기준: 데모 사용 옵션 2015년 정보학, http://wiki.vspu.ru/
A, B, C, D 및 D 문자로 구성된 특정 시퀀스를 인코딩하려면 바이너리 코드, 결과 이진 시퀀스를 고유하게 디코딩할 수 있습니다. 코드는 다음과 같습니다. A - 0; B - 100; B - 1010; G - 111; D - 110. 코드가 여전히 명확하게 디코딩될 수 있도록 문자 중 하나에 대한 코드 단어의 길이를 줄여야 합니다. 나머지 문자의 코드는 변경되지 않아야 합니다. 어떻게 할 수 있습니까?
우리에게 필요한 것이 무엇인지 이해하기 위해 이 과제의 각 단어를 다루어 보겠습니다. 코딩, 시퀀스 - 이것은 우리 모두에게 친숙하고 잘 이해되는 단어이며 그 의미를 완벽하게 이해합니다. 그리고 이제 글자를 나열하고 나면 익숙하지 않은 NON-UNIFORM 바이너리 코드라는 문구에 직면하게 됩니다. 고르지 않은 바이너리 인코딩- 일부 기본 알파벳의 문자를 이진 알파벳(즉, 0과 1)의 문자 조합으로 인코딩하는 인코딩, 코드의 길이 및 이에 따라 개별 코드의 전송 기간이 다를 수 있습니다. 이진 코딩의 아이디어는 허프만 코드의 기초이며, 시퀀스에서 가장 많이 발생하는 문자는 매우 작은 코드를 수신하고, 가장 적게 발생하는 문자는 반대로 매우 긴 코드를 수신하여 정보의 양을 줄입니다.
현재 형식에서 각 문자에 대해 1바이트가 사용되는 문자열 "tor here ter"가 있다고 가정합니다. 이것은 전체 라인이 11*8 = 88비트 메모리를 차지함을 의미합니다. 인코딩 후 문자열은 27비트를 사용합니다.

빈도에 따라 "thor here ter" 문자열의 각 문자에 대한 코드를 얻으려면 이 트리의 각 잎에 문자가 포함되도록 트리(그래프)를 만들어야 합니다. 트리는 잎에서 루트까지 만들어집니다. 빈도가 낮은 문자는 높은 빈도를 가진 문자보다 루트에서 더 멀리 떨어져 있다는 의미입니다.
트리를 구축하기 위해 약간 수정된 우선 순위 대기열을 사용합니다. 우선 순위가 가장 낮은 요소가 가장 먼저 선택되고 가장 높은 것이 아닌 우선 순위 대기열이 사용됩니다. 이것은 잎에서 뿌리까지 나무를 만드는 데 필요합니다.
그래서 우리는 문자의 빈도를 계산합니다. TR 갭 O U E
| 상징 | 빈도 |
| 티 | 4 |
| 아르 자형 | 2 |
| " " | 2 |
| ~에 | 1 |
| 영형 | 1 |
| 이자형 | 1 |
빈도를 계산한 후 각 기호에 대해 이진 트리 노드를 만들고 빈도를 우선 순위로 사용하여 대기열에 추가합니다.
이제 대기열에서 처음 두 요소를 가져와 연결하여 둘 다 자식이 될 새 트리 노드를 만들고 새 노드의 우선 순위는 우선 순위의 합과 같습니다. 그런 다음 결과로 생성된 새 노드를 다시 대기열에 추가합니다.

우리는 동일한 단계를 반복하고 결과적으로 다음을 얻습니다.


가지를 하나의 트리에 연결하면 기호에 대해 다음 코드를 얻을 수 있습니다.

T - 00; P-10; 공간 -01; O - 1110; U - 110; 전자 - 1111자세한 내용을 읽을 수 있습니다
작업 1 사용:
문자 A, B, C, D 및 E로 구성된 특정 시퀀스를 인코딩하기 위해 비균일 바이너리 코드가 사용되어 결과 바이너리 시퀀스를 고유하게 디코딩할 수 있습니다. 코드는 다음과 같습니다. A - 0; B - 100; B - 1010; G - 111; D - 110. 코드가 여전히 명확하게 디코딩될 수 있도록 문자 중 하나에 대한 코드 단어의 길이를 줄여야 합니다. 나머지 문자의 코드는 변경되지 않아야 합니다. 어떻게 할 수 있습니까?
수업은 컴퓨터 과학 시험의 다섯 번째 과제를 해결하는 방법에 전념합니다.
5번 주제는 기본 난이도의 작업으로 특징지어지며, 실행시간은 약 2분, 최고점수는 1점
- 코딩- 정보의 저장, 전송 및 처리에 편리한 형태로 정보를 표시하는 것입니다. 정보를 그러한 표현으로 변환하는 규칙을 암호.
- 코딩이 일어난다 제복그리고 고르지 않은:
- 균일한 코딩으로 모든 문자는 동일한 길이의 코드에 해당합니다.
- 고르지 못한 코딩으로 다른 캐릭터길이가 다른 코드에 해당하므로 디코딩이 어렵습니다.
예시:균일한 코드로 이진 코딩을 사용하여 문자 A, B, C, D를 암호화하고 가능한 메시지 수를 계산합니다.
그래서 우리는 유니폼 코드, 왜냐하면 각 코드 워드의 길이는 모든 코드에서 동일합니다. (2).
메시지 인코딩 및 디코딩
디코딩(디코딩)일련의 코드에서 메시지를 복원하는 것입니다.
디코딩 문제를 해결하려면 Fano 조건을 알아야 합니다.
파노 상태:코드워드는 다른 코드워드의 시작이 되어서는 안 됩니다(처음부터 메시지의 명확한 디코딩을 보장함)
접두사 코드다른 코드 워드의 시작과 코드 워드가 일치하지 않는 코드입니다. 이러한 코드를 사용하는 메시지는 명확하게 디코딩됩니다.

명확한 디코딩이 제공됩니다.



시험 5과제 풀이
사용 5.1:문자 O, B, D, P, A를 인코딩하기 위해 우리는 각각 숫자 0, 1, 2, 3, 4의 이진 표현을 사용하기로 결정했습니다. ).
이러한 방식으로 WATERFALL 문자 시퀀스를 인코딩하고 결과를 8진수 코드로 작성합니다.
✍ 해결책:
- 숫자를 이진 코드로 변환하고 문자에 맞게 입력해 보겠습니다.
결과: 22162
컴퓨터 과학, 비디오에서이 작업의 시험 결정 :
시험의 5가지 작업에 대한 또 다른 분석을 고려하십시오.
사용 5.2:라틴 알파벳 5개 문자의 경우 이진 코드가 제공됩니다(일부 문자의 경우 2비트, 일부 문자의 경우 3개). 이러한 코드는 표에 나와 있습니다.
| ㅏ | 비 | 씨 | 디 | 이자형 |
|---|---|---|---|---|
| 000 | 110 | 01 | 001 | 10 |
이진 문자열 1100000100110으로 인코딩된 문자 집합은 무엇입니까?
✍ 해결책:
- 먼저 Fano 조건을 확인합니다. 코드 워드가 다른 코드 워드의 시작 부분이 아닙니다. 조건이 맞습니다.
- 표에 제시된 데이터에 따라 코드를 왼쪽에서 오른쪽으로 나눕니다. 그런 다음 문자로 번역합니다.
✎ 1 솔루션:
결과: b a c d e.
✎ 해결 방법 2:
 110
000 01
001 10
110
000 01
001 10
결과: b a c d e.
또한 컴퓨터 과학에서 이 USE 작업에 대한 솔루션의 비디오를 볼 수 있습니다.
다음 5가지 작업을 해결해 보겠습니다.
사용 5.3:
잡음이 있는 채널을 통해 번호를 전송하기 위해 패리티 코드가 사용됩니다. 각 숫자는 이진 표현으로 작성되며 앞에 오는 0은 길이가 4까지 추가되고 요소의 합은 모듈로 2가 결과 시퀀스에 추가됩니다(예: 23을 전달하면 시퀀스 0010100110을 얻음). .
01100010100100100110 형식으로 채널을 통해 전송된 번호를 확인합니다.
✍ 해결책:
- 고려하다 예시문제 진술에서 :
대답: 6 5 4 3
컴퓨터 과학에서 이 USE 작업에 대한 솔루션의 비디오를 볼 수 있습니다.
사용 5.4:
K, L, M, H 문자로 구성된 특정 시퀀스를 인코딩하기 위해 Fano 조건을 만족하는 비균일 바이너리 코드를 사용하기로 결정했습니다. 코드 워드 0은 문자 H에 사용되었고 코드 워드 10은 문자 K에 사용되었습니다.
4개의 코드워드 모두에서 가능한 가장 작은 총 길이는 얼마입니까?
✍ 해결책:
✎ 1 솔루션논리적 추론을 기반으로:
- 모든 문자에 대해 가능한 가장 짧은 코드 단어를 찾아봅시다.
- 코드 워드 01 그리고 00 Fano 조건이 위반되기 때문에 사용할 수 없습니다(0에서 시작하고 0 - 이것은 시간).
- 두 자리 코드 단어부터 시작하겠습니다. 편지를 받자 엘코드워드 11 . 그런 다음 네 번째 문자의 경우 Fano 조건을 위반하지 않고 코드 단어를 선택하는 것이 불가능합니다(110 또는 111을 선택하면 11로 시작).
- 따라서 세 자리 코드 단어를 사용해야 합니다. 문자를 인코딩하자 엘그리고 중코드 워드 110 그리고 111 . Fano 조건이 충족됩니다.
✎ 솔루션 2:
 (N) -> 0 -> 1자(K) -> 10 -> 2자(L) -> 110 -> 3자(M) -> 111 -> 3자
(N) -> 0 -> 1자(K) -> 10 -> 2자(L) -> 110 -> 3자(M) -> 111 -> 3자 대답: 9
Informatics 5 task 2017 FIPI 옵션 2에서 사용(Krylov S.S., Churkina T.E. 편집):
4개의 문자만 포함하는 메시지는 통신 채널을 통해 전송됩니다: A, B, C, D; 전송을 위해 명확한 디코딩을 허용하는 이진 코드가 사용됩니다. 문자 A, B, C의 경우 A: 101010, B: 011011, C: 01000 코드 단어가 사용됩니다.
Г, 코드가 명확한 디코딩을 허용합니다. 최소숫자 값.
✍ 해결책:
- 가장 작은 코드는 다음과 같습니다. 0 그리고 1 (단일 비트). 그러나 이것은 Fano 조건( 하지만하나에서 시작 101010 , 비처음부터 시작합니다 - 011011 ).
- 다음으로 작은 코드는 두 글자 단어입니다. 00 . 제시된 코드 단어의 접두사가 아니므로 지 = 00.
결과: 00
Informatics 5 task 2017 FIPI 옵션 16에서 사용(Krylov S.S., Churkina T.E. 편집):
A, B, C, D 및 E 문자로 구성된 특정 시퀀스를 인코딩하기 위해 통신 채널의 수신측에 나타나는 바이너리 시퀀스를 고유하게 디코딩할 수 있는 비균일 바이너리 코드를 사용하기로 결정했습니다. 사용 코드: A - 01, B - 00, C - 11, D - 100.
문자 D를 인코딩해야 하는 코드 단어를 지정합니다. 길이이 코드 워드는 최소가능한 모든 것. 코드는 명확한 디코딩 속성을 충족해야 합니다. 이러한 코드가 여러 개 있는 경우 가장 작은 숫자 값으로 코드를 표시합니다.
✍ 해결책:
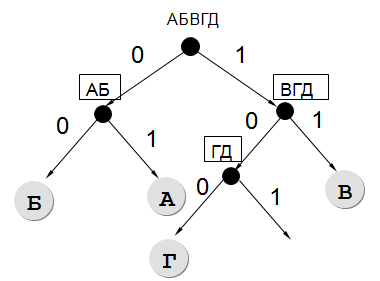
결과: 101
수업에 대한 더 자세한 분석은 Informatics 2017의 통합 국가 시험 비디오에서 볼 수 있습니다.
Informatics 5 task 2017 FIPI 옵션 17에서 사용(Krylov S.S., Churkina T.E.):
A, B, C, D, D 및 E 문자로 구성된 특정 시퀀스를 인코딩하기 위해 통신 채널의 수신측에 나타나는 바이너리 시퀀스를 고유하게 디코딩할 수 있는 비균일 바이너리 코드를 사용하기로 결정했습니다. . 사용 코드: A - 0, B - 111, C - 11001, D - 11000, D - 10.
문자 E를 인코딩해야 하는 코드 단어를 지정합니다.이 코드 워드의 길이는 가능한 가장 작아야 합니다. 코드는 명확한 디코딩 속성을 충족해야 합니다. 이러한 코드가 여러 개 있는 경우 가장 작은 숫자 값으로 코드를 표시합니다.
✍ 해결책:
 1 - 적합하지 않음(A를 제외한 모든 문자는 1로 시작) 10 - 적합하지 않음(코드 D에 해당) 11 - 적합하지 않음(코드 B, C 및 D의 시작) 100 - 적합하지 않음(코드 D - 10 - 시작 101 - 적합하지 않음(코드 D - 10 - 이 코드의 시작) 110 - 적합하지 않음(코드 C 및 D의 시작) 111 - 적합하지 않음(코드 B에 해당) 1000 - 적합하지 않음(코드 D - 10 - 이 코드의 시작) 1001 - 적합하지 않음(코드 D - 10 - 이 코드의 시작) 1010 - 적합하지 않음(코드 D - 10 - 이 코드의 시작) 1011 - 적합하지 않음(코드 D - 10 - 이 코드의 시작) 1100 - 적합하지 않음( 코드 C 및 D의 시작) 1101 - 적합
1 - 적합하지 않음(A를 제외한 모든 문자는 1로 시작) 10 - 적합하지 않음(코드 D에 해당) 11 - 적합하지 않음(코드 B, C 및 D의 시작) 100 - 적합하지 않음(코드 D - 10 - 시작 101 - 적합하지 않음(코드 D - 10 - 이 코드의 시작) 110 - 적합하지 않음(코드 C 및 D의 시작) 111 - 적합하지 않음(코드 B에 해당) 1000 - 적합하지 않음(코드 D - 10 - 이 코드의 시작) 1001 - 적합하지 않음(코드 D - 10 - 이 코드의 시작) 1010 - 적합하지 않음(코드 D - 10 - 이 코드의 시작) 1011 - 적합하지 않음(코드 D - 10 - 이 코드의 시작) 1100 - 적합하지 않음( 코드 C 및 D의 시작) 1101 - 적합
결과: 1101
이 작업에 대한 보다 자세한 솔루션은 비디오 자습서에 나와 있습니다.
5 과제. FIPI(Unified State Examination Informatics) 2018 정보학 데모 버전:
A, B, E, I, K, L, R, C, T, U와 같은 10개의 문자만 포함하는 암호화된 메시지가 통신 채널을 통해 전송됩니다. 전송에는 고르지 않은 이진 코드가 사용됩니다. 코드 단어는 아홉 글자에 사용됩니다. 
문자의 가장 짧은 코드 단어를 지정하십시오. 비, 이 조건에서 코드는 Fano 조건을 충족합니다.그러한 코드가 여러 개 있는 경우 다음으로 코드를 표시하십시오. 최소숫자 값.
✍ 해결책:
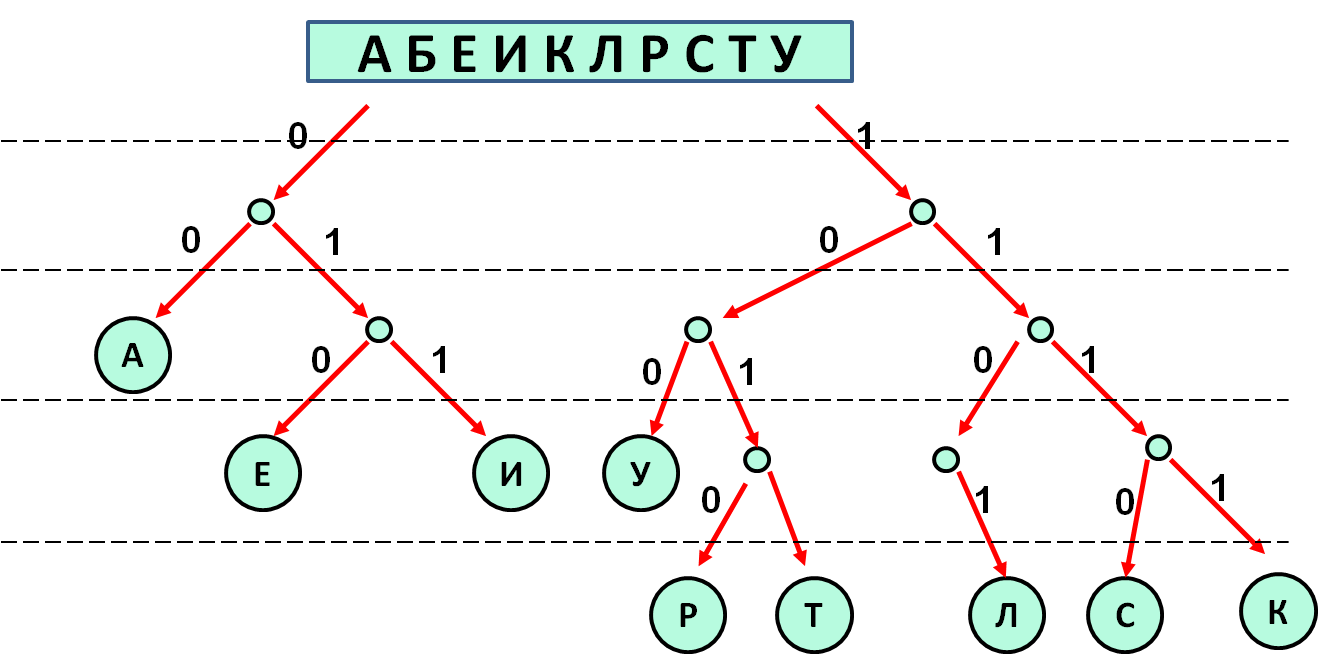
결과: 1100
2018년 USE 데모 버전의 이 5가지 작업에 대한 자세한 솔루션은 다음 동영상을 참조하세요.
작업 5_9. 전형적인 시험 옵션 2017. 옵션 4(Krylov S.S., Churkina T.E.):
4개의 문자만 포함하는 암호화된 메시지는 통신 채널을 통해 전송됩니다. A, B, C, G; 전송을 위해 명확한 디코딩을 허용하는 이진 코드가 사용됩니다. 편지의 경우 하지만, 비, 에코드 단어가 사용됩니다.
A: 00011 B: 111 C: 1010
문자의 가장 짧은 코드 단어를 지정하십시오. G, 코드가 명확한 디코딩을 허용합니다.그러한 코드가 여러 개 있는 경우 다음으로 코드를 표시하십시오. 최소숫자 값.
✍ 해결책:

결과: 00
작업 5_10. 2018년 10월 1일자 교육 옵션 3번(FIPI):
문자만 포함된 메시지는 통신 채널을 통해 전송됩니다. A, E, D, K, M, R; 전송을 위해 Fano 조건을 만족하는 바이너리 코드가 사용됩니다. 다음 코드가 사용되는 것으로 알려져 있습니다.
E - 000 D - 10 K - 111
인코딩된 메시지의 가능한 가장 작은 길이를 지정하십시오. 데드마카르.
대답에 숫자를 쓰십시오 - 비트 수.
✍ 해결책:
 D E D M A C A R 10 000 10 001 01 111 01 110
D E D M A C A R 10 000 10 001 01 111 01 110
결과: 20
문제에 대한 해결책을 참조하십시오.
운동:
1)
문자 A, B, C, D를 인코딩하기 위해 두 자리 순차 이진수(00에서 11까지)를 사용하기로 결정했습니다.각기). 이러한 방식으로 GBAB 기호 시퀀스를 인코딩하고 결과를 다음과 같이 씁니다.16진수 시스템에서는 다음을 얻습니다.
1) 132
16 2)
D2 16 3) 3102 16 4) 2D 16
솔루션 및 답변:
조건에서 각각 :
A - 00
B - 01
10시에
지 - 11
GBAV = 11010010 - 이 이진 표기법을 16진수 시스템으로 변환하고 D2를 얻습니다.
답: 2
2) 문자 A, B, C, D를 인코딩하기 위해 두 자리 순차 이진수(각각 00에서 11까지)를 사용하기로 결정했습니다. 이러한 방식으로 GBVA 문자 시퀀스를 인코딩하고 결과를 16진수 코드로 작성하면 다음을 얻습니다.
1) 138 16 2) DBCA 16 3) D8 16 4) 3120 16
솔루션 및 답변:
조건별:
A = 00
B = 01
B = 10
지 = 11
수단:
GBVA = 11011000(바이너리). 16진수로 변환하고 D8 얻기
답: 3
3)
라틴 알파벳 5개 문자의 경우 이진 코드가 제공됩니다(일부 문자의 경우 2비트, 일부 문자의 경우 3개). 이러한 코드는 표에 나와 있습니다.
에이 비 씨 디이
000 110 01 001 10
이진 문자열 1100000100110으로 인코딩된 문자 집합을 결정합니다.
1) 바데 2) 바데 3)
bacde 4) bacdb
솔루션 및 답변:
이진 코드가 110이므로 첫 번째 문자는 b입니다.
이진 코드가 000이므로 두 번째 문자는 a입니다.
세 번째 문자는 이진 코드가 01이므로 c입니다.
이진 코드가 001이기 때문에 네 번째 문자는 d입니다.
이진 코드가 10이므로 다섯 번째 문자는 e입니다.
결과: 옵션 번호 3에 해당하는 bacde.
답: 3
4)
문자 A, B, C, D를 인코딩하기 위해 각각 1000에서 1011까지의 4비트 순차 이진수가 사용됩니다. 이러한 방식으로 BGAW 기호 시퀀스를 인코딩하고 결과를 8진수 코드로 작성하면 다음을 얻습니다.
1) 175423 2)
115612 3) 62577 4) 12376
솔루션 및 답변:
조건별:
A = 1000
B = 1001
B = 1010
지 = 1011
BGAV = 1001101110001010, 이제 이 숫자를 2진수에서 8진수로 변환하고 답을 얻어야 합니다.
1001101110001010 2 = 115612 8
답: 2
5)
문자 A, B, C, D를 인코딩하기 위해 1부터 시작하는 세 자리 연속 이진수(각각 100에서 111까지)가 사용됩니다. 이러한 방식으로 CDAB 문자 시퀀스를 인코딩하고 결과를 16진수 코드로 작성하면 다음을 얻습니다.
1) A52 16 2) 4C8 16 3) 15D 16 4)
DE5 16
솔루션 및 답변:
조건: 각각
A=100
B=101
C=110
D=111
CDAB = 110111100101, 이진수를 16진수로 변환:
110111100101 2 = DE5 16
답: 4
6)
문자 K, L, M, N을 인코딩하기 위해 각각 1000에서 1011까지의 4비트 순차 이진수가 사용됩니다. 이러한 방식으로 KMLN 문자 시퀀스를 인코딩하고 결과를 8진수 코드로 작성하면 다음을 얻습니다.
1) 84613 8 2)
105233 8 3) 12345 8 4) 776325 8
솔루션 및 답변:
조건: 각각
K=1000
패=1001
M=1010
N=1011
KMLN = 1000101010011011, 8진수로 변환:
1000101010011011 2 = 105233 8
답: 2
7) 라틴 알파벳 5개 문자의 경우 이진 코드가 제공됩니다(일부 문자의 경우 2비트, 일부 문자의 경우 3개). 이러한 코드는 표에 나와 있습니다.
에이 비 씨 디이
100 110 011 01 10
시퀀스의 모든 문자가 다르다는 것이 알려진 경우 이진 문자열 1000110110110으로 인코딩된 문자 집합을 결정합니다.
1) 씨바데 2)
acdeb 3) acbed 4) bacde
솔루션 및 답변:
비트 형식으로 바이너리 코드를 작성해 보겠습니다. 옵션반복되는 글자를 피하기 위해.
결과: 100 011 01 10 110
따라서: 아크데브
답: 2
8)
라틴 알파벳 6개 문자의 경우 이진 코드가 제공됩니다(일부 문자는 2비트, 일부는 3비트). 이러한 코드는 표에 나와 있습니다.
A B C D E F
00 100 10 011 11 101
이진 문자열 011111000101100으로 인코딩된 6개의 문자 시퀀스를 결정합니다.
1) DEFBAC 2) ABDEFC 3)
DECAFB 4) EFCABD
솔루션 및 답변:
답변의 문자가 반복되지 않기 때문에 열거로 해결할 것입니다. 즉, 코드가 반복되어서는 안됩니다.
우리는 다음을 얻습니다.
011 11 10 00 101 100
각기: DECAFB
답: 3
9)
문자 A, B, C, D를 인코딩하기 위해 1부터 시작하는 4비트 연속 이진수(각각 1001에서 1100까지)가 사용됩니다. 이러한 방식으로 CADB 문자 시퀀스를 인코딩하고 결과를 16진수 코드로 작성하면 다음을 얻습니다.
1)
AF52 16 2)
4CB8 16 3)
F15D16 4)
B9CA 16
솔루션 및 답변: 각각..
A-1001
B-1010
C-1011
D-1100
따라서: CADB = 1011100111001010, 1011100111001010을 2진수에서 16진수로 변환합니다.
1011 1001 1100 1010 2 = B9CA 16 ,
네 번째 옵션에 해당합니다.
답: 4
10)
A B C D
00 11 010 011
이러한 방식으로 VGAGBV 문자 시퀀스를 인코딩하고 결과를 16진수 코드로 작성하면 다음을 얻습니다.
1) CDADBC 16 2) A7C4 16 3) 412710 16 4)
4S7A 16
솔루션 및 답변:
VGAGBV = 0100110001111010, 16진수로 변환:
0100 1100 0111 1010 2 = 4C7A 16
답: 4
11)
문자 A, B, C 및 D로만 구성된 메시지를 인코딩하려면 길이가 고르지 않은 이진 코드가 사용됩니다.
A B C D
00 11 010 011
이러한 방식으로 GAVBVG 문자 시퀀스를 인코딩하고 결과를 16진수 코드로 작성하면 다음을 얻습니다.
1)
62D3 16 2) 3D26 16 3) 31326 16 4) 62133 16
솔루션 및 답변:
GAVBVG = 0110001011010011 2 - 16진수 시스템으로 변환:
0110 0010 1101 0011 2 = 62D3 16
답: 1
12) 문자 A, B, C 및 D로만 구성된 메시지를 인코딩하기 위해 불균일한 길이가 사용됩니다.
바이너리 코드:
A B C D
00 11 010 011
이러한 방식으로 GBWAVG 문자 시퀀스를 인코딩하고 결과를 16진수로 작성하면
코드는 다음을 얻습니다.
1) 71013 16 2) DBCACD 16 3) 31A7 16 4)
7A13 16
솔루션 및 답변:
GBVAVG = 0111101000010011 2 - 16진수로 변환합니다.
0111 1010 0001 0011 2 = 7A13 16
답: 4
13)
문자 A, B, C 및 D로만 구성된 메시지를 인코딩하려면 길이가 고르지 않은 이진 코드가 사용됩니다.
A B C D
00 11 010 011
이러한 방식으로 GAVBGV 문자 시퀀스를 인코딩하고 결과를 16진수 코드로 작성하면 다음을 얻습니다.
1) DACBDC 16 2) AD26 16 3) 621310 16 4)
62DA 16
솔루션 및 답변: 각각..
GAVBGV = 0110001011011010 2 , 16진수로 변환:
0110 0010 1101 1010 2 = 62DA 16
답: 4
14)
문자 A, B, C, D 및 E로만 구성된 메시지를 인코딩하려면 길이가 고르지 않은 이진 코드가 사용됩니다.
에이 비 씨 디이
000 11 01 001 10
수신된 4개의 메시지 중 오류 없이 전송되었으며 디코딩할 수 있는 메시지(단 하나만!)는 무엇입니까?
1)
110000010011110
2) 110000011011110
3) 110001001001110
4) 110000001011110
솔루션 및 답변:
첫 번째 코드를 살펴보겠습니다.
11 000 001 001 11 10 = 바드베
두 번째 코드:
11 000 001 10 11 110 = 마지막에 철자가 틀렸습니다.
세 번째 코드:
11 000 10 01 001 110 = 끝에 맞춤법이 틀립니다.
네 번째 코드:
11,000,000 10 11 110 = 마지막에 맞춤법이 틀립니다.
답: 1
15)
코딩: A-00, B-11, V-010, G-011. 메시지는 통신 채널인 WAGBGV를 통해 전송됩니다. 메시지 인코딩
주어진 코드. 결과 이진 시퀀스를 16진수로 변환합니다.
1) AD34 2)
43DA 3) 101334 4) CADBCD
솔루션 및 답변:
VAGBGV = 0100001111011010 2 , 16진수 시스템으로 변환:
0100 0011 1101 1010 2 = 43DA 16
답: 2
16)
문자 A, B, C, D로만 구성된 메시지의 통신 채널을 통한 전송을 위해 길이가 고르지 않은 코드(A=1, B=01, C=001)를 사용하기로 결정했습니다. 코드 길이를 최소화하고 인코딩된 메시지를 문자로 명확하게 나눌 수 있도록 문자 G를 어떻게 인코딩해야 합니까?
1) 0001 2)
000 3) 11 4) 101
솔루션 및 답변:
메시지를 디코딩하려면 두 코드 모두 다른 긴 코드의 시작 부분이 아니어야 합니다.
1, 3 및 4 옵션은 적합하지 않으며 다른 코드의 시작입니다.
옵션 2 - 다른 코드의 시작이 아닙니다.
답: 2
17) 문자 A, B, C, D로만 구성된 메시지의 통신 채널을 통한 전송을 위해 길이가 고르지 않은 코드(A=0, B=100, C=101)를 사용하기로 결정했습니다. 코드 길이를 최소화하고 인코딩된 메시지를 문자로 명확하게 나눌 수 있도록 문자 G를 어떻게 인코딩해야 합니까?
1) 1 2) 11 3) 01 4) 010
작업 번호 16과 유사합니다.
답: 2
18) 흑백 비트맵은 왼쪽에서 시작하여 한 줄씩 인코딩됩니다. 상단 모서리오른쪽 하단 모서리에서 끝납니다. 인코딩할 때 1은 검정색을 나타내고 0은 흰색을 나타냅니다.
간결함을 위해 결과는 8진수 시스템으로 작성되었습니다. 올바른 코드 항목을 선택하십시오.
1) 57414 2) 53414 3)
53412 4) 53012
솔루션 및 답변:
인코딩 후 우리는 주어진 코드:
101011100001010 2 , 이 코드를 8진수로 변환합니다.
101 011 100 001 010 2 = 53412 8
답: 3
19) 통신 채널을 통해 문자 A, B, C 및 D로만 구성된 메시지를 문자 단위로 전송하려면
코딩: A-0, B-11, V-100, G-011. 메시지는 통신 채널 GBAVAVG를 통해 전송됩니다. 메시지 인코딩
주어진 코드. 결과 이진 시퀀스를 8진수 코드로 변환합니다.
1) DBACACD 2) 75043 3) 7A23 4) 3304043
솔루션 및 답변: 따라서:
GBAAVG = 0111101000100011 2 , 8진법으로 변환합니다.
0 111 101 000 100 011 2 \u003d 75043 8, 첫 번째 0은 중요하지 않습니다.
답: 2
20) 5비트 코드는 통신 채널을 통해 데이터를 전송하는 데 사용됩니다. 메시지에는 다음 항목만 포함됩니다.
다음 코드 워드로 인코딩된 문자 A, B 및 C:
A - 11010, B - 00110, C - 10101.
전송이 중단될 수 있습니다. 그러나 일부 오류는 수정할 수 있습니다. 이 세 가지 코드 단어 중 두 개는 적어도 세 위치에서 서로 다릅니다. 따라서 단어의 전송에 최대 한 위치에 오류가 있으면 어떤 문자가 전송되었는지에 대해 교육받은 추측을 할 수 있습니다. ("코드는 하나의 오류를 수정합니다."라고 합니다.) 예를 들어, 코드 워드 10110이 수신되면 문자 B가 전송된 것으로 간주됩니다.(B의 코드 워드와 차이는 한 위치에 있을 뿐입니다. 나머지 부호어에는 차이가 더 큽니다.) 수신한 경우 A, B, C 문자에 대한 부호어와 둘 이상의 위치에서 부호어가 다르면 오류가 발생한 것으로 간주합니다. '엑스').
메시지 00111 11110 11000 10111이 수신되었습니다. 이 메시지를 해독 - 올바른 옵션을 선택하십시오.
1) BAAx
2)
BAAV
3) xxx
4) xAAx
해결책:
1) 00111 = B는 마지막 숫자에 1개의 오류가 있기 때문입니다.
2) 11110 = A, 세 번째 자리에 오류가 1개 있기 때문입니다.
3) 11000 = A, 네 번째 자리에 오류가 1개 있기 때문입니다.
4) 10111 = 네 번째 자리에 1 오류가 있으므로 B
00111 11110 11000 10111 = BAAV.
답: 2
모스크바시의 GBPOU "스포츠 및 교육 대학"
모스크바시 스포츠 및 관광학과
정보학 및 ICT 교사: Makeeva E.S.
USE 작업. 코딩 문자 정보
작업 1
각 문자가 1바이트로 인코딩된다고 가정하고 인코딩에서 다음 문장의 크기(비트 단위)를 추정합니다.아스키: http:// www. 피피. ko
작업 2
KOI-8 인코딩에서 각 문자는 8비트로 인코딩됩니다. 다음 문장의 정보 크기(바이트)를 결정합니다.우편 . ko - 메일 서버. 답은 숫자로만 주십시오.
작업 3
의 각 캐릭터는유니코드2바이트 워드로 인코딩됩니다. 다음 구 A.P.의 정보량(비트)을 결정하십시오. 이 인코딩의 체호프:이해할 수 없는 것이 기적입니다. 답은 숫자로만 주십시오.
작업 4
에 텍스트 에디터포함된 텍스트 인코딩 KOI-8(1문자당 1바이트). 소년은 몇 단어를 입력했습니다. 소년이 입력한 정보의 총량이 592비트라면 편집기에 입력되는 문자는 몇 개입니까?
작업 5
오퍼의 정보량당신은 기름으로 죽을 망치지 않을 것입니다. 50바이트입니다. 한 문자를 인코딩하는 비트 수를 결정합니다. 답은 숫자로만 주십시오.
작업 6
유니코드 인코딩(인코딩 테이블에 65,536자 포함)에서 Windows 인코딩(인코딩 테이블에 256자 포함)으로 변환될 때 텍스트 페이지의 정보 볼륨(텍스트에는 서식 제어 문자가 포함되지 않음)이 몇 번이나 감소합니까? ? 답은 숫자로만 주십시오.
작업 7
코드 테이블 CP1251(Windows 키릴 자모)이 사용됩니다. 텍스트가 200페이지, 페이지당 32줄, 그리고 줄당 평균 48자가 있는 경우 일반 텍스트 파일은 몇 킬로바이트를 사용합니까? 답은 숫자로만 주십시오.
작업 8
광학 문자 인식 시스템을 사용하면 문서 페이지의 스캔 이미지를 텍스트 형식분당 4페이지의 속도로 65,536자의 알파벳을 사용합니다. 각 페이지에 50자의 40줄이 포함된 텍스트 문서는 애플리케이션 작업 10분 후에 얼마나 많은 정보(킬로바이트)를 전달할 수 있습니까?답은 숫자로만 주십시오.
작업 9
150자를 포함하는 그리스어 메시지가 16비트 코드로 작성되었습니다.유니코드. 메시지의 정보 크기(바이트)는 얼마입니까? 답은 숫자로만 주십시오.
작업 10
자동 장치는 16비트 표현에서 러시아어로 정보 메시지의 자동 기록을 수행했습니다.유니코드8비트 KOI-8 인코딩으로 기록하기 전 메시지의 정보량은 30바이트였다. 기록 후 메시지의 정보량(비트 단위)을 결정합니다. 답은 숫자로만 주십시오.
USE 작업. 텍스트 정보의 인코딩.
작업 1
자동 장치는 원래 16비트 유니코드 코드로 작성된 러시아어 정보 메시지를 8비트 KOI-8 인코딩으로 다시 코딩했습니다. 이 경우 정보 메시지는 640비트 감소했습니다. 문자로 된 메시지의 길이는 얼마입니까?
작업 2
자동 장치는 원래 2바이트 유니코드 코드로 기록된 50자 길이의 러시아어 정보 메시지를 8비트 KOI-8 인코딩으로 녹음했습니다. 얼마나 많은 비트만큼 메시지 길이가 줄어들었습니까?
작업 3
자동 장치는 원래 2바이트 유니코드 코드로 기록된 55자 길이의 러시아어 정보 메시지를 8비트 KOI-8 인코딩으로 기록했습니다. 얼마나 많은 비트만큼 메시지 길이가 줄어들었습니까? 답에 숫자만 쓰십시오.
작업 4
자동 장치는 원래 2바이트 유니코드 코드로 기록된 100자 길이의 러시아어 정보 메시지를 8비트 KOI-8 인코딩으로 기록했습니다. 얼마나 많은 비트만큼 메시지 길이가 줄어들었습니까? 답에 숫자만 쓰십시오.
작업 5
러시아어로 된 메시지는 원래 16비트 유니코드로 작성되었습니다. 8비트 KOI-8 인코딩으로 다시 코딩하면 정보 메시지가 80비트 감소했습니다. 메시지에는 몇 글자가 포함되어 있습니까?
작업 6
러시아어로 된 메시지는 원래 16비트 유니코드로 작성되었습니다. 8비트 KOI-8 인코딩으로 다시 코딩하면 정보 메시지가 320비트 감소했습니다. 메시지에는 몇 글자가 포함되어 있습니까?
작업 7
텍스트 문서, 10240자로 구성된 8비트 KOI-8 인코딩으로 저장되었습니다. 이 문서는 16비트 유니코드로 변환되었습니다. 문서를 저장하는 데 필요한 추가 KB를 지정합니다. 답에 숫자만 쓰십시오.
작업 8
11264자로 구성된 텍스트 문서는 8비트 KOI-8 인코딩으로 저장되었습니다. 이 문서는 16비트 유니코드로 변환되었습니다. 문서를 저장하는 데 필요한 추가 KB를 지정합니다. 답에 숫자만 쓰십시오.
작업 9
러시아어로 된 메시지는 원래 16비트 유니코드로 작성되었습니다. 자동 장치는 8비트 인코딩으로 변환을 수행했습니다.창1251. 동시에 정보 메시지가 320바이트 감소했습니다. 메시지 길이를 문자로 지정하십시오.
작업 10
전자 사용자 사서함인코딩을 선택하여 러시아어로 편지를 썼습니다.유니코드. 그러나 그는 8비트 KOI-8 인코딩을 사용하기로 결정했습니다. 동시에 그의 편지의 정보량은 2Kbytes 감소했다. 문자로 된 메시지의 길이는 얼마입니까?
USE 작업. 그래픽 정보 인코딩
작업 1
흑백(회색조 없음) 래스터 그래픽 이미지의 크기는 10x10픽셀입니다. 이 이미지는 비트 단위로 얼마나 많은 메모리를 차지합니까? 답에 숫자만 쓰십시오.
작업 2
흑백(회색조 없음) 래스터 그래픽 이미지의 크기는 20x20픽셀입니다. 이 이미지는 얼마나 많은 메모리(바이트)를 차지합니까? 답에 숫자만 쓰십시오.
작업 3
색상(256색 팔레트 포함) 래스터 그래픽 이미지의 크기는 10x10픽셀입니다. 이 이미지는 비트 단위로 얼마나 많은 메모리를 차지합니까? 답에 숫자만 쓰십시오.
작업 4
비트맵 변환 중 그래픽 이미지색상 수가 65,536에서 16으로 줄었습니다. 그래픽 파일의 정보량이 몇 번이나 줄었습니까?
작업 5
래스터 그래픽 파일을 변환하는 과정에서 색상 수가 1024개에서 32개로 줄었습니다. 파일의 정보량이 몇 번이나 줄었습니까?
작업 6
보관용 비트맵 32×32 픽셀 크기는 512바이트의 메모리를 사용했습니다. 이미지 팔레트에서 가능한 최대 색상 수는 얼마입니까? 답에 숫자만 쓰십시오.
작업 7
64 × 64 픽셀의 비트맵 이미지를 저장하기 위해 3킬로바이트의 메모리가 할당되었습니다. 이미지 팔레트에서 가능한 최대 색상 수는 얼마입니까? 답에 숫자만 쓰십시오.
작업 8
이미지 팔레트에 65,000개의 색상이 포함된 경우 240×192 픽셀 비트맵을 저장하기 위해 할당해야 하는 메모리 양(KB)은 얼마입니까? 답에 숫자만 쓰십시오.
작업 9
모니터 화면 해상도 1024x768 픽셀, 색 농도 - 16비트. 이 그래픽 모드에 필요한 비디오 메모리 양(MB)은 얼마입니까? 답에 숫자만 쓰십시오.
작업 10
이미지 팔레트에 1600만 색상이 있는 경우 640×480 픽셀 비트맵을 저장하려면 얼마나 많은 메모리(KB)를 할당해야 합니까? 답에 숫자만 쓰십시오.
USE 작업. 오디오 인코딩.
작업 1
비슷한 물건 소리 신호먼저 65,536개의 신호 강도 수준(오디오 CD 음질)을 사용하여 샘플링한 다음 256개의 신호 강도 수준(라디오 방송 음질)을 사용하여 샘플링했습니다. 디지털화된 오디오 신호의 정보량은 몇 번이나 다른가?답에 숫자만 쓰십시오.
작업 2
2채널(스테레오) 오디오는 16kHz의 샘플링 주파수와 24비트 해상도로 녹음됩니다. 기록은 8분 동안 지속되며 결과는 파일에 기록되고 데이터 압축은 수행되지 않습니다. 다음 값 중 결과 파일의 크기에 가장 가까운 값은 무엇입니까?
작업 3
16kHz의 샘플링 주파수와 24비트 해상도의 2채널(스테레오) 사운드 녹음을 5분 동안 수행했습니다. 데이터 압축이 수행되지 않았습니다. 다음 값 중 결과 파일의 크기에 가장 가까운 값은 무엇입니까?
작업 4
32kHz의 샘플링 주파수와 24비트 해상도로 5분 동안 2채널(스테레오) 사운드 녹음을 수행했습니다. 데이터 압축이 수행되지 않았습니다. 다음 값 중 결과 파일의 크기에 가장 가까운 값은 무엇입니까?
작업 5
단일 채널(모노) 사운드 녹음은 32kHz의 샘플링 주파수와 32비트 해상도로 수행되었습니다. 결과적으로 20MB 파일을 얻었고 데이터 압축이 수행되지 않았습니다. 다음 값 중 녹음이 이루어진 시간에 가장 가까운 값은 무엇입니까?
작업 6
단일 채널(모노) 사운드 녹음은 32kHz의 샘플링 주파수와 32비트 해상도로 수행되었습니다. 결과적으로 40MB의 파일을 얻었고 데이터 압축은 수행되지 않았습니다. 다음 값 중 녹음이 이루어진 시간에 가장 가까운 값은 무엇입니까?
작업 7
2채널(스테레오) 사운드 녹음은 16kHz의 샘플링 주파수와 24비트 해상도로 만들어졌습니다. 결과적으로 30MB의 파일을 얻었고 데이터 압축은 수행되지 않았습니다. 다음 값 중 녹음이 이루어진 시간에 가장 가까운 값은 무엇입니까?
작업 8
16kHz의 샘플링 주파수와 24비트 해상도의 2채널(스테레오) 사운드 녹음을 10분 동안 수행했습니다. 데이터 압축이 수행되지 않습니다. 다음 값 중 결과 파일의 크기에 가장 가까운 값은 무엇입니까?
작업 9
사용자는 1분의 길이와 16비트의 해상도로 디지털 오디오 파일(모노)을 녹음해야 합니다. 사용자에게 2.6MB의 메모리가 있는 경우 샘플링 속도는 얼마여야 합니까?
작업 10
디지털 오디오 파일(모노)의 길이는 1분입니다. 그러나 2.52MB를 차지합니다. 사운드 카드의 비트 심도가 8비트인 경우 사운드가 녹음되는 샘플 레이트는 얼마입니까?
테스트. 옵션 1
작업 1
러시아어로 된 문구는 16비트 코드로 인코딩되었습니다.유니코드:
"모르는 것이 부끄러운 일이 아니라 배우기 싫은 것이 부끄러운 일이다"(소크라테스)
이 구(따옴표)의 정보 볼륨은 바이트 단위입니다. 답에 숫자만 쓰십시오.
작업 2
20480자로 구성된 텍스트 문서는 8비트 KOI-8 인코딩으로 저장되었습니다. 이 문서는 16비트 유니코드로 변환되었습니다. 문서를 저장하는 데 필요한 추가 KB를 지정합니다. 답에 숫자만 쓰십시오.
작업 3
이미지 팔레트에 64개의 색상이 있는 경우 128×128 픽셀 비트맵을 저장하려면 얼마나 많은 메모리(KB)를 할당해야 합니까? 답에 숫자만 쓰십시오.
작업 4
160 × 128 픽셀의 비트맵 이미지를 저장하기 위해 5킬로바이트의 메모리가 할당되었습니다. 이미지 팔레트에서 가능한 최대 색상 수는 얼마입니까? 답에 숫자만 쓰십시오.
작업 5
디지털 오디오 파일(모노)은 2.7MB의 메모리, 16비트 해상도를 차지합니다. 소리의 지속 시간이 1분이면 소리가 녹음되는 샘플링 레이트는 얼마입니까?
테스트. 옵션 2
작업 1
의 각 캐릭터는유니코드2바이트 워드로 인코딩됩니다. 다음 문장의 정보량을 바이트 단위로 추정하십시오.
"탭 - 대화 상자의 섹션(페이지)"
답에 숫자만 쓰십시오.
작업 2
일부 메시지는 원래 16비트 유니코드로 작성되었습니다. 8비트 KOI-8 인코딩으로 다시 코딩하면 정보 메시지가 1040비트 감소했습니다. 메시지 길이를 문자로 지정하십시오. 답에 숫자만 쓰십시오.
작업 3
이미지 팔레트에 256개의 색상이 있는 경우 128×128 픽셀 비트맵을 저장하기 위해 할당해야 하는 메모리 양(KB)은 얼마입니까? 답에 숫자만 쓰십시오.
작업 4
64 × 64 픽셀의 비트맵 이미지를 저장하기 위해 3킬로바이트의 메모리가 할당되었습니다. 이미지 팔레트에서 가능한 최대 색상 수는 얼마입니까? 답에 숫자만 쓰십시오.
작업 5
디스크의 여유 메모리 양은 10.1MB이고 사운드 카드의 비트 깊이는 16비트입니다. 44.1kHz 샘플 레이트로 녹음된 오디오 파일(스테레오)의 길이는 얼마입니까?
시험 과제에 대한 답변:
| 1 | 144 | 400 | 300 | 156 | 300 | 120 |
||||
| 2 | 400 | 440 | 800 | 320 | 2048 |
|||||
| 3 | 100 | 800 | 1,5 | 900 |
||||||
| 4 | ||||||||||
| 카운터. 노예. | 118 | |||||||||
| 카운터. 노예. | 130 |
정보와 그 코딩
"정보" 개념의 정의에 대한 다양한 접근. 정보 프로세스의 유형. 인간 활동의 정보 측면
정보(위도. 정보- 설명, 프레젠테이션, 정보 집합) - 컴퓨터 과학의 기본 개념으로, 엄격한 정의를 내릴 수 없지만 설명할 수만 있습니다.
- 정보는 새로운 사실, 새로운 지식입니다.
- 정보는 사물과 현상에 대한 정보이다 환경인간의 인식 수준을 높이는 것;
- 정보는 특정 결정을 내릴 때 이러한 대상 또는 현상에 대한 지식의 불확실성 정도를 줄이는 환경의 대상 및 현상에 대한 정보입니다.
"정보"의 개념은 일반적인 과학, 즉 물리학, 생물학, 사이버네틱스, 정보학 등 다양한 과학에서 사용됩니다. 동시에 각 과학에서 이 개념와 관련된 다양한 시스템개념. 따라서 물리학에서 정보는 반엔트로피(시스템의 질서와 복잡성의 척도)로 간주됩니다. 생물학에서 "정보"의 개념은 유전 메커니즘 연구뿐만 아니라 살아있는 유기체의 편리한 행동과 관련이 있습니다. 사이버네틱스에서 "정보"의 개념은 복잡한 시스템의 제어 프로세스와 관련이 있습니다.
정보의 사회적으로 중요한 주요 속성은 다음과 같습니다.
- 공익사업;
- 접근성(이해성);
- 관련성;
- 완전성;
- 확실성;
- 적절.
인간 사회에서 정보 처리는 지속적으로 발생합니다. 사람들은 감각의 도움으로 주변 세계의 정보를 인식하고 이해하고 수용합니다. 특정 솔루션실제 행동으로 구현되어 주변 세계에 영향을 미칩니다.
정보 처리정보를 수집(수신), 전송(교환), 저장, 처리(변환)하는 과정입니다.
정보 수집- 이것은 다양한 출처에서 필요한 메시지를 검색하고 선택하는 과정입니다(특수 문헌, 참고 도서 작업, 실험 수행, 관찰, 투표, 질문, 정보 및 참조 네트워크 및 시스템 검색 등).
정보 이전전송 채널을 따라 소스에서 수신자로 메시지를 이동하는 프로세스입니다. 정보는 소리, 빛, 초음파, 전기, 텍스트, 그래픽 등 신호의 형태로 전송됩니다. 전송 채널은 영공, 전기 및 광섬유 케이블, 개인, 인간 신경 세포 등이 될 수 있습니다.
데이터 저장고물질 캐리어에 메시지를 고정하는 프로세스입니다. 이제 종이, 나무, 직물, 금속 및 기타 표면, 필름 및 사진 필름, 자기 테이프, 자기 및 레이저 디스크, 플래시 카드 등
데이터 처리기존 메시지에서 새 메시지를 가져오는 프로세스입니다. 정보 처리는 그 양을 늘리는 주요 방법 중 하나입니다. 처리 결과 한 유형의 메시지에서 다른 유형의 메시지를 얻을 수 있습니다.
데이터 보호정보의 우발적 손실, 손상, 수정 또는 무단 액세스를 방지하는 조건을 만드는 과정입니다. 정보를 보호하는 방법은 정보를 만드는 것입니다. 백업, 보안실에 보관, 사용자에게 정보에 대한 적절한 접근 권한 제공, 메시지 암호화 등
정보를 표현하고 전달하는 수단으로서의 언어
에 따라 인식 방식기호는 다음과 같이 나뉩니다.
- 시각적(문자 및 숫자, 수학 기호, 음표, 도로 표지판 등);
- 청각 (구두 연설, 전화, 사이렌, 경고음 등);
- 촉각(시각 장애인을 위한 점자 알파벳, 터치 제스처 등);
- 후각;
- 맛.
장기간 보관을 위해 저장매체에 기호를 기록합니다.
기호는 정보를 전달하는 데 사용됩니다. 신호(신호등 신호, 학교 종 소리 등).
형태와 의미의 소통 방식에 따라기호는 다음과 같이 나뉩니다.
- 상의- 모양이 표시된 개체와 유사합니다(예: 컴퓨터의 "데스크톱"에 있는 "내 컴퓨터" 폴더 아이콘).
- 기호- 형식과 의미 간의 관계는 일반적으로 허용되는 규칙(예: 문자, 수학 기호 ∫, ≤, ⊆, ∞, 화학 원소 기호)에 의해 설정됩니다.
기호 시스템은 정보를 나타내는 데 사용됩니다. 언어. 모든 언어의 기본은 알파벳- 메시지가 형성되는 문자 집합과 문자에 대한 작업을 수행하기 위한 규칙 집합입니다.
언어는 다음과 같이 나뉩니다.
- 자연스러운(구어체) - 러시아어, 영어, 독일어 등
- 공식적인- 인간 활동의 특별한 영역(예: 대수학 언어, 프로그래밍 언어, 전기 회로등등)
숫자 체계는 공식 언어로도 볼 수 있습니다. 따라서 10진수 시스템은 알파벳이 0..9의 10자리 숫자로 구성된 언어이고 이진수 시스템은 알파벳이 0과 1의 두 자리 숫자로 구성된 언어입니다.
정보량 측정 방법: 확률 및 알파벳순
정보량을 측정하는 단위는 조금. 1비트무언가에 대한 지식의 불확실성을 절반으로 줄이는 메시지에 포함된 정보의 양입니다.
가능한 사건의 수 N과 정보의 양 I 사이의 관계는 다음과 같이 결정됩니다. 하틀리 공식:
예를 들어, 공이 네 개의 상자 중 하나에 있다고 가정합니다. 따라서 동일한 가능성이 있는 4개의 이벤트가 있습니다(N = 4). 그런 다음 Hartley의 공식에 의해 4 = 2 I . 따라서 I = 2입니다. 즉, 공이 있는 상자에 대한 메시지에는 2비트의 정보가 포함됩니다.
알파벳순 접근
정보의 양을 결정하기 위해 알파벳순으로 접근하면 정보의 내용(의미)에서 추상화하여 특정 기호 시스템의 기호 시퀀스로 간주합니다. 언어(알파벳)의 문자 집합은 가능한 다른 이벤트로 생각할 수 있습니다. 그런 다음 Hartley 공식을 사용하여 메시지에서 문자가 나타날 가능성이 동일하다고 가정하면 각 문자가 전달하는 정보의 양을 계산할 수 있습니다.
예를 들어, 러시아어에는 32개의 문자가 있습니다(문자 ё는 일반적으로 사용되지 않음). 즉, 이벤트 수는 32개입니다. 그러면 한 문자의 정보량은 다음과 같습니다.
I = 로그 2 32 = 5비트.
N이 2의 정수 거듭제곱이 아니면 log 2 N은 정수가 아니므로 반올림해야 합니다. 이 경우 문제를 풀 때 나는 log 2 N"로 찾을 수 있습니다. 여기서 N'은 N' > N이 되도록 N에 2의 가장 가까운 거듭제곱입니다.
예를 들어, 영어 26글자 한 심볼의 정보량은 다음과 같이 찾을 수 있습니다.
N = 26; N" = 32, I = 로그 2 N" = 로그 2(2 5) = 5비트.
알파벳 문자 수가 N이고 메시지 레코드의 문자 수가 M이면 이 메시지의 정보량은 다음 공식으로 계산됩니다.
나는 = M log 2 N.
문제 해결의 예
실시예 1라이트 보드는 전구로 구성되며 각 전구는 두 가지 상태("켜짐" 또는 "꺼짐") 중 하나일 수 있습니다. 50개의 다른 신호를 전송할 수 있도록 점수판에 있어야 하는 전구의 최소 개수는 얼마입니까?
해결책.각각 두 가지 상태 중 하나에 있을 수 있는 n개의 전구를 사용하여 2n개의 신호를 인코딩할 수 있습니다. 25< 50 < 2 6 , поэтому пяти лампочек недостаточно, а шести хватит.
대답: 6.
실시예 2기상 관측소는 공기 습도를 모니터링합니다. 한 번의 측정 결과는 0에서 100 사이의 정수이며 가능한 최소 비트 수를 사용하여 작성됩니다. 스테이션은 80개의 측정을 수행했습니다. 관찰 결과의 정보량을 결정합니다.
해결책.이 경우 알파벳은 0부터 100까지의 정수의 집합으로 총 101개의 값이 있으므로 1회 측정 결과의 정보량은 I = log 2 101입니다. 이 값은 정수가 아닙니다 . 숫자 101을 101보다 큰 2의 가장 가까운 거듭제곱으로 바꾸겠습니다. 이 숫자는 128 = 27입니다. 한 번의 측정으로 I = log 2 128 = 7비트를 사용합니다. 80회 측정의 경우 총 정보량은 다음과 같습니다.
80 7 = 560비트 = 70바이트.
대답: 70바이트.
확률적 접근
정보의 양을 측정하는 확률론적 접근은 가능한 사건이 실현 확률이 다를 때 사용됩니다. 이 경우 정보의 양이 결정됩니다. Shannon 공식에 따르면:
$I=-∑↙(i=1)↖(N)p_ilog_2p_i$,
여기서 $I$는 정보의 양입니다.
$N$는 가능한 이벤트의 수입니다.
$p_i$는 $i$번째 이벤트의 확률입니다.
예를 들어, 비대칭 사면체 피라미드를 던질 때 개별 이벤트의 확률은 동일합니다.
$p_1=(1)/(2), p_2=(1)/(4), p_3=(1)/(8), p_4=(1)/(8)$.
그런 다음 Shannon 공식을 사용하여 그 중 하나를 구현한 후 얻을 수 있는 정보의 양을 계산할 수 있습니다.
$I=-((1)/(2) log_2(1)/(2)+(1)/(4) log_2(1)/(4)+(1)/(8) log_2(1)/( 8)+(1)/(8) log_2(1)/(8))=(14)/(8)$ 비트 $= 1.75 $비트.
정보량을 측정하는 단위
정보의 가장 작은 단위는 조금(영어) 이진수(비트)정보의 이진 단위)입니다.
조금는 가능성이 동일한 두 이벤트 중 하나를 명확하게 결정하는 데 필요한 정보의 양입니다. 예를 들어, 어떤 사람은 자신이 필요로 하는 기차가 늦은지 아닌지, 밤에 서리가 내린 것인지, 학생 이바노프가 강의에 참석했는지 등을 알 때 1비트의 정보를 받습니다.
컴퓨터 과학에서는 길이가 8비트 시퀀스를 고려하는 것이 일반적입니다. 이와 같은 수열을 바이트.
정보의 양을 측정하기 위한 파생 단위:
1바이트 = 8비트
1킬로바이트(KB) = 1024바이트 = 2 10바이트
1메가바이트(MB) = 1024킬로바이트 = 220바이트
1기가바이트(GB) = 1024메가바이트 = 230바이트
1테라바이트(TB) = 1024기가바이트 = 240바이트
정보 전송 프로세스. 정보 소스 및 수신자의 유형 및 속성. 신호, 인코딩 및 디코딩, 전송 중 정보 왜곡의 원인
정보는 일부에서 메시지 형태로 전송됩니다. 원천그녀에게 정보 수화기~을 통해 커뮤니케이션 채널그들 사이에.
정보의 출처는 생명체 또는 기술 장치. 소스는 전송된 메시지를 전송하고 전송된 메시지로 인코딩됩니다. 신호.
신호정보 프레젠테이션의 물질 에너지 형태입니다. 다시 말해, 신호하나 이상의 매개변수를 변경하여 메시지를 표시하는 정보의 전달자입니다. 신호는 다음과 같습니다. 비슷한 물건(연속) 또는 이산(충동).
신호는 통신 채널을 통해 전송됩니다. 결과적으로 수신된 신호가 수신기에 나타나고 디코딩되어 수신된 메시지가 됩니다.
통신 채널을 통한 정보 전송은 종종 정보의 왜곡과 손실을 유발하는 간섭을 동반합니다.
문제 해결의 예
실시예 1문자 A, Z, R, O를 인코딩하기 위해 두 자리 이진수 00, 01, 10, 11이 각각 사용됩니다. 이런 식으로 단어 ROSE를 인코딩하고 결과를 16진수 코드로 작성했습니다. 결과 번호를 지정합니다.
해결책. ROSE라는 단어의 각 기호에 대한 코드 시퀀스를 기록해 보겠습니다. 10 11 01 00. 결과 시퀀스를 2진수로 간주하면 16진수 코드에서는 1011 0100 2 = B4 16이 됩니다.
대답: B4 16 .
정보 전송률 및 통신 채널 용량
정보의 수신/전송은 다음과 같이 발생할 수 있습니다. 다른 속도. 단위 시간당 전송되는 정보의 양은 정보 전송 속도, 또는 정보 흐름 속도.
속도는 초당 비트 수(bps)와 Kbps와 Mbps의 배수, 초당 바이트 수(bps)와 Kbps와 Mbps의 배수로 표시됩니다.
통신 채널을 통한 정보 전송의 최대 속도를 처리량채널.
문제 해결의 예
실시예 1 ADSL 연결을 통한 데이터 전송 속도는 256,000bps입니다. 다음을 통한 파일 전송 이 화합물 3분 걸렸다. 파일 크기를 킬로바이트 단위로 지정합니다.
해결책.파일 크기는 정보 전송 속도에 전송 시간을 곱하여 계산할 수 있습니다. 시간을 초로 표현해 봅시다: 3 min = 3 ⋅ 60 = 180 s. 속도를 초당 킬로바이트로 표현해 보겠습니다: 256000bps = 256000: 8: 1024KB/s. 파일 크기를 계산할 때 계산을 단순화하기 위해 2의 거듭제곱을 선택합니다.
파일 크기 = (256000:8:1024) ⋅ (3 ⋅ 60) = (2 8 ⋅ 10 3:2 3:2 10) ⋅ (3 ⋅ 15 ⋅ 2 2) = (2 8 ⋅ 125 ⋅ 2 3:2 3: 2 10) ⋅ (3 ⋅ 15 ⋅ 2 2) = 125 ⋅ 45 = 5625KB.
대답: 5625KB.
숫자 정보의 표현. 다른 숫자 체계의 덧셈과 곱셈
숫자 체계를 사용한 숫자 정보 표현
컴퓨터에서 정보를 나타내기 위해 이진 코드가 사용되며 그 알파벳은 0과 1의 두 자리로 구성됩니다. 기계 이진 코드의 각 자리는 1비트에 해당하는 정보량을 전달합니다.
표기법특정 숫자 집합을 사용하여 숫자를 쓰는 시스템입니다.
번호 체계는 위치, 동일한 숫자에 다른 값이 있는 경우 숫자에서의 해당 위치에 따라 결정됩니다.
위치는 십진수 시스템입니다. 예를 들어, 숫자 999에서 숫자 "9"는 위치에 따라 9, 90, 900을 의미합니다.
로마 숫자 체계는 위치가 아닌. 예를 들어, 숫자 XXI에서 숫자 X의 값은 숫자에서의 위치가 변할 때 변경되지 않은 상태로 유지됩니다.
숫자에서 숫자의 위치를 라고 합니다. 해고하다. 숫자의 자릿수는 오른쪽에서 왼쪽으로, 낮은 자리에서 높은 자리로 증가합니다.
위치 번호 시스템에서 사용되는 다른 자릿수를 그것의 기초.
숫자의 확장된 형태숫자의 자릿수와 위치 값의 곱의 합인 레코드입니다.
예: 8527 = 8 ⋅ 10 3 + 5 ⋅ 10 2 + 2 ⋅ 10 1 + 7 ⋅ 10 0 .
임의의 숫자 체계의 숫자 쓰기의 확장된 형태는 다음과 같은 형식을 갖습니다.
$∑↙(i=n-1)↖(-m)a_iq^i$,
여기서 $X$는 숫자입니다.
$a$ - 숫자에 해당하는 숫자 레코드의 숫자.
$i$ - 인덱스;
$m$는 소수 부분의 자릿수입니다.
$n$는 정수 부분의 숫자 자릿수입니다.
$q$는 숫자 체계의 기수입니다.
예를 들어, 십진수 $327.46$의 확장된 형식을 작성해 보겠습니다.
$n=3, m=2, q=10.$
$X=∑↙(i=2)↖(-2)a_iq^i=a_2 10^2+a_1 10^1+a_0 10^0+a_(-1) 10^(-1)+ a_(-2 ) 10^(-2)=3 10^2+2 10^1+7 10^0+4 10^(-1)+6 10^(-2)$
사용된 숫자 체계의 밑수가 10보다 크면 숫자에 대해 다음을 입력합니다. 상징상단에 대괄호 또는 문자 지정: B - 2진법, O - 8진법, H - 16진법.
예를 들어, 십진수 시스템 10 \u003d A 및 11 \u003d B에서 숫자 7A,5B 12는 다음과 같이 칠할 수 있습니다.
7A,5B 12 \u003d B ⋅ 12 -2 + 5 ⋅ 2 -1 + A ⋅ 12 0 + 7 ⋅ 12 1.
16진수 시스템에는 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F로 표시된 16자리 숫자가 있으며, 이는 다음 숫자에 해당합니다. 십진수 체계: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15. 숫자 예: 17D,ECH; F12AH.
위치 번호 시스템의 숫자 번역
임의의 숫자 체계에서 10진수로 숫자 변환
모든 위치 숫자 시스템에서 숫자를 10진수로 변환하려면 필요한 경우 문자 지정을 해당 숫자로 대체하여 확장된 숫자 형식을 사용해야 합니다. 예를 들어:
1101 2 = 1 ⋅ 2 3 + 1 ⋅ 2 2 + 0 ⋅ 2 1 + 1 ⋅ 2 0 = 13 10 ;
17D,ECH = 12 ⋅ 16 -2 + 14 ⋅ 16 -1 + 13 ⋅ 160 + 7 ⋅ 16 1 + 1 ⋅ 16 2 = 381.921875.
10진수 체계에서 주어진 숫자로 숫자 변환
정수를 십진수 체계에서 다른 숫자 체계의 숫자로 변환하려면 0이 얻어질 때까지 정수를 숫자 체계의 밑수로 연속적으로 나눕니다. 시스템 기준으로 나눗셈의 나머지로 나타나는 숫자는 최하위 자릿수에서 최상위 자릿수까지 선택한 숫자 체계의 숫자 자릿수를 순차적으로 기록한 것입니다. 따라서 숫자 자체를 쓰려면 나눗셈의 나머지를 역순으로 씁니다.
예를 들어 번역하자면 십진수 475를 이진수 시스템으로 변환합니다. 이를 위해 우리는 기저에 의한 정수 나눗셈을 순차적으로 수행할 것입니다. 새로운 시스템미적분, 즉 2:
나눗셈의 나머지를 아래에서 위로 읽으면 111011011이 됩니다.
시험:
1 ⋅ 2 8 + 1 ⋅ 2 7 + 1 ⋅ 2 6 + 0 ⋅ 2 5 + 1 ⋅ 2 4 + 1 ⋅ 2 3 + 0 ⋅ 2 2 + 1 ⋅ 2 1 + 1 ⋅ 2 0 = 1 + 2 + 8 + 16 + 64 + 128 + 256 = 475 10 .
소수를 임의의 숫자 체계의 숫자로 변환하려면 숫자 체계의 밑수를 순서대로 곱합니다. 분수 부분제품은 0이 아닙니다. 얻은 정수 부분은 새 시스템의 숫자 자릿수이며 이 새 숫자 시스템의 자릿수로 표시되어야 합니다. 전체 부품은 이후에 폐기됩니다.
예를 들어, 소수점 이하 자릿수 0.375 10을 이진수 시스템으로 변환해 보겠습니다.

얻어진 결과는 0.011 2 입니다.
모든 숫자가 새 숫자 체계에서 정확하게 표현될 수 있는 것은 아니므로 필요한 소수 자릿수만 계산되는 경우가 있습니다.
숫자를 2진수에서 8진수 및 16진수로 또는 그 반대로 변환
8자리는 8진수를 쓰는 데 사용됩니다. 즉, 숫자의 각 자리에 8개의 녹음 옵션이 가능합니다. 8진수의 각 비트는 3비트의 정보를 포함합니다(8 = 2 І, І = 3).
따라서 8진수 시스템에서 2진 코드로 숫자를 변환하려면 이 숫자의 각 자릿수를 2진 문자의 트라이어드로 표시해야 합니다. 상위 비트의 추가 0은 버려집니다.
예를 들어:
1234,777 8 = 001 010 011 100,111 111 111 2 = 1 010 011 100,111 111 111 2 ;
1234567 8 = 001 010 011 100 101 110 111 2 = 1 010 011 100 101 110 111 2 .
이진수를 8진수 시스템으로 변환할 때 이진수의 각 트라이어드를 8진수로 바꿔야 합니다. 이 경우 필요한 경우 정수 부분 앞이나 소수 부분 뒤에 0을 추가하여 숫자를 정렬합니다.
예를 들어:
1100111 2 = 001 100 111 2 = 147 8 ;
11,1001 2 = 011,100 100 2 = 3,44 8 ;
110,0111 2 = 110,011 100 2 = 6,34 8 .
16진수는 16진수를 작성하는 데 사용됩니다. 즉, 숫자의 각 자릿수에 대해 16개의 표기 옵션이 가능합니다. 16진수의 각 비트는 4비트의 정보를 포함합니다(16 = 2 І ; І = 4).
따라서 2진수를 16진수로 변환하려면 4자리 그룹으로 나누고 각 그룹을 16진수로 변환해야 합니다.
예를 들어:
1100111 2 = 0110 0111 2 = 67 16 ;
11,1001 2 = 0011,1001 2 = 3,9 16 ;
110,0111001 2 = 0110,0111 0010 2 = 65,72 16 .
16진법 숫자를 2진법 코드로 변환하려면 이 숫자의 각 자릿수를 4개의 2진법 숫자로 나타내야 합니다.
예를 들어:
1234,AB77 16 = 0001 0010 0011 0100.1010 1011 0111 0111 2 = 1 0010 0011 0100.1010 1011 0111 0111 2;
CE4567 16 = 1100 1110 0100 0101 0110 0111 2 .
임의의 숫자 체계에서 다른 숫자 체계로 숫자를 변환할 때 10진수로 중간 변환을 수행해야 합니다. 8진수에서 16진수로 또는 그 반대로 변환할 때 숫자의 보조 이진 코드가 사용됩니다.
예를 들어, 3진수 211 3을 7진수 시스템으로 변환해 보겠습니다. 이를 위해 먼저 숫자 211 3을 10진수로 변환하여 확장된 형식을 작성합니다.
211 3 = 2 ⋅ 3 2 + 1 ⋅ 3 1 + 1 ⋅ 3 0 = 18 + 3 + 1 = 22 10 .
그런 다음 십진수 22 10을 새로운 숫자 체계의 밑수, 즉 7로 완전히 나누어 70진수 체계로 변환합니다.
따라서 211 3 = 31 7 입니다.
문제 해결의 예
실시예 1일부 밑수가 있는 숫자 체계에서 숫자 12는 110으로 기록됩니다. 이 밑수를 표시하십시오.
해결책.원하는 밑수 n을 지정합시다. 위치 수 체계에서 숫자 쓰기 규칙 12 10 = 110 n = 0 ·n 0 + 1 · n 1 + 1 · n 2 . 방정식을 만들어 봅시다 : n 2 + n \u003d 12. 방정식의 자연근을 찾자(수 체계의 밑은 정의에 따라 1보다 큰 자연수이기 때문에 음수 근은 적합하지 않음): n = 3. 답을 확인해 봅시다: 110 3 = 0 3 0 + 1 3 1 + 1 3 2 = 0 + 3 + 9 = 12 .
대답: 3.
실시예 2숫자 22의 입력이 4로 끝나는 숫자 체계의 모든 밑수를 쉼표로 구분하여 오름차순으로 표시하십시오.
해결책.숫자의 마지막 숫자는 숫자를 숫자 체계의 밑수로 나눈 나머지입니다. 22 - 4 \u003d 18. 숫자 18의 제수를 찾으십시오. 이것은 숫자 2, 3, 6, 9, 18입니다. 숫자 2와 3은 적합하지 않습니다. 숫자 4가 아닙니다. 따라서 원하는 기수는 숫자 6, 9 및 18입니다. 표시된 숫자 체계(22 10 \u003d 34 6 \u003d 24 9 \u003d 14 18)에 숫자 22를 작성하여 결과를 확인해 보겠습니다.
대답: 6, 9, 18.
실시예 3 25를 초과하지 않는 모든 숫자를 쉼표로 구분하여 오름차순으로 표시하십시오. 이진법에서 101로 끝나는 숫자를 입력하십시오. 답을 십진수 체계로 쓰십시오.
해결책.편의상 8진수 시스템을 사용합니다. 101 2 = 5 8 . 그런 다음 숫자 x는 x \u003d 5 8 0 + a 1 8 1 + a 2 8 2 + a 3 8 3 + ...로 나타낼 수 있습니다. 여기서 a 1, a 2, a 3, ...는 8진수입니다. . 원하는 숫자는 25를 초과하지 않아야 하므로 확장은 처음 두 항(8 2 > 25)으로 제한되어야 합니다. 즉, 이러한 숫자는 표현 x = 5 + a 1 8이어야 합니다. x ≤ 25이므로, 유효한 값 a 1은 0, 1, 2가 됩니다. 이 값을 x에 대한 표현식에 대입하면 원하는 숫자를 얻을 수 있습니다.
a1 = 0; x = 5 + 0 8 = 5;.
1 = 1; x = 5 + 1 8 = 13;.
1 = 2; x = 5 + 2 8 = 21;.
점검 해보자:
13 10 = 1101 2 ;
21 10 = 10101 2 .
대답: 5, 13, 21.
위치 숫자 시스템의 산술 연산
이진수에 대한 산술 연산을 수행하기 위한 규칙은 덧셈, 뺄셈 및 곱셈 테이블에 의해 제공됩니다.
더하기 연산을 수행하는 규칙은 모든 숫자 체계에 대해 동일합니다. 추가된 숫자의 합이 숫자 체계의 밑수보다 크거나 같으면 단위가 왼쪽의 다음 숫자로 전송됩니다. 뺄 때 필요한 경우 대출을하십시오.
실행 예 추가: 이진수 111과 101, 10101과 1111을 더합니다.

실행 예 빼기:이진수 10001 - 101 및 11011 - 1101을 뺍니다.

실행 예 곱셈:이진수 110과 11, 111과 101을 곱합니다.

유사하게, 산술 연산은 8진수, 16진수 및 기타 숫자 체계에서 수행됩니다. 이 경우 뺄셈 시 가장 높은 자릿수에서 더하고 빌릴 때 다음 자릿수로 이전하는 금액은 숫자 체계의 밑수 값에 따라 결정된다는 점을 고려해야 합니다.
예를 들어, 8진수 368과 158을 더하고 16진수 9C16과 6716을 뺍니다.

하면서 산술 연산에 제시된 숫자보다 다른 시스템미적분학, 먼저 동일한 시스템으로 번역해야 합니다.
컴퓨터에서 숫자 표현
고정 소수점 형식
컴퓨터 메모리에서 정수는 형식으로 저장됩니다. 고정 소수점: 메모리 셀의 각 숫자는 숫자의 동일한 숫자에 해당하며 "쉼표"는 비트 그리드 외부에 있습니다.
음이 아닌 정수를 저장하기 위해 8비트의 메모리가 할당됩니다. 최소 수는 메모리 셀의 8비트에 저장된 8개의 0에 해당하고 0과 같습니다. 최대 수는 8개의 1에 해당하고 다음과 같습니다.
1 ⋅ 2 7 + 1 ⋅ 2 6 + 1 ⋅ 2 5 + 1 ⋅ 2 4 + 1 ⋅ 2 3 + 1 ⋅ 2 2 + 1 ⋅ 2 1 + 1 ⋅ 2 0 = 255 10 .
따라서 음이 아닌 정수의 범위는 0에서 255까지입니다.
n비트 표현의 경우 범위는 0에서 2n - 1입니다.
부호 있는 정수는 2바이트(16비트)에 저장됩니다. 최상위 비트는 숫자의 부호에 할당됩니다. 숫자가 양수이면 0이 부호 비트에 기록되고 숫자가 음수이면 - 1입니다. 컴퓨터에서 이러한 숫자 표현은 직접 코드.
음수를 나타내는 데 사용 추가 코드. 뺄셈의 산술 연산을 덧셈 연산으로 대체하여 프로세서 작업을 크게 단순화하고 속도를 높일 수 있습니다. n개의 셀에 저장된 음수 A의 상보 코드는 2 n − |A|입니다.
음수의 추가 코드를 얻는 알고리즘:
1. 숫자의 직접 코드를 n개의 이진수로 기록합니다.
2. 가져오기 반환 번호 코드. (역방향 부호는 부호 비트의 자릿수를 제외하고는 0을 1로, 1을 0으로 치환하여 직접 부호로 구성됩니다. 양수의 경우 역 부호는 직접 부호와 동일합니다. 추가 코드를 얻기 위한 중간 링크.)
3. 수신된 리턴 코드에 하나를 추가하십시오.
예를 들어, 16비트 표현에 대해 2의 보수 코드 -2014 10을 얻습니다.
대수적 덧셈으로 이진수보완 코드를 사용하여 긍정적인 용어는 직접 코드에 표시되고 부정적인 용어는 보완 코드에 표시됩니다. 그런 다음 상위 비트로 처리되는 부호 비트를 포함하여 이러한 코드가 합산됩니다. 부호 비트에서 전송할 때 전송 단위는 폐기됩니다. 결과적으로, 이 합계가 양수이면 직접 코드에서 대수적 합계를 얻고 합계가 음수이면 추가 코드에서 얻습니다.
예를 들어:
1) 8비트 표현에 대한 차이 13 10 - 12 10을 찾으십시오. 주어진 숫자를 이진법으로 나타내자:
13 10 = 1101 2 및 12 10 = 1100 2 .
숫자 -12 10에 대한 직접, 역방향 및 추가 코드를 8비트로 작성하고 숫자 13 10에 대한 직접 코드를 작성해 보겠습니다.
빼기를 덧셈으로 바꿀 것입니다(부호 비트를 제어하기 쉽도록 "_" 기호로 조건부로 구분합니다).

부호 비트에서 전송이 있었기 때문에 첫 번째 단위를 버리고 결과적으로 00000001을 얻습니다.
2) 8비트 표현에 대한 차이 8 10 - 13 10을 찾으십시오.
숫자 -13 10에 대한 직접, 역방향 및 추가 코드와 숫자 8 10에 대한 직접 코드를 8비트로 작성해 보겠습니다.
뺄셈을 덧셈으로 바꿉니다.

부호 비트에 하나가 있는데, 이는 결과가 추가 코드에서 얻어짐을 의미합니다. 추가 코드에서 반대 코드로 이동하여 1을 뺍니다.
11111011 - 00000001 = 11111010.
부터 계속하자 반환 코드부호(최상위) 자릿수: 10000101을 제외한 모든 자릿수를 반전하여 지시합니다. 이것은 십진수 -5 10 입니다.
추가 코드에서 음수 A의 n비트 표현에서 최상위 비트는 숫자의 부호를 저장하기 위해 할당되므로 최소 음수는 A = -2 n-1이고 최대값은 | 에이| = 2 n-1 또는 A = -2 n-1 - 1.
저장할 수 있는 숫자의 범위를 정의합니다. 랜덤 액세스 메모리형식으로 부호 있는 긴 정수(이러한 숫자를 저장하기 위해 32비트의 메모리가 할당됩니다). 최소 음수는
A \u003d -2 31 \u003d -2147483648 10.
최대 양수는
A \u003d 2 31-1 \u003d 2147483647 10.
고정 소수점 형식의 장점은 숫자 표현의 단순성과 명확성, 산술 연산 구현을 위한 알고리즘의 단순성입니다. 단점은 표현 가능한 숫자의 범위가 작아 대부분의 응용 문제를 해결하기에 충분하지 않다는 것입니다.
부동 소수점 형식
실수는 다음과 같은 형식으로 컴퓨터에 저장되고 처리됩니다. 부동 소수점, 숫자의 지수 표기법을 사용합니다.
지수 형식의 숫자는 다음과 같이 표시됩니다.
여기서 $m$는 숫자의 가수(0이 아닌 적절한 분수)입니다.
$q$는 숫자 체계의 기본입니다.
$n$는 숫자의 순서입니다.
예를 들어 지수 형식의 십진수 2674.381은 다음과 같이 작성됩니다.
2674,381 = 0,2674381 ⋅ 10 4 .
부동 소수점 숫자는 메모리에서 4바이트를 차지할 수 있습니다( 기존 정확도) 또는 8바이트( 배정밀도). 숫자를 쓸 때 가수의 부호, 지수의 부호, 지수, 가수를 저장하기 위해 비트가 할당된다. 마지막 두 값은 숫자의 범위와 정확도를 결정합니다.
일반 정밀도 숫자, 즉 4바이트 형식의 범위(순서)와 정밀도(가수)를 정의해 보겠습니다. 32비트 중 8비트는 지수와 부호를 저장하기 위해 할당되고 24비트는 가수와 부호를 저장하기 위해 할당된다.
수의 차수의 최대값을 구합시다. 8비트 중 최상위 비트는 순서의 부호를 저장하는 데 사용되고 나머지 7개는 순서 값을 기록하는 데 사용됩니다. 따라서 최대값은 1111111 2 = 127 10 입니다. 숫자는 이진 표기법으로 표현되기 때문에,
$q^n = 2^(127)≈ 1.7 10^(38)$.
마찬가지로 가수의 최대값은
$m = 2^(23) - 1 ≈ 2^(23) = 2^((10 2.3)) ≈ 1000^(2.3) = 10^((3 2.3)) ≈ 10^7$.
따라서 일반 정밀도 숫자의 범위는 $±1.7 · 10^(38)$입니다.
텍스트 정보의 인코딩. ASCII 인코딩. 주로 사용되는 키릴 문자 인코딩
문자 집합과 숫자 값 집합 사이의 대응을 호출합니다. 문자 인코딩.텍스트 정보가 컴퓨터에 입력되면 바이너리로 인코딩됩니다. 문자 코드는 컴퓨터의 RAM에 저장됩니다. 화면에 문자를 표시하는 과정에서 역동작이 수행됩니다 - 디코딩즉, 문자 코드를 이미지로 변환하는 것입니다.
각 문자에 할당된 특정 숫자 코드는 코드 테이블오. 다른 코드 테이블의 동일한 문자는 다른 숫자 코드에 대응할 수 있습니다. 필요한 텍스트 변환은 일반적으로 대부분의 응용 프로그램에 내장된 특수 변환기 프로그램에 의해 수행됩니다.
일반적으로 1바이트(8비트)는 문자 코드를 저장하는 데 사용되므로 문자 코드는 0에서 255 사이의 값을 가질 수 있습니다. 이러한 인코딩을 싱글바이트. 256자(N = 2 I = 2 8 = 256)를 허용합니다. 1바이트 문자 코드 테이블을 호출합니다. ASCII(정보 교환을 위한 미국 표준 코드)— 정보 교환을 위한 미국 표준 코드). ASCII 코드 테이블의 첫 번째 부분(0~127)은 모든 IBM-PC 호환 컴퓨터에서 동일하며 다음을 포함합니다.
- 제어 문자 코드;
- 숫자 코드, 산술 연산, 구두점;
- 약간 특수 기호;
- 크고 작은 라틴 문자 코드.
표의 두 번째 부분(128에서 255 사이의 코드)은 다양한 컴퓨터. 그것은 국가 알파벳 문자 코드, 일부 수학 기호 코드, 의사 그래픽 기호 코드를 포함합니다. 러시아 문자의 경우 현재 5가지 다른 코드 테이블이 사용됩니다. KOI-8, SR1251, SR866, Mac, ISO.
최근 새로운 국제 표준이 널리 보급되었습니다. 유니코드. 각 문자를 인코딩하는 데 2바이트(16비트)가 있으므로 65536개의 다른 문자(N = 2 16 = 65536)를 인코딩할 수 있습니다. 문자 코드는 0에서 65535 사이의 값을 가질 수 있습니다.
문제 해결의 예
예시.다음 문구는 유니코드 인코딩을 사용하여 인코딩됩니다.
나는 대학에 가고 싶다!
이 문구의 정보 내용을 평가하십시오.
해결책.이 구문은 31자(공백 및 구두점 포함)를 포함합니다. 유니코드는 문자당 2바이트의 메모리를 인코딩하기 때문에 전체 구문에는 31 ⋅ 2 = 62바이트 또는 31 ⋅ 2 ⋅ 8 = 496비트가 필요합니다.
대답: 32바이트 또는 496비트.