwiązania do analizy i diagnostyki dysków twardych nie są tak lojalne i często bardziej skrupulatnie przypisują atrybuty S.M.A.R.T. Na przykład tak znane narzędzia, jak HD Tune Pro i HDD Scan, w naszym przypadku były podejrzane o atrybut UltraDMA CRC Errors, który wyświetla liczbę błędów występujących podczas przesyłania informacji przez interfejs zewnętrzny (rys. 7) . Przyczyną takich błędów jest zwykle skręcony i złej jakości kabel SATA, który może wymagać wymiany.

Ryż. 6. Tabela atrybutów S.M.A.R.T. uzyskanych w programie Hard Drive Inspector

Ryż. 7. Wyniki oceny stanu atrybutów S.M.A.R.T.
Narzędzia HD Tune Pro i HDD Scan
Dla porównania zapoznajmy się z atrybutami S.M.A.R.T. bardzo starego, ale wciąż działającego dysku twardego z sporadycznymi problemami. Nie wzbudził zaufania do programu Crystal Disk Info – we wskaźniku „Stan techniczny” stan dysku został oceniony jako alarmujący, a atrybut Reallocated Sector Count (Reassigned sector) okazał się podświetlony na żółto (ryc. 8). Jest to bardzo ważny atrybut z punktu widzenia „kondycji” dysku, wskazujący na ilość przemapowanych sektorów, gdy dysk wykryje błąd odczytu/zapisu, podczas tej operacji dane ze uszkodzonego sektora są przekazywane do zapasowego powierzchnia. Żółty kolor wskaźnika obok parametru wskazuje, że nie ma wystarczającej liczby pozostałych sektorów zapasowych, którymi można zastąpić uszkodzone sektory, a wkrótce nie będzie nic, co można by ponownie przypisać nowo pojawiającym się uszkodzonym sektorom. Sprawdźmy też, jak poważniejsze rozwiązania oceniają stan dysku, na przykład szeroko wykorzystywane przez profesjonalistów narzędzie HDDScan – tutaj jednak widzimy dokładnie ten sam wynik (rys. 9).

Ryż. 8. Oceń problematyczny dysk twardy w CrystalDiskInfo

Ryż. 9. Wyniki diagnostyki HDD S.M.A.R.T. w HDDScan
Oznacza to, że oczywiście nie warto ciągnąć się z wymianą takiego dysku twardego, chociaż może jeszcze służyć przez jakiś czas, chociaż oczywiście nie można zainstalować systemu operacyjnego na tym dysku twardym. Należy zauważyć, że jeśli istnieje duża liczba przeniesionych sektorów, prędkość odczytu/zapisu spada (z powodu niepotrzebnych ruchów, które musi wykonywać głowica magnetyczna), a dysk zaczyna zauważalnie zwalniać.
Skanowanie powierzchni pod kątem uszkodzonych sektorów
Niestety w praktyce jedna kontrola parametrów SMART i temperatury to za mało. Gdy jest najmniejsze oznaki, że coś jest nie tak z dyskiem (w przypadku okresowego zawieszania się programu, np. podczas zapisywania wyników, odczytywania komunikatów o błędach itp.), należy przeskanować powierzchnię dysku w poszukiwaniu nieczytelnych sektorów. Aby przeprowadzić taką kontrolę nośnika, możesz użyć na przykład narzędzi HD Tune Pro i HDDScan lub narzędzi diagnostycznych producentów dysków twardych, jednak te narzędzia działają tylko z ich modelami dysków twardych i dlatego nie będziemy brać pod uwagę ich.
Przy korzystaniu z takich rozwiązań istnieje ryzyko uszkodzenia danych na skanowanym dysku. Z jednej strony dzięki informacjom na dysku, jeśli dysk rzeczywiście okaże się uszkodzony, podczas skanowania może się zdarzyć wszystko. Z drugiej strony nie można wykluczyć błędnych działań ze strony użytkownika, który omyłkowo rozpoczyna skanowanie w trybie zapisu, podczas którego następuje nadpisywanie sektor po sektorze danych z dysku twardego o określonej sygnaturze i na podstawie szybkość tego procesu, wyciąga się wniosek o stanie dysku twardego. Dlatego bezwzględnie konieczne jest przestrzeganie pewnych zasad ostrożności: przed uruchomieniem narzędzia należy utworzyć kopię zapasową informacji i podczas sprawdzania postępować ściśle według instrukcji twórcy odpowiedniego oprogramowania. Aby uzyskać dokładniejsze wyniki przed skanowaniem, lepiej zamknąć wszystkie aktywne aplikacje i zwolnić możliwe procesy w tle. Ponadto należy pamiętać, że jeśli chcesz przetestować systemowy dysk twardy, musisz uruchomić komputer z dysku flash i rozpocząć z niego proces skanowania lub całkowicie usunąć dysk twardy i podłączyć go do innego komputera, z którego rozpocząć testowanie dysku.
Na przykład za pomocą HD Tune Pro sprawdzimy powierzchnię dysku twardego pod kątem uszkodzonych sektorów, co powyżej nie wzbudziło zaufania do narzędzia Crystal Disk Info. W tym programie, aby rozpocząć proces skanowania, wystarczy wybrać żądany dysk, aktywować zakładkę skanowanie błędów i kliknij przycisk początek. Następnie narzędzie rozpocznie sekwencyjne skanowanie dysku, odczytując sektor po sektorze i oznaczając sektory na mapie dysku wielokolorowymi kwadratami. Kolor kwadratów, w zależności od sytuacji, może być zielony (normalne sektory) lub czerwony (złe bloki) lub będzie mieć pewien odcień pośredni między tymi kolorami. Jak widać z ryc. 10, w naszym przypadku narzędzie nie znalazło pełnoprawnych złych bloków, ale mimo to istnieje solidna liczba sektorów z jednym lub drugim opóźnieniem odczytu (sądząc po ich kolorze). Oprócz tego w środkowej części dysku znajduje się mały blok sektorów, których kolor jest zbliżony do czerwonego - sektory te nie zostały jeszcze rozpoznane przez narzędzie jako złe, ale są już blisko niego i w najbliższej przyszłości trafi do kategorii złych.
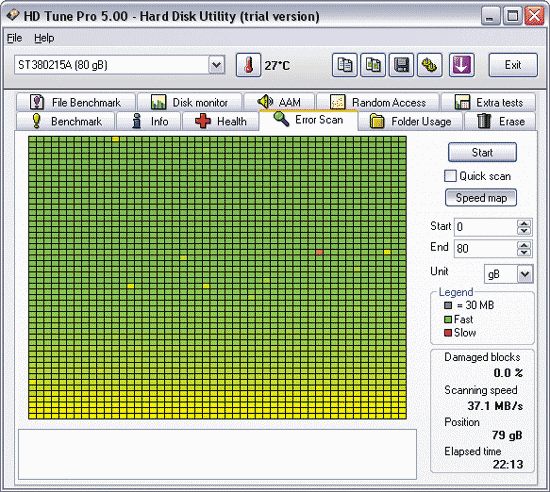
Ryż. 10. Skanowanie powierzchni w poszukiwaniu uszkodzonych sektorów w HD Tune Pro
Testowanie nośnika pod kątem uszkodzonych sektorów w programie HDDScan jest trudniejsze, a nawet bardziej niebezpieczne, ponieważ w przypadku błędnie wybranego trybu informacje na dysku zostaną bezpowrotnie utracone. Przede wszystkim, aby rozpocząć skanowanie, utwórz nowe zadanie, klikając przycisk Nowe zadanie i wybierając polecenie z listy Testy Suface. Następnie musisz się upewnić, że tryb jest wybrany czytać- ten tryb jest ustawiony domyślnie i gdy jest używany, powierzchnia dysku twardego jest testowana przez odczyt (czyli bez usuwania danych). Następnie naciśnij przycisk Dodaj test(Rys. 11) i kliknij dwukrotnie utworzone zadanie RD Czytaj. Teraz w oknie, które się otworzy, możesz obserwować proces skanowania dysku na wykresie (Wykres) lub na mapie (Mapa) - ryc. 12. Po zakończeniu procesu otrzymamy w przybliżeniu te same wyniki, które zostały zademonstrowane powyżej przez narzędzie HD Tune Pro, ale z jaśniejszą interpretacją: nie ma uszkodzonych sektorów (są zaznaczone na niebiesko), ale są trzy sektory z czasem reakcji przekraczającym 500 ms (zaznaczone na czerwono), co stanowi realne zagrożenie. Jeśli chodzi o sześć pomarańczowych sektorów (czas odpowiedzi od 150 do 500 ms), można to uznać za normalny zakres, ponieważ takie opóźnienie odpowiedzi jest często spowodowane chwilową ingerencją w postaci np. uruchomionych programów działających w tle.

Ryż. 11. Uruchom test dysku w HDDScan

Ryż. 12. Wyniki skanowania dysku w trybie odczytu za pomocą HDDScan
Ponadto należy zauważyć, że w przypadku niewielkiej liczby uszkodzonych bloków można spróbować poprawić stan dysku twardego, usuwając uszkodzone sektory, skanując powierzchnię dysku w trybie nagrywania liniowego (Erase) za pomocą programu HDDScan. Po takiej operacji dysk może być jeszcze przez jakiś czas używany, ale oczywiście nie jako dysk systemowy. Nie należy jednak liczyć na cud, ponieważ dysk twardy już zaczął się kruszyć i nie ma gwarancji, że w najbliższej przyszłości liczba usterek nie wzrośnie, a dysk nie ulegnie całkowitej awarii.
Programy do monitorowania S.M.A.R.T. i testowania HDD
HD Tune Pro 5.00 i HD Tune 2.55
Deweloper: Oprogramowanie EFD
Wielkość dystrybucji: HD Tune Pro — 1,5 MB; Dostrajanie HD — 628 KB
Praca pod kontrolą: Windows XP/Serwer 2003/Vista/7
Sposób dystrybucji: HD Tune Pro - shareware (15-dniowe demo); HD Tune - darmowy (http://www.hdtune.com/download.html)
Cena £: HD Tune Pro - 34,95 USD; HD Tune — bezpłatnie (tylko do użytku niekomercyjnego)
HD Tune to przydatne narzędzie do diagnozowania i testowania HDD/SSD (patrz tabela), a także kart pamięci, napędów USB i wielu innych urządzeń pamięci masowej. Program wyświetla szczegółowe informacje o napędzie (wersja oprogramowania, numer seryjny, rozmiar dysku, rozmiar bufora i tryb przesyłania danych) oraz umożliwia ustawienie stanu urządzenia za pomocą danych S.M.A.R.T. i monitorowanie temperatury. Dodatkowo może służyć do testowania powierzchni dysku pod kątem błędów oraz oceny wydajności urządzenia poprzez przeprowadzenie szeregu testów (sekwencyjne i losowe testy prędkości odczytu/zapisu, test wydajności plików, test pamięci podręcznej oraz szereg dodatkowych testów) . Narzędzie może być również używane do konfigurowania AAM i bezpiecznego usuwania danych. Program prezentowany jest w dwóch edycjach: komercyjnej HD Tune Pro i bezpłatnej lekkiej HD Tune. W edycji HD Tune dostępne jest tylko przeglądanie szczegółowych informacji o dysku i tabeli atrybutów S.M.A.R.T., a także skanowanie dysku w poszukiwaniu błędów i testowanie szybkości w trybie odczytu (test niskiego poziomu - odczyt).
Zakładka Zdrowie odpowiada za monitorowanie atrybutów S.M.A.R.T w programie - dane z czujników są odczytywane po zadanym czasie, wyniki wyświetlane są w tabeli. Dla dowolnego atrybutu możesz przeglądać historię jego zmian w postaci liczbowej i na wykresie. Dane monitorowania są automatycznie rejestrowane, ale nie są dostarczane żadne powiadomienia użytkownika o krytycznych zmianach parametrów.
Jeśli chodzi o skanowanie powierzchni dysku w poszukiwaniu uszkodzonych sektorów, za tę operację odpowiada zakładka. błąd Skanowanie. Skanowanie może być szybkie (szybkie skanowanie) i głębokie - z szybkie sprawdzenie nie cały dysk jest skanowany, ale tylko jego część (obszar skanowania jest określany przez pola Start i End). Uszkodzone sektory są wyświetlane na mapie dysku jako czerwone bloki.
HDDScan 3.3
Deweloper: Artem Rubtsov
Wielkość dystrybucji: 3,64 MB
Praca pod kontrolą: Windows 2000(SP4)/XP(SP2/SP3)/Serwer 2003/Vista/7
Sposób dystrybucji: darmowe oprogramowanie (http://hddscan.com/download/HDDScan-3.3.zip)
Cena £: jest wolny
HDDScan to narzędzie do niskopoziomowej diagnostyki dysków twardych, dysków półprzewodnikowych i dysków flash z Interfejs USB. Głównym celem tego programu jest testowanie dysków pod kątem uszkodzonych bloków i uszkodzonych sektorów. Narzędzie może być również używane do przeglądania zawartości S.M.A.R.T., monitorowania temperatury i zmiany niektórych ustawień dysku twardego: zarządzania hałasem (AAM), zarządzania energią (APM), wymuszonego uruchamiania / zatrzymywania wrzeciona napędu itp. Program działa bez instalacji i mogą być uruchamiane z nośników przenośnych, takich jak dyski flash.
Wyświetlanie atrybutów S.M.A.R.T. i monitorowanie temperatury w HDDScan odbywa się na żądanie. Raport S.M.A.R.T. zawiera informacje o wydajności i „kondycji” dysku w postaci standardowej tabeli atrybutów, temperatura dysku jest wyświetlana w zasobniku systemowym oraz w specjalnym oknie informacyjnym. Raporty można drukować lub zapisywać jako plik MHT. Możliwe są testy S.M.A.R.T.
Sprawdzanie powierzchni dysku odbywa się w jednym z czterech trybów: Verify (tryb weryfikacji liniowej), Read (odczyt liniowy), Erase (zapis liniowy) oraz Butterfly Read (tryb odczytu motylkowego). Aby sprawdzić dysk pod kątem obecności uszkodzonych bloków, zwykle stosuje się test w trybie odczytu, za pomocą którego testowana jest powierzchnia bez usuwania danych (wniosek dotyczący stanu dysku jest dokonywany na podstawie prędkości sektora- odczyt danych według sektorów). Podczas testowania w trybie nagrywania liniowego (Erase) informacje na dysku są nadpisywane, ale ten test może nieco wyleczyć dysk, usuwając z niego uszkodzone sektory. W każdym z trybów można całkowicie przetestować cały dysk lub określony jego fragment (obszar skanowania jest określany przez określenie początkowego i końcowego sektora logicznego - odpowiednio Start LBA i End LBA). Wyniki testu prezentowane są w formie raportu (zakładka Report) i wyświetlane na wykresie (Graph) oraz mapie dysku (Mapa) wskazujące m.in. liczbę uszkodzonych sektorów (Bads) oraz sektorów, których czas odpowiedzi podczas testowanie trwało ponad 500 ms (oznaczone na czerwono).
Inspektor dysków twardych 4.13
Deweloper: AltrixSoft
Wielkość dystrybucji: 2,64 MB
Praca pod kontrolą: Windows 2000/XP/2003 Serwer/Vista/7
Sposób dystrybucji: shareware (14-dniowe demo - http://www.altrixsoft.com/ru/download/)
Cena £: Hard Drive Inspector Professional - 600 rubli; Inspektor dysku twardego dla notebooków - 800 rubli.
Hard Drive Inspector to poręczne rozwiązanie do monitorowania S.M.A.R.T zewnętrznych i wewnętrznych dysków twardych. W ten moment program oferowany jest na rynku w dwóch edycjach: podstawowej Hard Drive Inspector Professional oraz przenośnej Hard Drive Inspector for Notebooks; ta ostatnia zawiera wszystkie funkcjonalności wersji Professional, a jednocześnie uwzględnia specyfikę monitorowania dysków twardych w laptopach. Teoretycznie istnieje inna wersja dysku SSD, ale dystrybuowana jest tylko w dostawach OEM.
Program zapewnia automatyczne sprawdzenie S.M.A.R.T.-atrybuty w określonych odstępach czasu i po zakończeniu wydaje werdykt o stanie napędu z wyświetlaniem wartości niektórych wskaźników warunkowych: „niezawodność”, „wydajność” i „brak błędów” wraz z liczbową wartością temperatury i wykres temperatury. Zawiera również dane techniczne dotyczące modelu napędu, jego pojemności, całkowitej wolnej przestrzeni i czasu pracy w godzinach (dni). W trybie zaawansowanym można wyświetlić informacje o parametrach dysku (rozmiar bufora, nazwa oprogramowania układowego itp.) oraz tabelę atrybutów S.M.A.R.T. Istnieją różne opcje informowania użytkownika w przypadku krytycznych zmian na dysku. Dodatkowo narzędzie może być używane do zmniejszenia poziomu hałasu wytwarzanego przez dyski twarde i zmniejszenia zużycia energii przez dysk twardy.
Życie w HD 4.0
Deweloper: BinarySense Sp.
Wielkość dystrybucji: 8,45 MB
Praca pod kontrolą: Windows 2000/XP/2003/Vista/7/8
Sposób dystrybucji: shareware (15-dniowe demo - http://hddlife.ru/rus/downloads.html)
Cena £: HDDlife - za darmo; HDDLife Pro - 300 rubli; HDDlife dla notebooków - 500 rubli.
HDDLife to proste narzędzie przeznaczone do monitorowania stanu dysków twardych i SSD (od wersji 4.0). Program prezentowany jest w trzech edycjach: darmowej HDDLife oraz dwóch komercyjnych - podstawowej HDDLife Pro oraz przenośnej HDDlife for Notebooks.
Narzędzie monitoruje atrybuty i temperaturę S.M.A.R.T. w określonych odstępach czasu i, na podstawie wyników analizy, wydaje kompaktowy raport o stanie dysku, wskazując dane techniczne modelu dysku i jego pojemności, przepracowanych godzin, temperatury, a także wyświetla warunkowy procent jego zdrowia i wydajności, co pozwala na poruszanie się w sytuacji nawet początkującym. Więcej zaawansowani użytkownicy dodatkowo mogą spojrzeć na tabelę atrybutów S.M.A.R.T. W przypadku problemów z dyskiem twardym istnieje możliwość skonfigurowania powiadomień; możesz skonfigurować program tak, aby przy normalnym stanie dysku wyniki sprawdzenia nie były wyświetlane. Można kontrolować poziom hałasu dysku twardego i zużycie energii.
CrystalDiskInfo 5.4.2
Deweloper: Hijohijo
Wielkość dystrybucji: 1,79 MB
Praca pod kontrolą: Windows XP/2003/Vista/2008/7/8/2012
Sposób dystrybucji: darmowe oprogramowanie (http://crystalmark.info/download/index-e.html)
Cena £: jest wolny
CrystalDiskInfo to prosty S.M.A.R.T. zewnętrzny dysk twardy) i SSD. Pomimo darmowego oprogramowania, program posiada wszystkie niezbędne funkcje do organizowania monitorowania stanu dysku.
Dyski są monitorowane automatycznie po określonej liczbie minut lub na żądanie. Po zakończeniu testu w zasobniku systemowym wyświetlana jest temperatura monitorowanych urządzeń; Szczegółowe informacje o dysku twardym z wartościami S.M.A.R.T., temperaturą i oceną programu na temat stanu urządzeń są dostępne w głównym oknie narzędzia. Istnieje funkcjonalność ustawiania wartości progowych dla niektórych parametrów i automatycznego powiadamiania użytkownika o ich przekroczeniu. Możliwe jest zarządzanie poziomem hałasu (AAM) i zarządzanie energią (APM).
Niestety duża część nowoczesnych dysków twardych pracuje normalnie nieco ponad rok, potem zaczynają się różnego rodzaju problemy, które z czasem mogą doprowadzić do utraty danych. Takiej perspektywy można uniknąć, jeśli uważnie monitoruje się ciężko dysk, na przykład za pomocą narzędzi omówionych w artykule. Nie należy jednak zapominać o regularnym tworzeniu kopii zapasowych cennych danych, ponieważ narzędzia monitorujące z reguły skutecznie przewidują awarię dysku z winy „mechaniki” (według statystyk Seagate około 60% dysków twardych ulega awarii z powodu elementów mechanicznych), ale nie są w stanie przewidzieć śmierci napędu z powodu problemów z części elektroniczne dysk.
Podczas wyświetlania parametrów S.M.A.R.T wartość musi przekraczać próg (wartość parametru krytycznego), wartość ta musi być wysoka.
Zielony znacznik atrybutu wskazuje, że parametr atrybutu jest normalny.
Żółty znacznik wskazuje na niewielką rozbieżność.
Czerwony - są to duże rozbieżności, przy tym parametrze dysk twardy może ulec awarii w każdej chwili, przechowywanie na nim danych jest niebezpieczne.
Wskaźnik błędu czystego odczytu- ten atrybut wyświetla stopę błędów podczas odczytu z dysku.
Czas rozkręcania- atrybut promocji dysku do stanu roboczego, złej jakości zasilacz może wpłynąć na różnicę z wartością referencyjną.
Licznik start/stop- liczba uruchomień i zatrzymań dysku twardego.
Liczba przeniesionych sektorów- licznik ponownie przydzielonych sektorów, pokazujący liczbę zapasowych sektorów zdolnych do zastąpienia uszkodzonych, najważniejszy parametr dla wydajności dysku twardego. Gdy system dysku twardego wykryje błąd odczytu / zapisu, sektor jest nadpisywany do obszaru rezerwowego, ten parametr najwyraźniej pokazuje wydajność dysku twardego, a co najważniejsze, ten atrybut nie może być poprawiony przez żadne programy. Przy krytycznie niskim wskaźniku tego parametru warto pomyśleć o wymianie dysku twardego.
Szukaj współczynnika błędów- wartość częstości błędów pozycjonowania głowic, informuje o przegrzaniu dysku twardego lub niestabilnej pozycji w koszu, rozwiązanie możliwe w bardziej niezawodnym zamocowaniu dysku twardego.
Licznik godzin włączenia- atrybut wyświetlający liczbę godzin w stanie włączonym.
Liczba ponownych prób kręcenia- liczba powtórzeń kręcenia dysku w przypadku nieudanego poprzedniego.
Ponowne próby kalibracji- ten atrybut wskazuje, ile powtórzeń kalibracji zostało wykonanych, pod warunkiem, że pierwsza próba zakończyła się niepowodzeniem. Wskazuje problemy z mechaniczną częścią dysku twardego.
Liczba cykli zasilania urządzenia- ilość pełnych cykli włączenia/wyłączenia urządzenia.
Licznik wycofań awaryjnych- atrybut parkowania głowy sytuacje awaryjne, utrata mocy lub jej silny spadek, dzieje się to przy słabym styku złącza zasilania lub usterkach płyty HDD.
Liczba cykli ładowania/rozładowywania- ilość cykli doprowadzania głowic do pozycji roboczej.
Temperatura HDA- Temperatura dysku twardego.
Liczba zdarzeń realokacji- licznik operacji remapowania, pokazuje liczbę prób przeniesienia uszkodzonych sektorów do obszaru rezerwowego.
Liczba bieżących oczekujących błędów- licznik sektorów, których odczyt jest utrudniony, sektory te zawierają sektory, których nie udało się odczytać za pierwszym razem, tzw. bad blocki, można to naprawić poprzez przymusowe zapisanie do nich informacji i odczytanie, ta procedura może być wykonywane przez program HDdScan.
Liczba błędów nie do naprawienia- licznik błędów niemożliwych do naprawienia, wskazuje defekty na powierzchni dysku twardego.
Błędy UltraDMA CRC- błędy interfejsu zewnętrznego, które występują, gdy kabel SATA jest złej jakości.
Częstość błędów w wielu strefach- częstotliwość występowania błędów podczas rejestracji danych.
Technologia S.M.A.R.T. Urodziła się w 1995 roku, więc jej wiek jest przyzwoity. Założono, że atrybuty SMART (dla uproszczenia napiszmy skrót bez kropek) generowane przez firmware dysku twardego pozwolą na programową ocenę stanu dysku, a także zapewnią mechanizm przewidywania jego awarii. To ostatnie było dość istotne w tamtych czasach: na przykład żywotność dysków w serwerach oszacowano na półtora roku i dobrze było wiedzieć, kiedy przygotować zamiennik.
Z biegiem czasu wiele się zmieniło: coś umarło, niektóre aspekty rozwinęły się silniej (na przykład kontrola mechaniki dysku). Początkowy zestaw kilkunastu najprostszych atrybutów komplikował się i kilkakrotnie rozrastał, czasem zmieniało się ich znaczenie, wielu producentów wprowadzało własne atrybuty o nie zawsze jasnej funkcjonalności. Pojawiło się wiele programów do analizy SMART (z reguły niskiej jakości, ale z efektywnym interfejsem, a nawet za pieniądze) itp.
Więc nie zaszkodzi opisać współczesność Stan SMART. Zacznijmy krytyczne atrybuty, którego pogorszenie prawie zawsze wskazuje na problemy z napędem. Jest to ich pierwsza rzecz, na którą patrzą serwisanci podczas diagnozowania dysku twardego.
- #01 Współczynnik błędów odczytu surowego— częstotliwość błędów podczas odczytu danych z dysku, których pochodzenie wynika ze sprzętu dysku. W przypadku wszystkich dysków Seagate, Samsung (rodziny F1 i nowsze) oraz Fujitsu 2,5″ jest to liczba wewnętrznych korekt danych wykonanych PRZED wysłaniem do interfejsu; przerażająco ogromne liczby można zignorować.
- #03 Czas rozkręcania to czas, w którym pakiet płyt rozkręca się od spoczynku do prędkości roboczej. Rośnie wraz ze zużyciem mechaniki (zwiększone tarcie w łożysku itp.), a także może wskazywać na słabą jakość mocy (na przykład spadek napięcia podczas rozruchu dysku).
- #05 Liczba przeniesionych sektorów— liczba operacji zmiany przydziału sektorów. Gdy dysk napotka błąd odczytu/zapisu, oznacza sektor jako ponownie mapowany i przesyła dane do obszaru zapasowego. Dlatego na nowoczesnych dyskach twardych nie widać uszkodzonych bloków - wszystkie są ukryte w zmienionych sektorach. Proces ten nazywa się remappingiem, w żargonie - remap. Pole Wartość surowa atrybutu zawiera całkowitą liczbę ponownie przydzielonych sektorów. Im jest większy, tym gorszy stan powierzchni dysku.
- #07 Szukaj wskaźnika błędów to częstotliwość błędów pozycjonowania bloku głowic magnetycznych (BMG). Wzrost tego atrybutu wskazuje na słabą jakość powierzchni lub uszkodzoną mechanikę napędu. Przegrzanie i wibracje zewnętrzne (na przykład z sąsiednich dysków w koszu) również mogą mieć wpływ.
- #10 Liczba ponownych prób rozkręcenia- liczba powtarzających się prób rozkręcenia dysków do prędkości roboczej w przypadku, gdy pierwsza próba się nie powiodła. Jeśli wartość atrybutu rośnie, istnieje duże prawdopodobieństwo problemów z mechaniką.
- #196 Liczba zdarzeń związanych z realokacją— liczba operacji zmiany przydziału. Pole Raw Value atrybutu przechowuje łączną liczbę prób przeniesienia informacji z uszkodzonych sektorów do wolnego obszaru dysku (zwykle nie jest on zbyt duży - kilka tysięcy sektorów). Liczone są zarówno udane, jak i nieudane operacje.
- #197 Aktualna liczba oczekujących sektorów— aktualna liczba niestabilnych sektorów. To przechowuje liczbę sektorów, które są kandydatami do wymiany. Nie zostały jeszcze zidentyfikowane jako złe, ale czytanie z nich pojawia się z trudem (na przykład nie po raz pierwszy). Jeśli „podejrzany” sektor zostanie w przyszłości pomyślnie odczytany, zostanie wykluczony z listy kandydatów. W przypadku powtarzających się błędnych odczytów dysk spróbuje go przywrócić i wykonać remapę.
- #198 Niepoprawna liczba sektorów- ilość sektorów, w trakcie których odczytu są niepoprawne ( fundusze wewnętrzne) błędy. Wzrost tego atrybutu wskazuje na poważne wady powierzchni lub problemy z mechaniką napędu.
- #220 Przesunięcie dysku- przesunięcie pakietu płyt względem osi wrzeciona. Najczęściej występuje z powodu silnego uderzenia lub upuszczenia dysku. Jednostka miary jest nieznana, ale przy silnym wzroście atrybutu dysk nie jest dzierżawcą.
Należy to również wziąć pod uwagę atrybuty informacji, który potrafi wiele opowiedzieć o „historii” płyty.
- #02 wydajność przepustowa- średnia wydajność dysku. Jeśli wartość atrybutu zmniejszy się, prawdopodobnie wystąpią problemy z dyskiem.
- #04 Liczenie start/stop- liczba cykli start-stop wrzeciona. Dyski niektórych producentów (na przykład Seagate) mają licznik aktywacji trybu oszczędzania energii.
- #08 Poszukuj wydajności czasu to średnia wydajność operacji pozycjonowania głowy. Spadek wartości tego atrybutu wskazuje na awarię mechaniki siłownika (przede wszystkim powolne pozycjonowanie).
- #09 Godziny włączenia (POH)- czas spędzony w stanie. Pokazuje całkowity czas dysku, jednostka miary zależy od modelu (nie tylko 1 godzina, ale także 30 minut, a nawet 1 minuta).
- #11 Ponowne próby kalibracji— liczba powtórzeń rekalibracji w przypadku niepowodzenia pierwszej próby. Wzrost tego atrybutu wskazuje na problemy z mechaniką tarczy.
- # 12 Liczba cykli zasilania urządzenia- liczba pełnych cykli włączania i wyłączania dysku.
- # 13 Wskaźnik błędów miękkiego odczytu- częstotliwość występowania błędów „oprogramowania” podczas odczytu danych. Obejmuje to błędy oprogramowanie, sterowniki, system plików, niepoprawny układ dysku - ogólnie prawie wszystko, co nie jest związane ze sprzętem.
- #190 Temperatura przepływu powietrza — temperatura powietrza wewnątrz obudowy dysku twardego. W przypadku dysków Seagate atrybut jest zwracany w normalizacji 100º minus temperatura (dlatego temperatura krytyczna odpowiada wartości 45), podczas gdy modele Western Digital używają normalizacji 125º minus temperatura.
- #191 G- sensbłądwskaźnik to liczba błędów powstałych z powodu obciążeń zewnętrznych. Atrybut przechowuje odczyty wbudowanego akcelerometru, który rejestruje wszystkie wstrząsy, wstrząsy, upadki, a nawet niedokładną instalację dysku w obudowie komputera.
- #192 moc- wyłączonywycofaćliczyć— liczba zarejestrowanych powtórzeń włączenia/wyłączenia zasilania napędu.
- #193 Liczba cykli ładowania/rozładowywania- ilość cykli przemieszczenia ckm na specjalne miejsce parkingowe / do pozycji roboczej.
- #194 Temperatura HDA- temperatura części mechanicznej dysku, potocznie puszki (HDA - Hard Disk Assembly). Informacje pobierane są z wbudowanego czujnika termicznego, którym jest jedna z głowic magnetycznych, najczęściej dolna w banku. Pola bitowe atrybutu rejestrują temperaturę bieżącą, minimalną i maksymalną. Nie wszystkie programy współpracujące ze SMART analizują te pola poprawnie, dlatego ich odczyty należy traktować krytycznie.
- #195 Odzyskano ECC sprzętu to liczba błędów poprawionych przez sprzęt dyskowy. Obejmuje to błędy odczytu, błędy pozycji i błędy transmisji interfejsu zewnętrznego. Na dyskach z interfejsem SATA wartość często się pogarsza, gdy wzrasta częstotliwość magistrali systemowej - SATA jest bardzo wrażliwy na przetaktowywanie.
- #199 UltraDMA (UltraATA)CRCbłądLiczyć— liczba błędów występujących podczas transmisji danych przez interfejs zewnętrzny w trybie UltraDMA (naruszenia integralności pakietów itp.). Wzrost tego atrybutu wskazuje na zły (pomarszczony, skręcony) kabel i złe styki. Podobne błędy pojawiają się również podczas przetaktowywania. Magistrala PCI, awarie zasilania, silne zakłócenia elektromagnetyczne, a czasem z winy kierowcy.
- #200 Wskaźnik błędów zapisu/ Wskaźnik błędów wielostrefowych to częstotliwość występowania błędów w zapisie danych. Pokazuje całkowitą liczbę błędów zapisu na dysku. Im wyższa wartość atrybutu, tym gorszy stan nawierzchni i mechanika napędu.
Jak widać, większość „ciekawych” atrybutów odzwierciedla funkcjonowanie mechanika prowadzić. Technologia SMART naprawdę pozwala przewidzieć awarię dysku w wyniku usterki mechaniczne, co według statystyk stanowi około 60% wszystkich awarii. Przydatny jest również monitoring temperatury: przegrzanie głowic gwałtownie przyspiesza ich degradację, więc przekroczenie niebezpiecznego progu (45-55º w zależności od modelu) jest sygnałem do pilnej poprawy chłodzenia dysków.
Jednocześnie nie należy przeceniać możliwości SMART. Współczesne dyski często „giną” na tle doskonałych atrybutów, co wiąże się z delikatnymi procesami zarządzania defektami w warunkach dużej gęstości zapisu i nie zawsze, delikatnie mówiąc, wysokiej jakości podzespołów (rozbieżność w wydajności głowicy jest dziś zjawiskiem powszechnym ). Ponadto SMART nie jest w stanie przewidzieć konsekwencji takiej „siły wyższej”, jak przepięcie, przegrzanie płytki elektroniki czy uszkodzenie napędu w wyniku uderzenia.
W przypadku prawie wszystkich atrybutów najbardziej interesujące jest pole Raw Value: wartości „surowe” są najbardziej pouczające. Ich normalizacja (stopień zbliżenia się do progu abstrakcyjnego) często nic nie daje, a jedynie dezorientuje sprawę. Dlatego programów opartych na tych wartościach procentowych nie można uznać za całkowicie wiarygodne. Typowym przypadkiem dla nich są fałszywe alarmy. Program informuje, że nowy, niedawno zainstalowany dysk ma zamiar „skleić ze sobą płetwy”. A chodzi o to, że na początku działania niektóre atrybuty SMART szybko się zmieniają, a prymitywna ekstrapolacja prowadzi do prognoz przerażających użytkownika.
Polecam darmowy program HDDScan - poprawnie rozumie wszystkie atrybuty, w tym nowe, poprawnie analizuje wskaźniki temperatury. Raport jest wyświetlany w postaci zgrabnej tabeli xml ze wskazaniem koloru, który można zapisać lub wydrukować.
Dysk SMART WD ma pięć lat. O jego nieuchronnym upadku świadczą niezerowe wartości atrybutów 1 i 200 (dla WD są one szczególnie obciążone), a także fakt, że atrybut 197 ponownie rośnie po remapowaniu. Oznacza to, że wyczerpały się możliwości korygowania defektów.
Niezwykle przydatna dla HDDScan jest możliwość odczytu SMART z dyski zewnętrzne tak powszechne dzisiaj. Prawie żaden inny program tego nie potrafi, ponieważ na drodze danych stoi kontroler, który konwertuje interfejs PATA/SATA na USB lub FireWire. Autor celowo działał w tym kierunku i udało mu się objąć szeroką gamę kontrolerów. Nie zapomniano też o dyskach SCSI, które wciąż są szeroko stosowane w serwerach (mają one specjalne atrybuty - na przykład wyświetlana jest całkowita liczba bajtów zapisanych lub odczytanych przez cały okres eksploatacji dysku).
Funkcjonalność HDDScan w pełni odpowiada potrzebom mechanika. Gdy wstępną diagnostykę przyniesionego dysku zewnętrznego można przeprowadzić bez demontażu obudowy, jest to wygodne, oszczędza czas, a czasem nawet oszczędza gwarancję.

SMART pobrany z dysku SCSI. Tutaj historycznie rozwinęły się zupełnie inne atrybuty.
⇡ Bariery HDD
Mechanika od dawna jest piętą achillesową dysków twardych i to nie tyle ze względu na wrażliwość na wstrząsy i wibracje (to wciąż można skompensować), ile ze względu na powolność. Najszybsze "drganie" przez blok głowic magnetycznych (2-3 ms dla najlepszych modeli serwerów) jest tysiące razy gorsze od szybkości elektroniki.
I naprawdę nie ma tu nic do poprawy. Nie ma gdzie podnieść prędkości obrotowej pakietu dysków, 15000 obr/min to już granica. Japończycy kilka lat temu zbliżyli się do 20 000 obr/min (całkiem żyroskopowa prędkość), ale w końcu odmówili – materiały nie wytrzymują, konstrukcja okazuje się zbyt droga i słabo nadająca się do masowej produkcji. W małych partiach dyski twarde wyjdą złotem, tych nikt nie kupi – to nie są żyroskopy, których nie ma co zastąpić.
Wygląda na to, że uderzyli w barierę. Nie da się obejść mechaniki na krzywym kozie. Jedynym wyjściem jest zwiększenie gęstości zapisu, poprzecznie i wzdłużnie. Gęstość wzdłużna (wzdłuż toru) wpływa na wydajność napędu, tj. na przepływ danych do pozostałych węzłów komputerowych. Ale i tak nawet osiągnięte 100-130 MB/s to za mało dla dzisiejszych komputerów. Na przykład zwykła pamięć o dostępie swobodnym (DRAM) ma rzeczywistą wydajność około 3 GB / s, a pamięć podręczna procesora jest jeszcze większa. Różnica jest rzędu wielkości i ma duży wpływ na ogólną wydajność. Oczywiście nikt nie oczekuje takiej samej wydajności od nieulotnego urządzenia pamięci masowej o pojemności setki razy większej od pamięci DRAM. Ale nawet proste podwojenie byłoby zauważalne dla każdego użytkownika.
Gęstość zapisu poprzecznego to gęstość ścieżek na talerzu, w nowoczesnych dyskach HDD przekracza 10 000 na 1 milimetr. Okazuje się, że sam ślad ma szerokość poniżej 100 nm (swoją drogą nanotechnologia w najczystszej postaci). Pozwala to radykalnie zwiększyć wydajność na powierzchnię, a także przyspiesza pozycjonowanie dzięki wyrafinowanym algorytmom (ich opracowanie wymagałoby kilku prac doktorskich).
W rezultacie pojemność i wydajność dysków twardych znacznie wzrosły w ostatnich latach. Wszystko to stało się możliwe dzięki technologii zapisu prostopadłego, która istnieje od ponad 20 lat, ale dopiero w 2007 roku dojrzała do masowego wdrożenia. Co więcej, pojemność wzrosła wtedy nawet bardziej niż wymagana: pierwsze dyski terabajtowe spotkały się z powolnym odzewem ze strony użytkowników. Ludzie po prostu nie rozumieli, gdzie przystosować takie potwory, zwłaszcza że początkowo były zbudowane na pięciu płytach, były kapryśne, hałaśliwe i gorące (mowa o ówczesnych okrętach flagowych Hitachi).
Potem oczywiście ludzie się zorientowali, torrenty zaczęły działać na pełnych obrotach, a liczba płyt spadła. Jednocześnie gęstość zapisu wzrosła do 500-750 GB na talerz (co oznacza dyski segmentu stacjonarnego o formacie 3,5 cala). Niedługo wejdzie do masowej produkcji terabajt talerzy, co umożliwi produkcję dysków twardych o pojemności do 4 TB (nie można zmieścić więcej niż czterech talerzy w standardowej obudowie o wysokości 26,1 mm; pięciotalerzowe pierworodne Chiczaczowa nie zostały zbytnio rozwinięte).

Trzyterabajtowy dysk WD Caviar Green WD30EZRX, obecnie najbardziej pojemny. Ma konstrukcję czteropłytową i jest produkowany dokładnie przez rok (od 20 października 2010). Zgodnie z oczekiwaniami tańszy wiosną i latem, ale w ostatnich dniach gwałtownie podrożał z powodu powodzi w Tajlandii (tam znajdują się montownie WD, a elementy zablokowały dostawę komponentów)
Niestety, prędkość pozycjonowania wzrosła, delikatnie mówiąc, niewiele, ale dla modeli masowych generalnie utrzymywała się na tym samym poziomie, a nawet spadła na rzecz… ciszy. Marketerzy udowodnili, że konsument głosuje swoim portfelem za gigabajty za dolara, a nie za milisekundy dostępu. Dlatego tanie dyski są powolne w porównaniu z rasowymi odpowiednikami serwerowymi. Powolność dobrze przejawia się w szybkości ładowania systemu operacyjnego, gdy trzeba odczytać z dysku dużą liczbę małych plików rozrzuconych po płytach. Tutaj główną rolę odgrywa prędkość obrotowa wrzeciona i mocny napęd BMG, który umożliwia osiąganie dużych przyspieszeń.
Nawiasem mówiąc, „szybkie” dyski są łatwe do odróżnienia nawet po wadze - są zauważalnie cięższe niż „wolne”. Pełnowymiarowy słoik o pogrubionych ściankach, który przyczynia się do geometrycznej stabilności i tłumienia drgań, szybkoobrotowy silnik wrzeciona, mocne magnesy pozycjonera, dwuwarstwowe wieczko o zwiększonej sztywności – to wszystko dodaje takiemu napędowi dziesiątki i setki gramów. Różnica jest jeszcze większa w modelach serwerowych przy 15 000 obr./min, gdzie zredukowane płyty otoczone są imponującą objętością odlewanego aluminium, a łączna waga „twardego” sięga kilograma.

Wydajna tarcza WD Raptor z prędkością obrotową wrzeciona 10 000 obr./min. Przy pojemności 150 GB waży 740 g (modele masowe o tej samej pojemności - 400-500 g). Zwróć uwagę na wielkość magnesów i grubość ścianki
Wraz z potanieniem półprzewodnikowych dysków SSD, które są używane głównie w systemie operacyjnym, zapotrzebowanie na wysokowydajne dyski twarde zaczęło spadać, a one same stopniowo wyróżniają się w specjalnym segmencie rynku (takim jak na przykład „czarny ” seria z WD). Profesjonalne stacje robocze z aplikacjami intensywnie korzystającymi z zasobów, które mają krytyczne znaczenie dla szybkości dostępu, są wyposażone w takie dyski. Zwykli użytkownicy nie spieszą się z dość drogimi dyskami, preferując wydajność.
Na drugim końcu spektrum znajdują się popularne „zielone” modele z celowo wolnymi obrotem wrzeciona (5400-5900 obr/min zamiast 7200) i wolnym pozycjonowaniem głowicy. Tanie, ciche, chłodne i dość niezawodne dyski te są idealne do przechowywania danych multimedialnych w komputerach domowych, obudowach zewnętrznych i sieciowej pamięci masowej. Na naszych półkach wszystkie te Greeny i LP mają mocno wciśnięte inne linie, więc czasami nie znajdziesz nic innego w małych „punktach”.
⇡ Marnotrawstwo zapisu magnetycznego
Namagnesowanie domen dysku twardego, podobnie jak w połowie XX wieku, zmienia się za pomocą głowicy magnetycznej, której pole wzbudza zmienna wstrząs elektryczny i działa na warstwę magnetyczną przez szczelinę. Również ta technologia wymaga szybkiego obracania płyt, precyzyjnej kontroli położenia głowicy itp. Silnik i pozycjoner dysku twardego, a także sterująca nimi elektronika, zużywają zauważalną moc i kosztują dużo. Ale najważniejsze jest to, że na samo wzbudzenie pola magnetycznego zużywa się dużo energii.
Podczas pracy na komputerze osobistym trudno docenić marnotrawstwo standardowej metody zapisu magnetycznego. Masowo produkowane dyski twarde zużywają mniej niż 10 W nawet podczas aktywnej pracy, co jest prawie niezauważalne na tle innych podzespołów (100 W lub więcej). Ale twoje poglądy zmienią się natychmiast po wizycie w serwerowni jakiegoś dużego banku, a aby uzyskać wrażenia życia, wystarczy podejść do stojaka na dyski superkomputera. W hałasie setek i tysięcy dysków twardych, dmuchających wentylatorów i precyzyjnych klimatyzatorów staje się jasne, ile energii zużywa się w skali globalnej na taką pracę.
Nie bez powodu w przypadku systemów przechowywania danych na pierwszy plan wysuwa się efektywność energetyczna. Google już przenosi swoje centra danych na barki na morzu (tam są prawdziwe offshore!). Okazuje się, że systemy magazynowania chłodzenia z wodą zaburtową radykalnie obniżają koszty eksploatacji, przede wszystkim dzięki oszczędnościom na klimatyzatorach.
⇡ O zasilaniu dysków twardych
Czy zwykła żarówka 220 V będzie działać na 230 V? Oczywiście, że tak będzie. A od 240 V? Także. Pytanie brzmi, jak długo to potrwa? Widać, że mniej lub znacznie mniej - zależy to od konkretnej żarówki. Jej przeznaczeniem jest jasne, ale krótkie życie.
Mniej więcej taka sama sytuacja z dyskami twardymi. Naiwni producenci projektowali je w oparciu o standardowe +5 V i +12 V. Jednak w typowym zasilaczu komputerowym (PSU) stabilizuje się tylko linia 5 V. Do czego to prowadzi?
Przy dużym obciążeniu procesora (a nowoczesne „kamienie” zużywają dużo) i niewystarczającej mocy zasilacza, zapada się linia 5 V, a układ stabilizacji rozwiązuje tę sprawę, podnosząc napięcie do wartości nominalnej. Jednocześnie wzrasta również napięcie 12 V (ze względu na brak stabilizacji na nim). W rezultacie dysk twardy, który jest już niestabilny w nagrzewaniu, działa również przy zwiększonym napięciu, które jest dostarczane do najbardziej nagrzanych elementów - układu sterującego silnikiem (w żargonie mechaników - „skręt”) i głowic napędowych ( tzw. „cewka głosowa”). Konkluzja - zobacz argument o żarówce.


Spalony „skręcenie” na płycie w wyniku zwiększonego napięcia i słabego chłodzenia. Często mikroukład dosłownie się wypala, z efektami pirotechnicznymi i wypaleniem torów na płycie. To jest nie do naprawienia
Stąd porady dotyczące zasilania. Im większa jego moc, tym lepiej (w rozsądnych granicach: rezerwa ponad 30-35% w stosunku do rzeczywistego zużycia obniża sprawność urządzenia, więc ogrzejesz pomieszczenie). Mniej wydajny, ale markowy zasilacz jest lepszy niż mocniejszy, ale pozbawiony korzeni chiński zasilacz. Pamiętaj - nie tylko procesory są podkręcone. Jako pierwsze przybliżenie, 420 „chińskich” watów odpowiada 300 „poprawnym”.
W dobry sposób należy również wziąć pod uwagę wiek zasilacza: po 2-3 latach pracy jego moc rzeczywista wyraźnie spada, a napięcia wyjściowe dryfują. Oczywiście w produktach niskiej jakości, które działają na uczciwym chińskim słowie, procesy starzenia są znacznie bardziej wyraźne. Dobrze, jeśli taki blok sam umiera po cichu i nie odciąga w agonii połowy bloku systemowego!
Maksymalne dopuszczalne napięcie to 12,6 V (+5% wartości nominalnej). Jednak wraz ze wzrostem napięcia wiele dysków wykazuje nieliniowe ostre nagrzewanie wyżej wymienionych węzłów - „skrętów” i „cewek”. Dlatego zalecam ściślejsze monitorowanie zasilacza za pomocą zewnętrznego woltomierza (czujniki na płycie głównej, które mierzą napięcie dla BIOS-u i programów takich jak AIDA, mogą być dość niedokładne).
Najlepiej mierzyć napięcie na złączach Molex i zawsze pod pełnym obciążeniem: procesor jest zajęty obliczeniami zmiennoprzecinkowymi, karta graficzna generuje dynamiczne grafika 3D i defragmentacja dysku. Przy 12,2-12,4 V powinieneś o tym pomyśleć, 12,4-12,6 V - martw się, 12,6-13 V - włącz alarm, a w przypadku 13 V i więcej - oszczędzaj na nowy dysk lub umieść kartę gwarancyjną w widocznym miejscu...

Kondensatory (2200 uF, 25 V) przylutowane do obwodu zasilania HDD (żółty przewód - +12 V, czerwony - +5 V, czarny - masa). W tym przypadku zmniejszają tętnienie napięcia, z którego zasilacz emituje irytujący pisk o wysokiej częstotliwości.
Jeśli napięcie na linii 12 V jest za wysokie, a nie boisz się lutownicy i jesteś w stanie odróżnić tranzystor od diody, to możesz zamienić tę drugą na odcięcie zasilania HDD (przypominam, że 12 Linia V odpowiada żółtemu przewodowi). Dioda będzie pełniła rolę ogranicznika - „dodatkowe” 0,2-0,7 V spadnie na złączu p-n (w zależności od rodzaju diody), a dysk poczuje się lepiej. Tylko dioda musi być wystarczająco mocna, aby wytrzymać prąd rozruchowy 2-3 A.
I bez fanatyzmu: wynikowe napięcie nie powinno spaść poniżej 11,7 V. W przeciwnym razie możliwe jest niestabilne działanie dysku (wielokrotne restarty), a nawet uszkodzenie danych. Niektóre modele (w szczególności Seagate 7200.10 i 7200.11) mogą w ogóle się nie uruchomić.
⇡ Migracja Flash
Pamięci flash NAND pojawiły się znacznie później niż HDD i zaadoptowały szereg jego technologii - przyjmują co najmniej kody ECC. Co więcej, oba kierunki rozwijały się równolegle i stosunkowo niezależnie. Ale ostatnio nastąpił również proces odwrotny: migracja technologii z pamięci flash na dyski twarde. W szczególności mówimy o wyrównaniu zużycia.
Jak wiesz, każdy układ flashowy ma ograniczony zasób według liczby skasowanych zapisów w jednej komórce. W pewnym momencie nie jest już możliwe jego skasowanie i zawiesza się na zawsze z ostatnią zarejestrowaną wartością. Dlatego kontroler zlicza liczbę wpisów na każdej stronie, a jeśli zostanie przekroczona, kopiuje ją w mniej zużyte miejsce. W przyszłości cała praca będzie wykonywana na nowej stronie (zarządza nią tłumacz) i stara strona pozostaje bez zmian i nie jest używany. Ta technologia nazywa się Wear Leveling. Tak więc dyski twarde ulegają zużyciu, ale są mechaniczne i termiczne. Jeśli głowica magnetyczna cały czas wisi nad jedną ścieżką (na przykład ten lub inny plik ciągle się zmienia), to prawdopodobieństwo uszkodzenia ścieżki wzrasta z powodu przypadkowych wstrząsów lub wibracji dysku (na przykład z sąsiednich napędów w koszyk). Głowica może dotknąć płytki i uszkodzić warstwę magnetyczną ze wszystkimi wynikającymi z tego niefortunnymi konsekwencjami. Nawet jeśli nie ma szkodliwego kontaktu, nieruchoma głowica lokalnie nagrzewa się i, choć odwracalnie, ulega degradacji. Zapis do danej lokalizacji jest mniej wiarygodny, a prawdopodobieństwo późniejszego niestabilnego odczytu wzrasta (a przy dzisiejszych ogromnych gęstościach zapisu każde odchylenie parametrów jest fatalne).
Te rozważania są dość oczywiste, a oprogramowanie sprzętowe dysków serwerowych z interfejsem SCSI/SAS (a są one dość gorące) już dawno nauczyło się poruszać głowami w stanie bezczynności, aby się nie przegrzewały. Ale jeszcze lepiej „przenieść” informacje wzdłuż talerza razem z głowicą – w tym przypadku opisane efekty są maksymalnie wytłumione, a niezawodność napędu wzrasta. Tutaj Western Digital wprowadził podobny mechanizm w nowych modelach VelociRaptor. Są to drogie, wysokowydajne napędy z prędkością obrotową wrzeciona 10 000 obr./min i pięcioletnią gwarancją, więc odpowiednie jest tam niwelowanie zużycia.


VelociRaptor na zewnątrz i wewnątrz. Uwagę przyciąga mocny grzejnik. Z kolei talerze mają zmniejszoną średnicę - jest to typowe dla nowoczesnych tarcz o dużej prędkości.
Ponadto cała linia VelociRaptor przeznaczona jest do stosowania w mocno obciążonych systemach, przede wszystkim serwerach, gdzie zapisy na dysku są bardzo intensywne i często do tych samych plików (typowym przykładem są logi transakcji). Masowe dyski „konsumenckie” nie są zagrożone dużymi obciążeniami, nagrzewają się również umiarkowanie, więc takie udoskonalenie raczej się tam nie pojawi. Poczekajmy jednak i zobaczmy.
⇡ Zaawansowany format i jego zastosowanie
Od ponad 20 lat wszystkie dyski twarde mają ten sam rozmiar sektora fizycznego: 512 bajtów. Jest to minimalna ilość zapisu na dysk, która pozwala elastycznie zarządzać dystrybucją miejsca na dysku. Jednak wraz z rozwojem dysków twardych wady tego podejścia stawały się coraz bardziej widoczne - przede wszystkim nieefektywne wykorzystanie pojemności płyty magnetycznej, a także wysokie koszty ogólne przy organizacji strumienia danych.
Dlatego zaczęto produkować dyski o dużej pojemności (terabajty i większe) przy użyciu tej technologii zaawansowany format, który działa na „długich” sektorach fizycznych o wielkości 4096 bajtów. Oznakowanie talerzy magnetycznych dla AF jest bardzo korzystne dla producenta: mniej przerw międzysektorowych, większa pojemność użytkowa toru i całego talerza (a to, wraz z głowicami magnetycznymi, jest najdroższym komponentem HDD). To właśnie Advanced Format umożliwił wprowadzenie na rynek niedrogich dysków twardych, które obecnie cieszą się tak dużą popularnością wśród konsumentów treści audio i wideo. Dyski AF o pojemności 1-3 TB wyposażone są nie tylko w komputery, ale także w wiele dysków zewnętrznych, pamięci sieciowych i odtwarzaczy multimedialnych.

Jeden z pierwszych dysków 3,5″ z technologią Advanced Format, wydany w 2009 roku
Ale nic nie jest rozdawane za darmo, nowe płyty już zaczynają być sprowadzane do naprawy. Wygląda na to, że spadła niezawodność. W końcu awaria pojedynczego dysku lub defekt powierzchni uszkadza teraz 8 razy więcej danych użytkownika niż zwykle. Przy fizycznym sektorze 4 KB i emulacji „krótkich” sektorów 512 bajtów, od 1 do 8 sektorów nie zostanie odczytanych. System operacyjny reaguje na to wyraźnie jako: wypadek, wszystko zniknęło! W rezultacie drobny problem na talerzach przeradza się dla użytkownika w zamarznięcie lub coś jeszcze gorszego.
Nie sądzę, że powinieneś przechowywać system operacyjny, programy użytkowe i bazy danych z dużą ilością małych plików na dyskach AF. Do tej pory ich los to dane multimedialne, które nie są krytyczne dla rezygnacji.
Przede wszystkim polecam zajrzeć na forum HARDW.net. Sekcja „Przechowywanie informacji” jest odwiedzana przez wielu profesjonalnych mechaników i pasjonatów (prawie 40 000 uczestników). Można tam znaleźć odpowiedzi na niemal każdy temat związany z dyskiem twardym, z wyjątkiem najnowszych „nieodkrytych” modeli. Zacznij od podsekcji „Sandbox”: proste (w rozumieniu profesjonalistów) pytania są tam szczegółowo i sensownie odpowiadane, a nie odrzucane, jak w innych miejscach, „zabierz to do mechanika”.
Więcej informacji jednak język angielski, można znaleźć na portalu HDDGURU. Oprócz oprogramowania naprawczego i diagnostycznego oraz artykułów dotyczących konkretnych zagadnień (na przykład, jak zmienić głowice dysków), istnieje międzynarodowe forum dla mechaników, a także ogromne archiwum zasobów HDD (oprogramowanie układowe, dokumentacja, zdjęcia itp.) . Portal wpaja szerokie spojrzenie na sprawy, zainteresuje przygotowanych i zmotywowanych ludzi. W każdym razie na zamkniętych konferencjach mechaników odniesienia do niego są stale.
Odniosę się również do mojego artykułu „Jak przedłużyć żywotność dysków twardych” w trzech częściach. Podaje wstępne informacje na temat obsługi dysków twardych i chociaż został napisany ponad trzy lata temu, nie jest zbyt przestarzały - dyski nie zmieniły się zasadniczo w tym czasie, z wyjątkiem tego, że stały się jeszcze mniej niezawodne ze względu na duże oszczędności. Producenci, uwikłani w światowy kryzys, ograniczyli koszty we wszystkich obszarach, co spowodowało szereg głośnych awarii w latach 2008-2009. Jeden z nich zostanie omówiony w kontynuacji tego materiału, który ukaże się w niedalekiej przyszłości.
Kolejność działań w obecności S.M.A.R.T. Błędy dysku twardego lub SSD. Jak naprawić dysk i odzyskać utracone dane. Po uruchomieniu komputera lub laptopa pojawia się S.M.A.R.T. błąd dysku twardego lub ssd? Po tym błędzie komputer nie działa tak jak poprzednio, a obawiasz się o bezpieczeństwo swoich danych? Nie wiesz, jak naprawić błąd?
Rzeczywiste dla systemu operacyjnego: Windows 10, Windows 8.1, Windows Server 2012, Windows 8, Windows Serwer domowy 2011, Windows 7 (siedem), Windows Small Business Server, Windows Server 2008, Strona główna Windows Serwer, Windows Vista, Windows XP, Windows 2000, Windows NT.
Co zrobić z błędem SMART?
Krok 1: Przestań używać uszkodzonego dysku twardego
Otrzymanie z systemu komunikatu diagnostycznego o błędzie nie oznacza, że dysk już uległ awarii. Ale w przypadku S.M.A.R.T. błędy, musisz zrozumieć, że dysk jest już w trakcie awarii. Całkowita awaria może nastąpić zarówno w ciągu kilku minut, jak i po miesiącu lub roku. Ale w każdym razie oznacza to, że nie możesz już ufać swoim danym na takim dysku.
Musisz zadbać o bezpieczeństwo swoich danych, stworzyć kopię zapasową lub przenieść pliki na inny nośnik. Wraz z bezpieczeństwem swoich danych musisz podjąć kroki w celu wymiany dysku twardego. Dysk twardy, na którym S.M.A.R.T. błędy nie powinny być wykorzystywane - nawet jeśli nie zawiedzie całkowicie, może częściowo uszkodzić Twoje dane.
Oczywiście dysk twardy może zawieść bez S.M.A.R.T. Ale ta technologia daje przewagę ostrzegania, że dysk niedługo ulegnie awarii.
Krok 2: Odzyskaj usunięte dane na dysku
W przypadku błędu SMART odzyskiwanie danych z dysku nie zawsze jest wymagane. W przypadku błędu zaleca się natychmiastowe utworzenie kopii ważnych danych, ponieważ dysk może w każdej chwili ulec awarii. Ale są błędy, w których nie można już skopiować danych. W takim przypadku możesz skorzystać z programu do odzyskiwania dane trudne dysk - Odzyskiwanie partycji hetmańskich.

Dla tego:
- Pobierz program, zainstaluj i uruchom.
- Domyślnie użytkownik zostanie poproszony o użycie Kreator odzyskiwania plików. Naciśnięcie przycisku "Dalej", program poprosi o wybranie dysku, z którego chcesz odzyskać pliki.
- Kliknij dwukrotnie uszkodzony dysk i wybierz żądany typ analizy. Wybierać „Pełna analiza” i poczekaj na zakończenie procesu skanowania dysku.
- Po zakończeniu procesu skanowania otrzymasz pliki do przywrócenia. Wybierz żądane pliki i kliknij przycisk "Przywróć".
- Wybierz jeden z sugerowanych sposobów zapisywania plików. Nie zapisuj odzyskanych plików na dysk z błędem.
Krok 3: Przeskanuj dysk w poszukiwaniu uszkodzonych sektorów
Uruchom skanowanie wszystkich partycji dysku twardego i spróbuj naprawić znalezione błędy.

Aby to zrobić, otwórz folder "Ten komputer" i kliknij kliknij prawym przyciskiem myszy mysz na dysku z błędem SMART. Wybierz Nieruchomości / Usługa / Zweryfikować W rozdziale Sprawdzanie dysku pod kątem błędów.
W wyniku skanowania można poprawić błędy znalezione na dysku.
Krok 4: Zmniejsz temperaturę dysku
Czasami przyczyną błędu „S M A R T” może być przekroczenie maksymalnej dopuszczalnej temperatury pracy dysku. Ten błąd można naprawić, poprawiając wentylację komputera. Najpierw sprawdź, czy Twój komputer jest wyposażony w odpowiednią wentylację i czy wszystkie wentylatory działają prawidłowo.
Jeśli znajdziesz i naprawisz problem z wentylacją, po którym temperatura dysku spadnie do normalnego poziomu, błąd SMART może już nie występować.
Krok 5:
Otwórz folder "Ten komputer" i kliknij prawym przyciskiem myszy dysk z błędem. Wybierz Nieruchomości / Usługa / Optymalizować W rozdziale Optymalizacja i defragmentacja dysku.

Wybierz dysk, który chcesz zoptymalizować i kliknij Optymalizować.
Notatka. W systemie Windows 10 można skonfigurować automatyczne uruchamianie defragmentacji i optymalizacji dysku.
Krok 6: Kup nowy dysk twardy
Jeśli napotkasz błąd dysku twardego SMART, zakup nowego dysku jest tylko kwestią czasu. Potrzebny dysk twardy zależy od stylu komputera i celu, w jakim jest używany.
Na co zwrócić uwagę przy zakupie nowego dysku:
- Typ dysku: HDD, SSD lub SSHD. Każdy typ ma swoje wady i zalety, które nie są krytyczne dla niektórych użytkowników, a dla innych są bardzo ważne. Najważniejsze z nich to szybkość odczytu i zapisu informacji, głośność oraz odporność na wielokrotne przepisywanie.
- Rozmiar. Istnieją dwa główne typy dysków: 3,5" i 2,5". Rozmiar dysku jest określany zgodnie z miejscem instalacji konkretnego komputera lub laptopa.
- Interfejs. Główne interfejsy dysków twardych:
- SATA
- IDE, ATAPI, ATA;
- SCSI
- Dysk zewnętrzny (USB, FireWire itp.).
- Specyfikacje i wydajność:
- Pojemność;
- Szybkość odczytu i zapisu;
- Rozmiar bufora pamięci lub pamięci podręcznej;
- Czas odpowiedzi;
- Tolerancja błędów.
- MĄDRY.. Obecność tej technologii na dysku pomoże zidentyfikować możliwe błędy w jego działaniu i zapobiec utracie danych w czasie.
- Ekwipunek. Pozycja ta obejmuje ewentualną obecność kabli interfejsu lub zasilania, a także gwarancję i serwis.
Jak zresetować błąd SMART?
Błędy SMART można łatwo zresetować w BIOS-ie (lub UEFI). Ale twórcy wszystkich systemów operacyjnych kategorycznie nie zalecają tego. Jeśli dane na dysku twardym nie mają dla Ciebie żadnej wartości, wyjście błędów SMART można wyłączyć.
Aby to zrobić, wykonaj następujące czynności:
- Zrestartuj swój komputer i naciskając kombinację klawiszy wskazaną na ekranie startowym (zazwyczaj są one różne dla różnych producentów „F2” lub Del) przejdź do BIOS (lub UEFI).
- Iść do: zaawansowane > Ustawienia SMART > Samotest SMART. Ustalić wartość Wyłączone.
Notatka: lokalizacja wyłączenia funkcji jest przybliżona, ponieważ w zależności od wersji systemu BIOS lub UEFI lokalizacja tego ustawienia może się nieznacznie różnić.
Czy naprawa HDD jest tego warta?
Ważne jest, aby zrozumieć, że każdy ze sposobów wyeliminowania błędów SMART jest samooszukiwaniem. Nie można całkowicie wyeliminować przyczyny błędu, ponieważ główną przyczyną jego wystąpienia jest często fizyczne zużycie mechanizmu dysku twardego.
Aby wyeliminować lub wymienić nieprawidłowo działające elementy dysku twardego, możesz skontaktować się z centrum serwisowym specjalnego laboratorium do pracy z dyskami twardymi.
Ale koszt pracy w tym przypadku będzie wyższy niż koszt nowego urządzenia. Dlatego naprawa ma sens tylko wtedy, gdy konieczne jest przywrócenie danych z już niedziałającego dysku.
Błąd SMART dla dysku SSD
Nawet jeśli nie masz żadnych skarg Działanie SSD dysk, jego wydajność stopniowo spada. Powodem tego jest fakt, że komórki pamięci Dysk SSD mieć Limitowana ilość przepisać cykle. Funkcja odporności na zużycie minimalizuje ten efekt, ale nie eliminuje go całkowicie.
Dyski SSD mają swoje własne specyficzne atrybuty SMART, które sygnalizują stan komórek pamięci dysku. Na przykład „209 Pozostała żywotność dysku”, „Pozostało 231 żywotności dysku SSD” itp. Błędy te mogą wystąpić, gdy komórki są zdegradowane, co oznacza, że przechowywane w nich informacje mogą zostać uszkodzone lub utracone.
Komórki dysku SSD w przypadku awarii nie są przywracane i nie można ich wymienić.
Czy błąd SMART został naprawiony? Zostaw opinię i zadawaj pytania w komentarzach.
Wszystkie nowoczesne dyski twarde dyski magnetyczne wspierać technologię samotestowania, analizy stanu i gromadzenia danych statystycznych dotyczących pogorszenia się ich własnych cech MĄDRY. (Technika analizy i raportowania samooceny). Podstawy S.M.A.R.T. zostały opracowane w 1995 roku wspólnym wysiłkiem wiodących producentów dysków twardych. W procesie ulepszania wyposażenia napędów dopracowano również możliwości technologii, a po standardzie SMART pojawił się SMART II, potem SMART III, który oczywiście też nie będzie ostatni.
Dysk twardy w trakcie swojej pracy stale monitoruje pewne parametry swojego stanu i odzwierciedla je w specjalnych charakterystykach - atrybuty(Atrybut), które są przechowywane z reguły w specjalnie wydzielonej części powierzchni dysku, dostępnej tylko dla wewnętrznego oprogramowania dysku - obszar usług. Dane atrybutów można odczytać za pomocą specjalnego oprogramowania.
Atrybuty identyfikowane są po numerze, z których większość jest interpretowana w ten sam sposób przez akumulatory różne modele. Niektóre atrybuty mogą być specyficzne dla producenta sprzętu i mogą być obsługiwane tylko przez niektóre modele dysków.
Atrybuty składają się z kilku pól, z których każde ma określone znaczenie. Zazwyczaj S.M.A.R.T. podać dekodowanie atrybutów w postaci:
- atrybut- nazwa atrybutu
- ID- identyfikator atrybutu
- wartość- aktualna wartość atrybutu
- Próg- minimalna wartość progowa atrybutu
- Najgorszy- bardzo niska wartość atrybuty przez cały czas jazdy
- Surowe- wartość bezwzględna atrybutu
- rodzaj(opcjonalne) - typ atrybutu - charakteryzuje wydajność (PR - Performance-related), charakteryzuje awarie (ER - Error rate), licznik zdarzeń (EC - Events count), zdefiniowane przez producenta lub nieużywane (SP - Self-preserve);
Aby przeanalizować stan dysku, być może najważniejszą wartością atrybutu jest wartość- numer warunkowy (zwykle od 0 do 100 lub do 253) ustalony przez producenta. Wartość Wartość jest początkowo ustawiona na maksimum podczas produkcji napędu i zmniejsza się wraz z degradacją napędu.
Dla każdego atrybutu istnieje wartość progowa, do której producent gwarantuje jego działanie - pole Próg. Jeśli wartość Value zbliża się lub staje się mniejsza niż wartość Threshold, nadszedł czas, aby zmienić dysk. Lista atrybutów i ich wartości nie są ściśle ustandaryzowane i są określane przez producenta napędu, ale najważniejsze z nich są interpretowane w ten sam sposób.
Na przykład atrybut o identyfikatorze 5 ( liczba przeniesionych sektorów) będzie charakteryzować liczbę sektorów dyskowych odrzuconych i przeniesionych z obszaru zapasowego, zarówno dla urządzeń produkowanych przez Seagate, jak i Western Digital, Samsung, Maxtor.
Dysk twardy nie ma możliwości, z własnej inicjatywy, przesyłania danych SMART do konsumenta. Ich odczyt odbywa się za pomocą specjalnego oprogramowania.
W ustawieniach najnowocześniejszych BIOS płyty głównej płyt, istnieje pozycja, która pozwala wyłączyć lub włączyć odczyt i analizę atrybutów SMART w trakcie wykonywania testów sprzętu przed wykonaniem rozruchu systemu. Włączenie tej opcji umożliwia podprogramowi testu sprzętu BIOS odczytywanie wartości krytycznych atrybutów i ostrzeganie o tym użytkownika w przypadku przekroczenia progu. Z reguły bez większych szczegółów:
Główny główny dysk twardy: stan S.M.A.R.T ZŁY!, Kopia zapasowa i wymiana.
Wykonywanie procedury BIOS zostaje wstrzymane, aby przyciągnąć uwagę:
Dzięki temu bez instalowania lub uruchamiania dodatkowego oprogramowania można na czas określić krytyczny stan dysku (gdy ta opcja jest włączona) za pomocą podstawowego systemu wejścia/wyjścia (BIOS).
Analiza danych S.M.A.R.T. twardy dysk
Aby uzyskać dane SMART w środowisku systemu operacyjnego, można użyć specjalnych programów, w szczególności prawie wszystkich narzędzi do testowania sprzętu dysku twardego.
Jednym z najpopularniejszych programów do testowania dysków twardych jest Wiktoria Siergiej Kazański. Na stronie autora znajdziesz Ostatnia wersja programy, a także przydatna informacja, w tym szczegółowy opis pracy z Victorią.
Program Victoria ma dwie odmiany - do pracy w środowisku DOS i do pracy w środowisku Windows. Wersja DOS może współpracować bezpośrednio z kontrolerem dysku twardego i jest znacznie wydajniejsza niż wersja dla systemu Windows. Przeznaczenie, główne funkcje i sposób korzystania z programu można było wcześniej znaleźć na stronie autora, ale od jakiegoś czasu strona została porzucona i nie ma na niej żadnych informacji.
Program jest prosty w obsłudze i pozwala ocenić stan techniczny dysku, przeprowadzić jego testy oraz niektóre ustawienia - poziom hałasu, wydajność, głośność fizyczną. Tryby testowania powierzchni dysku pozwalają na przymusowe pozbycie się uszkodzonych sektorów za pomocą Zmień mapę kilka rodzajów. Menu testowe jest wywoływane przez naciśnięcie klawisza F4 (SKANOWANIE). Użytkownik ma możliwość ustawienia obszar testowy:
- Rozpocznij LBA:0- początek obszaru (domyślnie - 0)
- Koniec LBA: 14680064- koniec obszaru (domyślnie - numer ostatniego bloku dysku)
Tryb testowy:
- Odczyt liniowy- odczyt sekwencyjny od bloku początkowego do bloku końcowego;
- Odczyt losowy- numer odczytanego bloku jest generowany losowo;
- MOTYL czytanie- bloki są odczytywane począwszy od numerów granic (początek i koniec) do środka obszaru testowego. Zmiana trybu odbywa się poprzez naciśnięcie spacji.
Tryb obsługi błędów. Ta pozycja pozwala ukryć wadliwe bloki za pomocą ponownego mapowania z obszaru zapasowego. Wybór trybu odbywa się za pomocą klawisza „spacja”. Wybrana metoda pracy z defektami jest wyświetlana po prawej stronie górny róg ekran, pod zegarem, a także w dolna linia w momencie uruchomienia testu. Możesz zmienić tryb podczas i podczas skanowania.
- Ignoruj złe bloki- program nie wykona żadnych działań po wykryciu błędu.
- BB = PRZYWRÓĆ DANE- program spróbuje odzyskać dane z uszkodzonych sektorów.
- BB = Klasyczna REMAP- napisz do uszkodzonego sektora, aby wywołać procedurę ponownego mapowania.
- BB = Zaawansowana REMAP- ulepszony algorytm ukrywania złych bloków. Jest używany, gdy klasyczna remapa nie pomaga. Program wykonuje specjalną sekwencję operacji w celu utworzenia znaku kandydującego do przemapowania (atrybut 197) dla złego bloku. Następnie wykonywany jest 10-krotny zapis, przetwarzany przez oprogramowanie układowe dysku jako normalne przetwarzanie kandydatów do remapowania - jeśli wystąpi błąd, wykonywana jest remapowanie, jeśli nie ma błędu, blok jest uważany za normalny i usuwany z kandydatów do remapowania. Ten tryb pozwala ukryć złe bloki bez utraty danych użytkownika. Oczywiście tylko w przypadkach, gdy napęd jest sprawny technicznie i ma wolne miejsce w obszarze zapasowym do zmiany przydziału.
- BB = Remap Fujitsu- wykonanie określonych algorytmów w oparciu o nieudokumentowane cechy niektórych modeli napędów Fujitsu
- BB = Usuń 256 sek.- po wykryciu złego sektora nadpisywany jest blok 256 sektorów. Dane użytkownika nie są zapisywane.
W trakcie pracy z programem możesz wywołać pomoc kontekstową, naciskając klawisz F1
Wersja Wiktoria Okna ma skromniejsze opcje konfiguracji napędu i wyboru trybów testowych, a obecnie nie ma obsługi języka rosyjskiego, jednak jest łatwiejszy w obsłudze, a dostępne możliwości w zupełności wystarczają do odczytania tabeli SMART i oceny stanu technicznego napędu.
Program nie wymaga instalacji, wystarczy pobrać najnowszą wersję z linku Victoria v4.47 z naszej strony.
Program musi być uruchomiony na koncie z uprawnieniami administratora. W środowisku Windows 7 / 8 należy użyć menu kontekstowego „Uruchom jako administrator”.
Aby przeanalizować stan atrybutów SMART, wybierz tryb pracy za pomocą oprogramowania Interfejs Windows- włącz przycisk API w prawym górnym rogu okna głównego. Następnie wybierz dysk do sprawdzenia - kliknij przycisk standard w menu głównym programu i podświetl żądany dysk w polu listy za pomocą myszy.
W oknie informacyjnym zostanie wyświetlony paszport dysku — model, wersja oprogramowania układowego, numer seryjny, rozmiar itp. Aby odebrać dane SMART, wybierz pozycję menu MĄDRY i kliknij przycisk „Uzyskaj SMART”. Wynik zostanie wyświetlony w oknie informacyjnym programu.
Krótki opis atrybutów (w nawiasie podano wartość szesnastkową liczby):
- 001(1) Współczynnik błędów odczytu surowego- wartość bezwzględna błędów odczytu. Istnieją pewne różnice w kształtowaniu wartości tego atrybutu przez różnych producentów. Z praktyki mogę powiedzieć, że dyski Seagate mogą mieć gigantyczną wartość RAW tego atrybutu, będąc naprawdę w dobrym stanie, a dyski Western Digital mogą mieć ją zero, mając krytyczne wskaźniki dla innych cech. Niektóre modele mogą w ogóle nie obsługiwać tego atrybutu.
- 003 (3) Czas rozkręcania- Średni czas rozbiegu wrzeciona tarczowego od 0 obr./min do prędkości roboczej.
- 004 (4) Licznik start/stop- Liczba cykli start/stop wrzeciona.
- 005 (5) Liczba przeniesionych sektorów- Liczba przeniesionych sektorów. Współczesne dyski mają dość dużą (tysiące sektorów) rezerwę powierzchni dysku do wykorzystania w przypadku pogorszenia wydajności sektorów ze strefy głównej. Jeśli napęd wykryje problemy z zapisem/odczytem dowolnego sektora, automatycznie przenosi swoje dane do obszaru zapasowego, a sektor ten zostaje oznaczony jako „przeniesiony”. Często ten proces jest nazywany „ponownym mapowaniem” lub „automatycznym przypisywaniem defektów”, jest wykonywany przez oprogramowanie układowe dysku i niewidoczny dla użytkownika (systemu operacyjnego). Pole Wartość surowa zawiera całkowitą liczbę przemapowanych sektorów. Nawet niekrytyczna, ale wysoka wartość tego pola może prowadzić do obniżenia szybkości wymiany danych, ponieważ napęd wykonuje dodatkową operację instalowania głowic na torach obszaru zapasowego, zwykle znajdujących się na końcu dysku.
- 007 (7) Szukaj stopy błędów- Częstotliwość występowania błędów w pozycjonowaniu bloku głowic magnetycznych (BMG). Napęd kontroluje prawidłowy montaż głowic na wymaganym torze nawierzchni. W przypadku, gdy instalacja została wykonana nieprawidłowo, błąd jest naprawiany i operacja jest powtarzana. W przypadku tego napędu przyczyną dużej liczby błędów było przegrzanie.
- 008(8) Poszukuj wydajności czasu- średnia prędkość pozycjonowania głowic magnetycznych. W przypadku spadku wartości atrybutu (spowolnienie pozycjonowania) istnieje duże prawdopodobieństwo wystąpienia problemów z częścią mechaniczną siłownika.
- 009 (9) Godziny włączenia zasilania- Liczba godzin. Osiągnięcie wartości granicznej tego atrybutu oznacza, że napęd osiągnął określony przez producenta czas między awariami (MTBF - Mean Time Between Failures).
- 010 (0A) Liczba ponownych prób wirowania- Liczba ponownych prób uruchomienia wrzeciona. Po włączeniu zasilania napęd rozkręca dyski i kontroluje przez pewien czas osiągnięcie roboczej prędkości obrotowej dla tego urządzenia (np. 5400, 7200, 10000 obr/min). W przypadku niepowodzenia - licznik powtórzeń jest zwiększany i próba startu jest powtarzana.
- 011(0B) Ponowne próby kalibracji- liczba prób rekalibracji, w przypadku gdy pierwsza próba nie powiodła się. Jeśli wartość atrybutu wzrasta, istnieje duże prawdopodobieństwo wystąpienia problemów z mechaniczną częścią napędu. Dodatkowo wzrost wartości bezwzględnej tego atrybutu może być spowodowany faktem, że procedura rekalibracji jest wykorzystywana przez wewnętrzne oprogramowanie napędu do korygowania innych rodzajów błędów.
- 012 (0C) Liczba cykli zasilania urządzenia- Liczba cykli włączania/wyłączania dysku.
- 184 (B8) Błąd od końca do końca- Ten atrybut - część technologii HP SMART IV - oznacza, że po przesłaniu danych przez pamięć buforową parzystość danych między kontrolerem komputera a dyskiem twardym nie jest zgodna.
- 187 (BB) Zgłoszony błąd nie do naprawienia— Określa liczbę błędów, które nie zostały naprawione przez oprogramowanie układowe dysku.
- 188 (BC) Limit czasu polecenia Liczba operacji przerwanych z powodu przekroczenia limitu czasu HDD. Zwykle wartość tego atrybutu powinna wynosić zero, a jeśli wartość jest znacznie wyższa od zera, najprawdopodobniej wystąpią poważne problemy z zasilaniem lub utlenienie pinów kabla interfejsu.
- 189 (BD) Zapisy w trybie High Fly- Jeżeli wysokość lotu głowy nad powierzchnią magnetyczną, nawet na krótko, przekroczy optimum, to dane przez nią zarejestrowane w przyszłości mogą nie zostać odczytane. Nowoczesne napędy wykorzystują specjalnie opracowaną technologię kontrolowania wysokości głowic, dzięki czemu możliwe jest nie zapisywanie danych na nieoptymalnej wysokości. Do licznika tego atrybutu dodawany jest jeden, a wpis następuje po ustawieniu normalnej wysokości lotu. Podwyższona wartość tego atrybutu może być spowodowana zewnętrznymi wstrząsami lub wibracjami, nienormalnymi temperaturami, pogorszeniem się powierzchni magnetycznej lub głowicy.
- 190 (BE) Temperatura przepływu powietrza- temperatura środowisko blok głowic magnetycznych. W większości modeli ten atrybut jest nieobecny i używany jest atrybut 194.
- 191 (BF) Wskaźnik błędu G-sense- ilość błędów wynikających z obciążeń udarowych. Atrybut przechowuje odczyty wbudowanego akcelerometru, który rejestruje wszystkie wstrząsy, wstrząsy, upadki, a nawet niedokładną instalację dysku w obudowie komputera. Zwykle dość dokładnie charakteryzuje warunki pracy laptopów – duża wartość atrybutu wskazuje na gwałtowne wstrząsy i upadki podczas pracy urządzenia.
- 192 (C0) Licznik wycofań przy wyłączonym zasilaniu- ilość cykli wyłączeń lub awarii awaryjnych (włączenie/wyłączenie zasilania napędu).
- 193 (C1) Cykl załadunku/rozładunku- ilość cykli przesunięcia bloku głowic magnetycznych do strefy parkowania.
- 194 (C2) Temperatura HDA- temperatura samego napędu (HDA - Hard Disk Assembly). Atrybut ten przechowuje odczyty wbudowanego czujnika temperatury, którym zwykle jest jedna z głowic magnetycznych (zwykle dolna). Dane zarejestrowane w polach atrybutów wyświetlają aktualną, minimalną i maksymalną temperaturę. W polu Najgorsza wyświetlana jest najgorsza temperatura osiągnięta podczas pracy napędu (można ustawić fakt przegrzania i jego stopień), wartość surowa - aktualna temperatura. Niektóre modele dysków mogą obsługiwać atrybut 205 (CD) Thermal asperity rate (TAR), który ustala liczbę niebezpiecznych spadków temperatury.
- 195 (C3) Odzyskano ECC sprzętu- charakteryzuje liczbę błędów odczytu skorygowanych przez sprzęt przemiennika za pomocą kodu korekcji błędów. Błędy takie nie wymagają ponownego odczytu sektora i nie prowadzą do utraty kursu wymiany danych, jednak duża ich liczba wskazuje na pogorszenie parametrów ścieżki odczytu.
- 196 (C4) Liczba zdarzeń realokacji- Liczba zdarzeń remapowania złych sektorów. W terenie Wartość surowa Ten atrybut przechowuje całkowitą liczbę prób przesłania danych z niestabilnych sektorów do obszaru zapasowego. Liczone są zarówno udane, jak i nieudane próby.
- 197 (C5) Aktualna liczba oczekujących sektorów- Aktualna liczba niestabilnych sektorów. pole wartości surowej Ten atrybut pokazuje całkowitą liczbę sektorów, które dysk obecnie uważa za kandydatów do ponownego mapowania. Jeżeli w przyszłości któryś z tych sektorów zostanie pomyślnie odczytany, zostaje on wykluczony z listy kandydatów. Jeśli odczytowi sektora towarzyszą błędy, dysk spróbuje odzyskać dane i przenieść je do obszaru kopii zapasowej oraz oznaczyć sektor jako ponownie zmapowany.
- 198 (C6) Liczba niepoprawnych sektorów- Licznik błędów nie do naprawienia. Są to błędy, które nie zostały poprawione przez wewnętrzne poprawki sprzętowe napędu. Może to być spowodowane awarią poszczególnych elementów lub brakiem wolnych sektorów w zapasowym obszarze dysku, gdy konieczne stało się ponowne mapowanie.
- 199 (C7) UltraDMA CRC Liczba błędów- Licznik błędów, które wystąpiły podczas przesyłania danych w trybie UltraDMA. Sprzęt sterujący transferem drive-to-RAM wykrył błąd sumy kontrolnej. Często ten rodzaj błędu jest związany nie tyle ze sprzętem napędu, co z wadliwym kablem interfejsu, niestabilnym zasilaniem, przetaktowaniem częstotliwości magistrali PCI, przegrzaniem chipsetu płyty głównej itp.
- 200 (C8) Współczynnik błędów zapisu (wielostrefowy współczynnik błędów)- Charakteryzuje obecność błędów podczas rejestrowania danych. Może być spowodowane pogorszeniem się powierzchni, głowic lub charakterystyki ścieżki danych. Im niższa wartość, tym bardziej niebezpieczne jest korzystanie z takiego dysku.
- 220 (DC) Przesunięcie dysku- przemieszczenie bloku tarcz względem pionowej osi wrzeciona. Występuje głównie na skutek silnego uderzenia lub upadku napędu i z reguły jest sygnałem do jego wymiany.
- 228 (E4) Cykl wycofywania przy wyłączonym zasilaniu- Liczba automatycznych parkowań głowic magnetycznych po wyłączeniu zasilania.
Nowoczesne dyski wspierają nie tylko tworzenie atrybutów S.M.A.R.T, ale także prowadzą dodatkowe logi statystyk, a także obsługują protokół SCT(SMART Command Transport), który odczytuje dane dziennika. Dziennik statystyk urządzenia to dziennik SMART tylko do odczytu, wysyłany przez napęd po otrzymaniu poleceń READ LOG EXT, READ LOG DMA EXT lub SMART READ LOG. Dzienniki wyświetlają informacje o wykonaniu wbudowanych testów S.M.A.R.T (samotestów), statystykach błędów, numerach złych bloków LBA itp.