Sooner or later (better, of course, if early), any user asks himself the question of how long the installed on him computer hard drive and is it time to look for a replacement for it. There is nothing surprising in this, since hard drives, by virtue of their design features are the least reliable among computer components. At the same time, it is on the HDD that most users store the lion's share of the most diverse information: documents, pictures, various software, etc., as a result of which an unexpected disk failure is always a tragedy. Of course, it is often possible to recover information on externally “dead” hard drives, but it is possible that this operation will cost you a pretty penny, and it will cost you a lot of nerves. Therefore, it is much more effective to try to prevent data loss.
How? Very simple ... First, do not forget about the regular backup data, and secondly, monitor the status of disks using specialized utilities. We will consider several programs of such a plan in terms of the tasks to be solved in this article.
Control of SMART parameters and temperature
All modern HDDs and even solid state drives (SSDs) support S.M.A.R.T. ( from English. Self-Monitoring, Analysis, and Reporting Technology - technology of self-monitoring, analysis and reporting), which was developed by major manufacturers hard drives to improve the reliability of their products. This technology is based on continuous monitoring and assessment of the state of the hard drive by the built-in self-diagnostic equipment (special sensors), and its main purpose is the timely detection of a possible drive failure.
HDD status monitoring in real time
A number of information and diagnostic solutions for hardware diagnostics and testing, as well as special monitoring utilities, use S.M.A.R.T. to monitor the current state of various vital important parameters describing the reliability and performance of hard drives. They read the relevant parameters directly from the sensors and thermal sensors that all modern hard drives are equipped with, analyze the received data and display them in the form of a brief tabular report with a list of attributes. At the same time, some of the utilities (Hard Drive Inspector, HDDlife, Crystal Disk Info, etc.) are not limited to displaying a table of attributes (the values of which are incomprehensible to unprepared users) and additionally display brief information about the state of the disk in a more understandable form.
Diagnosing the condition of a hard drive using this kind of utilities is as easy as shelling pears - just get acquainted with brief basic information about installed HDDs: with basic data about disks in Hard Drive Inspector, a certain conditional percentage of hard disk health in HDDlife, the "Technical condition" indicator in Crystal Disk Info ( Fig. 1), etc. Any of these programs provides the minimum necessary information about each of the HDDs installed on the computer: data on the hard drive model, its volume, operating temperature, hours worked, as well as the level of reliability and performance. This information makes it possible to draw certain conclusions about the performance of the media.
Rice. 1. Brief information about the "health" of the working HDD
You should configure the launch of the monitoring utility at the same time as the operating system starts, adjust the time interval between checks of S.M.A.R.T. attributes, and enable display of the temperature and “health level” of hard drives in the system tray. After that, to control the status of disks, the user will only need to glance at the indicator in the system tray from time to time, where it will be displayed short information about the state of the drives available in the system: their level of "health" and temperature (Fig. 2). By the way, the operating temperature is no less important indicator than the conditional indicator of HDD health, because hard drives can suddenly fail due to banal overheating. Therefore, if the hard drive heats up above 50 ° C, then it would be wiser to provide it with additional cooling.
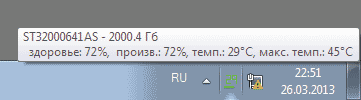
Rice. 2. HDD status display
in the system tray with the HDDlife program
It should be noted that some of these utilities provide integration with Windows Explorer, so that local disk icons display a green icon if they are healthy, and the icon turns red if problems occur. So you are unlikely to be able to forget about the health of your hard drives. With such constant monitoring, you will not be able to miss the moment when some problems begin to arise with the disk, because if the utility detects critical changes in the S.M.A.R.T. and / or temperature, it will carefully notify the user about this (by a message on the screen, a sound message, etc. - Fig. 3). Thanks to this, it will be possible to have time to copy the data from the medium that inspires fear in advance.

Rice. 3. An example of a message about the need to immediately replace the disk
It is absolutely not burdensome to use S.M.A.R.T.
Control of S.M.A.R.T. attributes
Advanced users, of course, are unlikely to limit themselves to assessing the state of hard drives by viewing a brief verdict of one of the utilities presented above. It is understandable, because by decoding the attributes of S.M.A.R.T. it is possible to identify the cause of failures and, if necessary, prudently take some additional measures. True, to independently control S.M.A.R.T. attributes, you will need to at least briefly familiarize yourself with the S.M.A.R.T.
HDDs that support this technology include intelligent self-diagnosis routines so they can "report" their current status. This diagnostic information is provided as a collection of attributes, i.e. specific hard drive characteristics used to analyze its performance and reliability.
B about Most of the important attributes have the same meaning for drives from all manufacturers. The values of these attributes during normal disk operation may vary within certain intervals. For any parameter, the manufacturer has defined a certain minimum safe value that cannot be exceeded under normal operating conditions. Unambiguously determine critical and non-critical S.M.A.R.T parameters for diagnostics. problematic. Each of the attributes has its own informational value and indicates one or another aspect in the work of the carrier. However, first of all, you should pay attention to the following attributes:
- Raw Read Error Rate - frequency of errors in reading data from the disk due to the fault of the equipment;
- Spin Up Time - average spin up time of the disk spindle;
- Reallocated Sector Count - number of sector remapping operations;
- Seek Error Rate - frequency of occurrence of positioning errors;
- Spin Retry Count - the number of retries to spin up disks to operating speed if the first attempt fails;
- Current Pending Sector Count - the number of unstable sectors (that is, sectors waiting for the remapping procedure);
- Offline Scan Uncorrectable Count - total number of uncorrected errors during sector read/write operations.
Typically, S.M.A.R.T. are displayed in a tabular form with the attribute name (Attribute), its identifier (ID) and three values: current (Value), minimum threshold (Threshold), and the lowest value of the attribute for the entire time of the drive (Worst), as well as the absolute value of the attribute (raw). Each attribute has a current value, which can be any number between 1 and 100, 200, or 253 (there is no general standard for upper bounds on attribute values). The Value and Worst values for a completely new hard drive are the same (Fig. 4).

Rice. 4. Attributes of S.M.A.R.T. on the new HDD
Shown in fig. 4 information allows us to conclude that for a theoretically sound hard drive, the current (Value) and worst (Worst) values should be as close as possible to each other, and the Raw value for most parameters (with the exception of the parameters: Power-On Time, HDA Temperature and some others ) should be close to zero. The current value may change over time, which in most cases reflects deterioration hard drive described by the attribute. This can be seen in fig. 5, which shows fragments of the S.M.A.R.T attribute table. for the same disk - the data are received with an interval of half a year. As you can see, in a more recent version of S.M.A.R.T. increased error rate when reading data from the disk (Raw Read Error Rate), the origin of which is due to the hardware of the disk, and the error rate when positioning the block of magnetic heads (Seek Error Rate), which may indicate overheating of the hard drive and its unstable position in the basket . If the current value of any attribute approaches or becomes less than the threshold, then the hard drive is considered unreliable, and it should be urgently replaced. For example, a drop in the value of the Spin-Up Time attribute (the average spin-up time of the disk spindle) below a critical value, as a rule, indicates complete wear of the mechanics, as a result of which the disk is no longer able to maintain the rotation speed specified by the manufacturer. Therefore, it is necessary to monitor the state of the HDD and periodically (for example, once every 2-3 months) carry out S.M.A.R.T. and save the received information in a text file. In the future, these data can be compared with the current ones and certain conclusions can be drawn about the development of the situation.

Rice. 5. S.M.A.R.T. Attribute Tables Obtained at Semi-Annual Intervals
(more recent version of S.M.A.R.T. below)
When viewing S.M.A.R.T. attributes, first of all, you should pay attention to critical parameters, as well as to parameters highlighted with indicators other than the base color (usually blue or green). Depending on the current state of the attribute in the S.M.A.R.T. in the table, it is usually marked in one color or another, which makes it easier to understand the situation. In particular, in the Hard Drive Inspector program, the color indicator can be green, yellow-green, yellow, orange or red - green and yellow-green colors indicate that everything is fine (the attribute value did not change or changed insignificantly), and yellow, orange and red colors signal danger (worst of all is red, which indicates that the value of the attribute has reached its critical value). If any of the critical parameters is marked with a red icon, then you need to urgently replace the hard drive.
Let's look at the table of S.M.A.R.T. attributes of the same disk in the Hard Drive Inspector program, a brief assessment of which by monitoring utilities was given earlier. From fig. 6 shows that the values of all attributes are normal and all parameters are marked in green. The HDDlife and Crystal Disk Info utilities will show a similar picture. True, more professional solutions for HDD analysis and diagnostics are not so loyal and often label S.M.A.R.T. attributes more meticulously. For example, such well-known utilities as HD Tune Pro and HDD Scan, in our case, were suspicious of the UltraDMA CRC Errors attribute, which displays the number of errors that occur when information is transmitted via the external interface (Fig. 7). The cause of such errors is usually associated with a twisted and poor-quality SATA cable, which may need to be replaced.

Rice. 6. Table of S.M.A.R.T. attributes obtained in the Hard Drive Inspector program

Rice. 7. Results of assessing the state of S.M.A.R.T. attributes
HD Tune Pro and HDD Scan utilities
For comparison, let's get acquainted with the S.M.A.R.T. attributes of a very ancient, but still working HDD with intermittent problems. He did not inspire confidence in the Crystal Disk Info program - in the “Technical Condition” indicator, the state of the disk was rated as alarming, and the Reallocated Sector Count attribute (Reassigned sectors) turned out to be highlighted in yellow (Fig. 8). This is a very important attribute from the point of view of the "health" of the disk, indicating the number of sectors remapped when the disk detects a read / write error, during this operation, data from the bad sector is transferred to the spare area. The yellow color of the indicator next to the parameter indicates that there are not enough remaining spare sectors with which to replace the bad ones, and soon there will be nothing to reassign the newly emerging bad sectors. Let's also check how more serious solutions evaluate the state of a disk, for example, the HDDScan utility widely used by professionals - but here we see exactly the same result (Fig. 9).

Rice. 8. Evaluate a problematic hard drive in CrystalDiskInfo

Rice. 9. Results of HDD S.M.A.R.T. diagnostics in HDDScan
This means that it is obviously not worth pulling with the replacement of such a hard drive, although it can still serve for some time, although, of course, you cannot install the operating system on this hard drive. It should be noted that if there a large number reassigned sectors, the read / write speed drops (due to unnecessary movements that the magnetic head has to make), and the disk starts to noticeably slow down.
Surface scanning for bad sectors
Unfortunately, in practice, one control of SMART parameters and temperature is not enough. When there is the slightest evidence that something is wrong with the disk (in the case of periodic program freezes, for example, when saving results, reading error messages, etc.), you need to scan the disk surface for unreadable sectors. To carry out such a check of the media, you can use, for example, the HD Tune Pro and HDDScan utilities or diagnostic utilities from hard drive manufacturers, however, these utilities only work with their hard drive models, and therefore we will not consider them.
When using such solutions, there is a risk of data corruption on the scanned disk. On the one hand, with the information on the disk, if the drive really turns out to be faulty, anything can happen during the scan. On the other hand, it is impossible to exclude incorrect actions on the part of the user, who mistakenly starts scanning in write mode, during which sector-by-sector overwriting of data from the hard drive with a certain signature occurs, and based on the speed of this process, a conclusion is made about the state of the hard disk. Therefore, compliance with certain precautionary rules is absolutely necessary: before starting the utility, you need to create a backup copy of the information and, during the check, act strictly according to the instructions of the developer of the corresponding software. To get more accurate results before scanning, it is better to close all active applications and unload possible background processes. In addition, it should be borne in mind that if you need to test the system HDD, you need to boot from a flash drive and start the scanning process from it, or completely remove the hard drive and connect it to another computer from which to start testing the disk.
As an example, using HD Tune Pro, we will check the surface of the HDD for bad sectors, which above did not inspire confidence in the Crystal Disk Info utility. In this program, to start the scanning process, just select the desired disk, activate the tab error scan and click on the button start. After that, the utility will start sequentially scanning the disk, reading sector by sector and marking sectors on the disk map with multi-colored squares. The color of the squares, depending on the situation, can be green (normal sectors) or red (bad blocks), or it will have some shade intermediate between these colors. As we see from fig. 10, in our case, the utility did not find full-fledged bad blocks, but nevertheless, there is a solid number of sectors with one or another read delay (judging by their color). In addition to this, in the middle part of the disk there is a small block of sectors, the color of which is close to red - these sectors have not yet been recognized as bad by the utility, but they are already close to it and will go into the category of bad ones in the very near future.
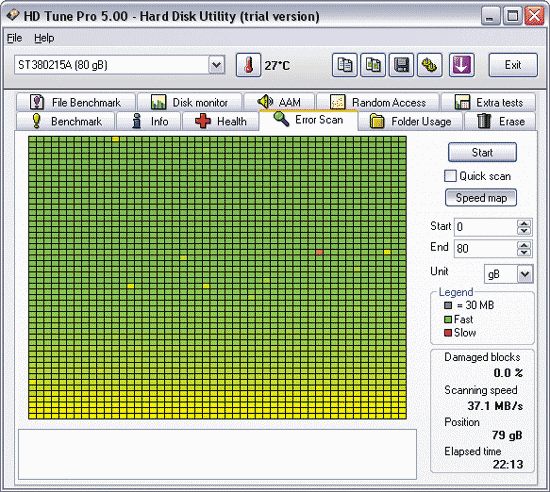
Rice. 10. Scanning the surface for bad sectors in HD Tune Pro
Testing the media for bad sectors in the HDDScan program is more difficult, and even more dangerous, because in the case of an incorrectly selected mode, the information on the disk will be irretrievably lost. First of all, to start scanning, create a new task by clicking on the button New Task and selecting the command from the list Suface Tests. Then you need to make sure that the mode is selected read- this mode is set by default and when it is used, the hard disk surface is tested by reading (that is, without deleting data). After that press the button Add test(Fig. 11) and double click on the created task RD Read. Now in the window that opens, you can observe the process of scanning the disk on the graph (Graph) or on the map (Map) - fig. 12. Upon completion of the process, we will get approximately the same results that were demonstrated above by the HD Tune Pro utility, but with a clearer interpretation: there are no bad sectors (they are marked in blue), but there are three sectors with a response time of more than 500 ms (marked in red color), which represent a real danger. As for the six orange sectors (response time from 150 to 500 ms), this can be considered within the normal range, since such a response delay is often caused by temporary interference in the form of, for example, running background programs.

Rice. 11. Run a disk test in HDDScan

Rice. 12. Results of scanning a disk in Read mode using HDDScan
In addition, it should be noted that if there are a small number of bad blocks, you can try to improve the condition of the hard disk by removing bad sectors by scanning the disk surface in linear recording mode (Erase) using the HDDScan program. After such an operation, the disk can still be used for some time, but, of course, not as a system disk. However, one should not hope for a miracle, since the HDD has already begun to crumble, and there are no guarantees that in the near future the number of defects will not increase and the drive will not completely fail.
Programs for S.M.A.R.T.-monitoring and HDD testing
HD Tune Pro 5.00 and HD Tune 2.55
Developer: EFD Software
Distribution size: HD Tune Pro - 1.5 MB; HD Tune - 628 KB
Work under control: Windows XP/Server 2003/Vista/7
Distribution method: HD Tune Pro - shareware (15 day demo); HD Tune - freeware (http://www.hdtune.com/download.html)
Price: HD Tune Pro - $34.95; HD Tune - free (for non-commercial use only)
HD Tune is a handy utility for diagnosing and testing HDD/SSD (see table), as well as memory cards, USB drives and a number of other storage devices. The program displays detailed information about the drive (firmware version, serial number, disk size, buffer size and data transfer mode) and allows you to set the device status using S.M.A.R.T data. and temperature monitoring. In addition, it can be used to test the disk surface for errors and evaluate the performance of the device by running a series of tests (sequential and random read / write speed tests, file performance test, cache test and a number of Extra tests). Also, the utility can be used to set up AAM and securely delete data. The program is presented in two editions: commercial HD Tune Pro and free lightweight HD Tune. In the HD Tune edition, only viewing detailed information about the disk and the S.M.A.R.T. attribute table is available, as well as scanning the disk for errors and testing for speed in read mode (Low level benchmark - read).
The Health tab is responsible for monitoring S.M.A.R.T. attributes in the program - data is read from the sensors after a set period of time, the results are displayed in the table. For any attribute, you can view the history of its changes in numerical form and on a graph. Monitoring data is automatically logged, but no user notifications are provided for critical parameter changes.
As for scanning the disk surface for bad sectors, the tab is responsible for this operation. error Scan. Scanning can be fast (Quick scan) and deep - with quick check not the entire disk is scanned, but only some part of it (the scan area is determined through the Start and End fields). Bad sectors are displayed on the disk map as red blocks.
HDDScan 3.3
Developer: Artem Rubtsov
Distribution size: 3.64 MB
Work under control: Windows 2000(SP4)/XP(SP2/SP3)/Server 2003/Vista/7
Distribution method: freeware (http://hddscan.com/download/HDDScan-3.3.zip)
Price: is free
HDDScan is a utility for low-level diagnostics of hard drives, solid state drives and Flash drives with USB interface. The main purpose of this program is to test disks for bad blocks and bad sectors. Also, the utility can be used to view the contents of S.M.A.R.T., monitor temperature and change some hard drive settings: noise management (AAM), power management (APM), forced start / stop of the drive spindle, etc. The program works without installation and can be launched from portable media, like flash drives.
Display of S.M.A.R.T. attributes and temperature monitoring in HDDScan is done on demand. S.M.A.R.T. report contains information about the performance and "health" of the drive in the form of a standard attribute table, the temperature of the drive is displayed in the system tray and in a special information window. Reports can be printed or saved as an MHT file. S.M.A.R.T. tests are possible.
Checking the disk surface is performed in one of four modes: Verify (linear verification mode), Read (linear reading), Erase (linear writing) and Butterfly Read (Butterfly reading mode). To check the disk for the presence of bad blocks, a test in Read mode is usually used, with the help of which the surface is tested without deleting data (a conclusion about the state of the drive is made based on the speed of sector-by-sector data reading). When testing in the linear recording mode (Erase), the information on the disk is overwritten, but this test can somewhat heal the disk, ridding it of bad sectors. In any of the modes, you can test the entire disk or a certain fragment of it (the scanning area is determined by specifying the initial and final logical sectors - Start LBA and End LBA, respectively). The test results are presented in the form of a report (Report tab) and displayed on a graph (Graph) and a disk map (Map) indicating, among other things, the number of bad sectors (Bads) and sectors, the response time of which during testing took more than 500 ms (marked in red ).
Hard Drive Inspector 4.13
Developer: AltrixSoft
Distribution size: 2.64 MB
Work under control: Windows 2000/XP/2003 Server/Vista/7
Distribution method: shareware (14-day demo - http://www.altrixsoft.com/ru/download/)
Price: Hard Drive Inspector Professional - 600 rubles; Hard Drive Inspector for Notebooks - 800 rubles.
Hard Drive Inspector is a handy solution for S.M.A.R.T. monitoring of external and internal HDDs. AT this moment the program is offered on the market in two editions: basic Hard Drive Inspector Professional and portable Hard Drive Inspector for Notebooks; the latter includes all the functionality of the Professional version, and at the same time takes into account the specifics of monitoring laptop hard drives. Theoretically, there is another version of the SSD, but it is distributed only in OEM deliveries.
The program provides automatic check S.M.A.R.T.-attributes at specified intervals and upon completion issues its verdict regarding the state of the drive with the display of the values of some conditional indicators: "reliability", "performance" and "no errors" along with a numerical temperature value and a temperature diagram. It also provides technical data about the drive model, its capacity, total free space and operating time in hours (days). In advanced mode, you can view information about disk parameters (buffer size, firmware name, etc.) and the S.M.A.R.T attribute table. There are various options for informing the user in case of critical changes on the disk. Additionally, the utility can be used to reduce the noise level produced by hard drives and reduce the power consumption of the HDD.
HD Life 4.0
Developer: BinarySense Ltd.
Distribution size: 8.45 MB
Work under control: Windows 2000/XP/2003/Vista/7/8
Distribution method: shareware (15-day demo - http://hddlife.ru/rus/downloads.html)
Price: HDDlife - free; HDDLife Pro - 300 rubles; HDDlife for Notebooks - 500 rubles.
HDDLife is a simple utility designed to monitor the status of hard drives and SSDs (since version 4.0). The program is presented in three editions: free HDDLife and two commercial editions - basic HDDLife Pro and portable HDDlife for Notebooks.
The utility monitors S.M.A.R.T. attributes and temperature at specified intervals and, based on the results of the analysis, issues a compact report on the state of the disk, indicating technical data on the disk model and its capacity, hours worked, temperature, and also displays the conditional percentage of its health and performance, which allows to navigate the situation even for beginners. More advanced users additionally, they can look at the table of S.M.A.R.T.-attributes. In case of problems with the hard drive, it is possible to configure notifications; you can configure the program so that when the disk is in a normal state, the results of the check are not displayed. HDD noise level and power consumption can be controlled.
CrystalDiskInfo 5.4.2
Developer: Hiyohiyo
Distribution size: 1.79 MB
Work under control: Windows XP/2003/Vista/2008/7/8/2012
Distribution method: freeware (http://crystalmark.info/download/index-e.html)
Price: is free
CrystalDiskInfo is a simple S.M.A.R.T. external HDD) and SSD. Despite the freeware, the program has all the necessary functionality to organize disk health monitoring.
Disks are monitored automatically after a specified number of minutes or on demand. At the end of the test, the system tray displays the temperature of monitored devices; Detailed information about the HDD with S.M.A.R.T. values, temperature, and the program's verdict on the state of the devices is available in the main window of the utility. There is functionality to set threshold values for some parameters and automatically notify the user if they are exceeded. Noise level management (AAM) and power management (APM) are possible.
Unfortunately, a large part of modern HDDs work normally for a little over a year, then all sorts of problems begin, which over time can lead to data loss. Such a prospect can be avoided if one carefully monitors hard disk, for example, using the utilities discussed in the article. However, you should not forget about regular backup of valuable data either, since monitoring utilities, as a rule, successfully predict the failure of a drive due to the fault of "mechanics" (according to Seagate's statistics, about 60% of HDDs fail due to mechanical components), but they are not able to predict the death of the drive due to problems with electronic components disk.
When displaying S.M.A.R.T parameters, Value must exceed Threshold (critical parameter value), this value must be high.
A green attribute marker indicates that the attribute parameter is normal.
The yellow marker indicates a slight discrepancy.
Red - these are strong discrepancies, with this parameter the hard drive can fail at any minute, storing data on it is unsafe.
Raw Read Error Rate- this attribute displays the error rate when reading from disk.
Spin Up Time- an attribute of disk promotion to a working state, a poor-quality power supply can affect the difference with the reference value.
Start/Stop Count- the number of starts and stops of the hard drive.
Reallocated Sector Count- the counter of reallocated sectors, showing the number of spare sectors capable of replacing bad ones, the most significant parameter for the performance of the hard drive. When the hard drive system detects a read / write error, the sector is overwritten to the reserve area, this parameter most clearly shows the performance of your hard drive, and most importantly, this attribute cannot be corrected by any programs. With a critically low indicator of this parameter, it is worth thinking about changing the hard drive.
Seek Error Rate- the value of the frequency of errors in the positioning of the heads, informs about the overheating of the hard drive or an unstable position in the basket, the solution is possible in a more reliable fixing of the hard drive.
Power-on Hours Count- an attribute that displays the number of hours in the on state.
Spin Retry Count- the number of repetitions of spinning the disk in case of an unsuccessful previous one.
Recalibration Retries- this attribute indicates how many calibration repetitions were made, provided that the first attempt was unsuccessful. Indicates problems with the mechanical part of the hard drive.
Device Power Cycle Count- the number of complete cycles of switching on / off the device.
Emergency Retract Count- head parking attribute emergency situations, loss of power or a strong decrease in it, it happens with poor contact of the power connector or glitches of the HDD board.
Load/unload Cycle Count- the number of cycles of bringing the heads into the working position.
HDA Temperature- Hard disk temperature.
Reallocation Event Count- counter of remapping operations, shows the number of attempts to transfer bad sectors to the reserve area.
Current Pending Errors Count- a counter of sectors whose reading is difficult, these sectors include sectors that could not be read the first time, the so-called bad blocks, it is possible to fix it by forcibly writing information to them and reading it, this procedure can be performed by the HddScan program.
Uncorrectable Errors Count- counter of uncorrectable errors, indicates defects in the surface of the hard disk.
UltraDMA CRC Errors- external interface errors that occur when the SATA cable is of poor quality.
Multi Zone Error Rate- the frequency of occurrence of errors when recording data.
S.M.A.R.T. technology She was born back in 1995, so her age is respectable. It was assumed that the SMART attributes (let's write the abbreviation without dots for simplicity) generated by the hard disk firmware will allow you to programmatically evaluate the state of the drive, and also provide a mechanism for predicting its failure. The latter was quite relevant in those days: the life of disks in servers, for example, was estimated at a year and a half, and it was useful to know when to prepare a replacement.
Over time, a lot has changed: something has died, some aspects have developed more strongly (for example, control of the mechanics of the disk). The initial set of a dozen of the simplest attributes became more complicated and grew several times, sometimes their meaning changed, many manufacturers introduced their own attributes with not always clear functionality. A lot of programs for SMART analysis have appeared (as a rule, of low quality, but with an effective interface, and even for money), etc.
So it doesn't hurt to describe the modern SMART state. Let's start with critical attributes, the deterioration of which almost always indicates problems with the drive. It is their first thing that repairmen look at when diagnosing an HDD.
- #01 Raw Read Error Rate— the frequency of errors when reading data from a disk, the origin of which is due to the hardware of the disk. For all Seagate, Samsung (F1 and newer families) and Fujitsu 2.5″ drives, this is the number of internal data corrections performed BEFORE being output to the interface; frighteningly huge numbers can be ignored.
- #03 Spin Up Time is the time for the plate pack to spin up from rest to operating speed. It grows with the wear of the mechanics (increased friction in the bearing, etc.), and may also indicate poor-quality power (for example, a voltage drop when the disk starts).
- #05 Reallocated Sectors Count— number of sector reassignment operations. When a drive encounters a read/write error, it marks the sector as remapped and transfers the data to the spare area. That's why you can't see bad blocks on modern HDDs - they are all hidden in reassigned sectors. This process is called remapping, in jargon - remap. The Raw Value field of the attribute contains the total number of reallocated sectors. The larger it is, the worse the condition of the disk surface.
- #07 Seek Error Rate is the frequency of errors in the positioning of the block of magnetic heads (BMG). An increase in this attribute indicates poor surface quality or damaged drive mechanics. Overheating and external vibrations (for example, from neighboring disks in the basket) can also affect.
- #10 Spin-Up Retry Count- the number of repeated attempts to spin up the disks to the operating speed in case the first attempt was unsuccessful. If the value of the attribute grows, then there is a high probability of problems with the mechanics.
- #196 Reallocation Event Count— number of reassignment operations. The Raw Value field of the attribute stores the total number of attempts to transfer information from bad sectors to the spare area of the disk (it is usually not too large - several thousand sectors). Both successful and unsuccessful operations are counted.
- #197 Current Pending Sector Count— current number of unstable sectors. This stores the number of sectors that are candidates for replacement. They have not yet been identified as bad, but reading from them occurs with difficulty (for example, not the first time). If the “suspicious” sector is read successfully in the future, then it is excluded from the list of candidates. In case of repeated erroneous reads, the drive will try to restore it and perform a remap.
- #198 Uncorrectable Sector Count- the number of sectors, during the reading of which there are uncorrectable ( internal funds) errors. An increase in this attribute indicates serious surface defects or problems with the drive mechanics.
- #220 Disk Shift- shift of the plate package relative to the spindle axis. Mostly occurs due to a strong impact or drop of the disc. The unit of measurement is unknown, but with a strong increase in the attribute, the disk is not a tenant.
It should also be taken into account information attributes, capable of telling a lot about the "history" of the disc.
- #02 throughput performance- average disk performance. If the attribute value decreases, then the drive is likely to have problems.
- #04 Start/Stop Count- the number of start-stop cycles of the spindle. Drives from some manufacturers (for example, Seagate) have a power saving mode activation counter.
- #08 Seek Time Performance is the average performance of the head positioning operation. A decrease in the value of this attribute indicates a malfunction in the mechanics of the actuator (primarily slow positioning).
- #09 Power-On Hours (POH)- the time spent in the on state. Shows the total time of the disk, the unit of measurement depends on the model (not only 1 hour, but also 30 minutes, and even 1 minute).
- #11 Recalibration Retries— the number of recalibration repetitions in case the first attempt was unsuccessful. An increase in this attribute indicates problems with the mechanics of the disc.
- #12 Device Power Cycle Count- the number of complete disk on-off cycles.
- #13 Soft Read Error Rate- the frequency of occurrence of "software" errors when reading data. This includes errors software, drivers, file system, incorrect disk layout - in general, almost everything that is not related to the hardware.
- #190 Airflow Temperature — air temperature inside the HDD case. For Seagate drives, the attribute is returned in the normalization of 100º minus temperature (therefore, the critical temperature corresponds to the value 45), while Western Digital models use the normalization of 125º minus temperature.
- #191 G- senseerrorrate is the number of errors that have arisen due to external loads. The attribute stores the readings of the built-in accelerometer, which captures all shocks, shocks, falls, and even inaccurate installation of the disk into the computer case.
- #192 power- offretractcount— number of recorded repetitions of drive power on/off.
- #193 Load/Unload Cycle Count- the number of cycles of moving the HMG to a special parking area / to the working position.
- #194 HDA temperature- the temperature of the mechanical part of the disk, colloquially cans (HDA - Hard Disk Assembly). Information is taken from the built-in thermal sensor, which is one of the magnetic heads, usually the bottom one in the bank. The attribute's bit fields record the current, minimum, and maximum temperatures. Not all programs that work with SMART parse these fields correctly, so their readings should be treated critically.
- #195 Hardware ECC Recovered is the number of errors corrected by the disk hardware. This includes read errors, position errors, and external interface transmission errors. On drives with a SATA interface, the value often worsens when the system bus frequency increases - SATA is very sensitive to overclocking.
- #199 UltraDMA (UltraATA)CRCerrorCount— the number of errors that occur during data transmission over the external interface in UltraDMA mode (packet integrity violations, etc.). The growth of this attribute indicates a bad (wrinkled, twisted) cable and bad contacts. Also, similar errors appear during overclocking. PCI bus, power failures, strong electromagnetic interference, and sometimes due to the fault of the driver.
- #200 Write Error Rate/ Multi-Zone Error Rate is the frequency of occurrence of errors in data recording. Shows the total number of disk write errors. The higher the attribute value, the worse the condition of the surface and mechanics of the drive.
As you can see, most of the "interesting" attributes reflect the functioning mechanics drive. SMART technology really allows you to predict the failure of a drive as a result of mechanical faults, which, according to statistics, is about 60% of all failures. Temperature monitoring is also useful: overheating of the heads sharply accelerates their degradation, so exceeding the dangerous threshold (45-55º depending on the model) is a signal to urgently improve disk cooling.
At the same time, the possibilities of SMART should not be overestimated. Modern disks often "die" against the background of excellent attributes, which is associated with delicate defect management processes in conditions of high recording density and not always, to put it mildly, high-quality components (discrepancy in the return of heads is a common thing today). Moreover, SMART is not able to predict the consequences of such "force majeure" as a power surge, overheating of the electronics board or damage to the drive from impact.
For almost all attributes, the Raw Value field is of the greatest interest: “raw” values are the most informative. Their normalization (the degree of approximation to the abstract threshold) often does not give anything and only confuses the matter. Therefore, programs relying on these percentages cannot be considered completely reliable. A typical case for them is false alarms. The program reports that a new, recently installed drive is about to “glue fins together”. And the thing is that at the beginning of operation, some SMART attributes change quickly and primitive extrapolation leads to forecasts frightening the user.
I recommend the free HDDScan program - it correctly understands all the attributes, including new ones, correctly analyzes temperature indicators. The report is displayed in the form of a neat xml-table with color indication, which can be saved or printed.
SMART drive WD five years old. Its imminent demise is evidenced by the non-zero values of attributes 1 and 200 (for WD they are especially fraught), as well as the fact that attribute 197 grows again after the remap. This means that the possibilities for correcting defects have been exhausted.
Extremely useful for HDDScan is the ability to read SMART from external drives so common today. Almost no other program can do this, because a controller that converts the PATA / SATA interface to USB or FireWire stands in the way of data. The author purposefully worked in this direction, and he managed to cover a wide range of controllers. SCSI disks, which are still widely used in servers, are not forgotten either (they have special attributes - for example, the total number of bytes written or read over the entire life of the drive is displayed).
The functionality of HDDScan fully meets the needs of the repairman. When the initial diagnostics of the brought external drive can be carried out without disassembling the case, this is convenient, saves time, and sometimes even saves the warranty.

SMART taken from a SCSI disk. Here, historically, completely different attributes have developed.
⇡ HDD Barriers
The mechanics have long been the Achilles' heel of HDDs, and not so much because of the sensitivity to shock and vibration (this can still be compensated), but because of the slowness. The fastest "twitching" by a block of magnetic heads (2-3 ms for the best server models) is thousands of times inferior to the speed of electronics.
And there's really nothing to improve here. There is nowhere to raise the rotation speed of the disk pack, 15000 rpm is already the limit. The Japanese a few years ago approached 20,000 rpm (quite a gyroscopic speed), but in the end they refused - the materials do not withstand, the design turns out to be too expensive and poorly suitable for mass production. In small batches, hard drives will come out gold, no one will buy these - these are not gyroscopes, which there is nothing to replace.
Looks like they hit a barrier. You can't go around mechanics on a crooked goat. The only way out is to increase the recording density, transverse and longitudinal. Longitudinal density (along the track) affects the performance of the drive, i.e. on the data flow to the rest of the computer nodes. But still, even the achieved 100-130 MB / s is too little for today's computers. For example, ordinary random access memory (DRAM) has a real performance of about 3 GB / s, and the processor cache is even more. The difference is orders of magnitude, and it greatly affects the overall performance. Of course, no one expects the same performance from a non-volatile storage device with hundreds of times the capacity of DRAM. But even a simple doubling would be noticeable to any user.
The transverse recording density is the density of tracks on a platter; in modern HDDs it exceeds 10,000 per 1 millimeter. It turns out that the track itself has a width of less than 100 nm (by the way, nanotechnology in its purest form). This allows you to dramatically increase the capacity per surface, and also speeds up positioning due to sophisticated algorithms (their development would pull on a couple of doctoral theses).
As a result, HDD capacity and performance have grown significantly in recent years. All this became possible thanks to the technology of perpendicular recording, which has existed for more than 20 years, but only in 2007 matured to mass implementation. Moreover, the capacity then grew even more than required: the first terabyte disks met with a sluggish response from users. The people simply did not understand where to adapt such monsters, especially since at first they were built on five plates, they were capricious, noisy and hot (we are talking about the then Hitachi flagships).
Then, of course, people figured it out, torrents started working at full capacity, and the number of plates decreased. At the same time, the recording density has grown to 500-750 GB per platter (meaning desktop segment drives with a 3.5″ form factor). It's about to go into mass production terabyte platters, which will make it possible to produce hard drives up to 4 TB (more than four platters in a standard case with a height of 26.1 mm cannot be accommodated; Khitachev's five-platter firstborns have not received much development).

Three-terabyte drive WD Caviar Green WD30EZRX, the most capacious one today. It has a four-plate design and has been produced for exactly one year (since October 20, 2010). As expected, it became cheaper in spring and summer, but in recent days it has risen sharply in price due to flooding in Thailand (WD assembly plants are located there, and the elements blocked the delivery of components)
Alas, the positioning speed has grown, to put it mildly, not much, but for mass models it generally remained at the same level, or even fell for the sake of ... silence. Marketers have proven that the consumer votes with their wallet for gigabytes per dollar, and not for milliseconds of access. That's why cheap disks are slow compared to thoroughbred server counterparts. Slowness is well manifested in the speed of loading the OS, when you need to read from the disk a large number of small files scattered across the plates. Here the main role is played by the speed of rotation of the spindle and the powerful drive of the BMG, which makes it possible to achieve high accelerations.
By the way, “fast” disks are easy to distinguish even by weight - they are noticeably heavier than “slow” ones. A full-sized jar with thickened walls that contributes to geometric stability and vibration suppression, a high-speed spindle motor, powerful positioner magnets, a two-layer lid of increased rigidity - all this adds tens and hundreds of grams to such a drive. The gap is even greater in server models at 15,000 rpm, where the reduced plates are surrounded by an impressive volume of cast aluminum, and the total weight of the “hard” reaches a kilogram.

High performance WD Raptor blade with 10,000 rpm spindle speed. With a capacity of 150 GB, it weighs 740 g (mass models of the same capacity - 400-500 g). Pay attention to the size of the magnets and the wall thickness
With the cheapening of solid-state SSDs, which are used primarily for the operating system, the need for high-performance HDDs began to decline, and they themselves gradually stand out in a special market segment (such, for example, is the “black” series from WD). Professional workstations with resource-intensive applications that are critical to access speed are equipped with such disks. Ordinary users are not in a hurry to take rather expensive drives, preferring the amount of performance.
At the other end of the spectrum are popular "green" models with deliberately slow spindle rotation (5400-5900 rpm instead of 7200) and slow head positioning. Cheap, quiet, cool and fairly reliable, these drives are ideal for storing multimedia data in home computers, external cases and network storage. On our shelves, all these Green and LP have strongly pressed other lines, so sometimes you won’t find anything else in small “points”.
⇡ The wastefulness of magnetic recording
The magnetization of the hard disk domains, as in the middle of the twentieth century, is changed using a magnetic head, the field of which is excited by a variable electric shock and acts on the magnetic layer through the gap. Also, this technology requires fast rotation of the plates, precise control of the position of the head, etc. The motor and positioner of the hard drive, as well as the electronics that control them, consume noticeable power, and they cost a lot. But the main thing is that a lot of energy is spent on the very excitation of the magnetic field.
The wastefulness of the standard magnetic recording method is difficult to appreciate when working on a personal computer. Mass-produced hard drives consume less than 10 W even during active operation, which is almost imperceptible against the background of other components (100 W or more). But your views will immediately change after visiting the server room of some large bank, and to get impressions of a lifetime, just walk up to the disk rack of a supercomputer. In the noise of hundreds and thousands of hard drives, blowing fans and precision air conditioners, it becomes clear how much energy is spent on a global scale for such work.
Not without reason for data storage systems, energy efficiency comes to the fore in the list of characteristics. Google is already moving its data centers to barges at sea (that's where the real offshores are!). It turns out that cooling storage systems with outboard water radically reduces operating costs, primarily due to savings on air conditioners.
⇡ About powering hard drives
Will a regular 220 volt light bulb work on 230 volts? Of course it will be. And from 240 V? Too. The question is how long will it last? It is clear that less or significantly less - it depends on the particular light bulb. She is destined for a bright but short life.
Roughly the same situation with hard drives. Naive manufacturers designed them relying on standard +5 V and +12 V. However, in a typical computer power supply (PSU), only the 5 V line stabilizes. What does this lead to?
With a high load on the processor (and modern "stones" consume a lot) and insufficient PSU power, the 5 V line sags, and the stabilization system works out this matter, increasing the voltage to the nominal value. At the same time, the voltage of 12 V also rises (due to the lack of stabilization on it). As a result, the HDD, which is already unstable to heat, also operates at increased voltage, which is supplied to the most heated components - the engine control chip (in the jargon of repairmen - “twist”) and the drive heads (the so-called “voice coil”). Bottom line - see the argument about the light bulb.


A burnt "twist" on the board as a result of increased voltage and poor cooling. Often, the microcircuit literally burns out, with pyrotechnic effects and burnout of tracks on the board. This is beyond repair
Hence the advice on the power supply. The greater its power, the better (within reasonable limits: a reserve of more than 30-35% in relation to real consumption reduces the efficiency of the unit, so you will heat the room). A less powerful, but branded PSU is better than a more powerful, but rootless Chinese one. Remember - not only processors are overclocked. As a first approximation, 420 "Chinese" watts are equivalent to 300 "correct".
In a good way, one should also take into account the age of the PSU: after 2-3 years of operation, its real power decreases markedly, and the output voltages drift. Of course, in low-quality products that work on an honest Chinese word, the aging processes are much more pronounced. It’s good if such a block dies quietly on its own, and does not drag away half of the system block in agony!
The maximum allowable is 12.6 V (+5% of the nominal). However, with increasing voltage, many disks exhibit a non-linearly sharp heating of the above-mentioned nodes - “twists” and “coils”. Therefore, I recommend monitoring the PSU more strictly with an external voltmeter (the sensors on the motherboard that measure the voltage for the BIOS and programs like AIDA can be quite inaccurate).
It is best to measure voltage on Molex connectors and always under full load: the processor is busy with floating point calculations, the video card is outputting dynamic 3D graphics, and disk defragmentation. At 12.2-12.4 V, you should think about it, 12.4-12.6 V - worry, 12.6-13 V - sound the alarm, and in the case of 13 V and above - save money for new disk or put the warranty card in a conspicuous place ...

Capacitors (2200 uF, 25 V) soldered to the HDD power circuit (yellow wire - +12 V, red - +5 V, black - ground). In this case, they reduce voltage ripple, from which the power supply emits an annoying high-frequency squeak.
If the voltage on the 12 V line is too high, and you are not afraid of a soldering iron and are able to distinguish a transistor from a diode, then you can turn the latter into a HDD power cut (I remind you that the 12 V line corresponds to a yellow wire). The diode will play the role of a limiter - “extra” 0.2-0.7 V will drop at its p-n junction (depending on the type of diode), and the disk will feel better. Only the diode must be taken powerful enough to withstand the starting current of 2-3 A.
And without fanaticism: the resulting voltage should not fall below 11.7 V. Otherwise, unstable operation of the disk (multiple restarts) and even data corruption is possible. And some models (in particular, Seagate 7200.10 and 7200.11) may not start at all.
⇡ Flash migration
NAND Flash memory appeared much later than the HDD, and adopted a number of its technologies - take at least ECC codes. Further, both directions developed in parallel and relatively independently. But recently there has also been a reverse process: the migration of technologies from flash memory to hard drives. Specifically, we are talking about wear leveling.
As you know, any flash chip has limited resource by the number of erasures-records in one cell. At some point, it is no longer possible to erase it, and it freezes forever with the last recorded value. Therefore, the controller counts the number of entries in each page and, if exceeded, copies it to a less worn place. In the future, all work is carried out with a new site (this is managed by the translator), and old page remains as is and is not used. This technology is called Wear Leveling. So, there is wear and tear in hard drives, but there it is mechanical and thermal. If the magnetic head hangs over one track all the time (for example, this or that file is constantly changing), then the probability of damage to the track increases due to accidental shocks or vibration of the disk (for example, from neighboring drives in the basket). The head can touch the plate and damage the magnetic layer with all the ensuing unfortunate consequences. Even if there is no harmful contact, the fixed head heats up locally and, albeit reversibly, degrades. Writing to this place is less reliable, the probability of subsequent unstable reading increases (and with today's huge recording densities, any deviation of the parameters is fatal).
These considerations are quite obvious, and the firmware of server disks with a SCSI/SAS interface (and they are quite hot) has long since learned to move heads when idle so that they do not overheat. But it’s even better to “transfer” information along the platter together with the head - in this case, the described effects are suppressed as much as possible, and the reliability of the drive increases. Here Western Digital has introduced a similar mechanism in the new VelociRaptor models. These are expensive high-performance discs with a 10,000 rpm spindle speed and a five-year warranty, so Wear Leveling is appropriate there.


VelociRaptor outside and inside. A powerful radiator attracts attention. The plates, on the other hand, have a reduced diameter - this is typical for modern high-speed discs.
In addition, the entire VelociRaptor line is aimed at use in highly loaded systems, primarily servers, where disk writes are very intensive and often to the same files (transaction logs are a typical example). Mass "consumer" disks are not threatened by high loads, they also heat up moderately, so such a refinement is unlikely to appear there. However, let's wait and see.
⇡ Advanced Format and its application
For over 20 years, all hard drives have had the same physical sector size: 512 bytes. This is the minimum amount of writing to disk, which allows you to flexibly manage the distribution of disk space. However, as the volume of HDDs grew, the disadvantages of this approach became more and more apparent - first of all, inefficient use of the capacity of the magnetic plate, as well as high overhead costs when organizing a data stream.
Therefore, high-capacity disks (terabytes and higher) began to be produced using the technology advanced format, which operates on "long" physical sectors of 4096 bytes. The marking of magnetic platters for AF is very beneficial for the manufacturer: fewer inter-sector gaps, higher usable capacity of the track and the entire platter (and this, along with magnetic heads, is the most expensive HDD component). It was Advanced Format that made it possible to launch inexpensive hard drives on the market, which are now so popular among consumers of audio and video content. AF-disks with a capacity of 1-3 TB are equipped not only with computers, but also with a lot of external drives, network storages and media players.

One of the first 3.5″ discs with Advanced Format, released in 2009
But nothing is given for free, new discs are already starting to be brought in for repairs. Looks like the reliability has gone down. After all, a single disk failure or surface defect now corrupts 8 times more user data than usual. With a physical sector of 4 KB and emulation of "short" sectors of 512 bytes, from 1 to 8 sectors will not be read. The operating system reacts to this clearly as: an accident, everything is gone! As a result, a minor problem on the plates grows for the user into a freeze or something even worse.
I don't think you should keep OS, application programs and databases with lots of small files on AF disks. So far, their lot is multimedia data that is not critical to dropouts.
First of all, I recommend looking at the HARDW.net forum. Its "Information Storage" section is visited by many professional repairmen and enthusiasts (almost 40,000 participants). There you can find answers on almost any topic related to the HDD, with the exception of the newest "undiscovered" models. Start with the “Sandbox” subsection: simple (in the understanding of professionals) questions are answered there in detail and meaningfully, and not rejected, as in other places - “take it to the repairman”.
More information, however, English language, can be found on the HDDGURU portal. In addition to repair and diagnostic software and articles on specific issues (for example, how to change disk heads), there is an international forum for repairmen, as well as a huge archive of HDD resources (firmware, documentation, photos, etc.). The portal instills a broad view of things, it will be of interest to prepared and motivated people. In any case, in closed conferences of repairmen, references to it run constantly.
I will also refer to my article "How to extend the life of hard drives" in three parts. It gives initial information on handling HDDs, and although it was written more than three years ago, it is not much out of date - drives have not fundamentally changed during this time, except that they have become even less reliable due to fierce savings. Manufacturers, caught in the global crisis, reduced their costs in all areas, which caused a number of high-profile failures in 2008-2009. One of them will be discussed in the continuation of this material, which will be released in the near future.
Sequence of actions in the presence of S.M.A.R.T. hard drive or SSD errors. How to fix disk and recover lost data. When you boot your computer or laptop, S.M.A.R.T. appears. hard drive or ssd error? After this error, the computer does not work as before, and you are afraid about the safety of your data? Don't know how to fix the error?
Actual for OS: Windows 10, Windows 8.1, Windows Server 2012, Windows 8, Windows Home Server 2011, Windows 7 (Seven), Windows Small Business Server, Windows Server 2008, Windows home Server, Windows Vista, Windows XP, Windows 2000, Windows NT.
What to do with SMART error?
Step 1: Stop using the failed HDD
Receiving an error diagnostic message from the system does not mean that the drive has already failed. But in case of S.M.A.R.T. errors, you need to understand that the disk is already in the process of failure. A complete failure can occur both within a few minutes, and after a month or a year. But in any case, this means that you can no longer trust your data to such a disk.
You need to take care of the safety of your data, create a backup copy or transfer files to another storage medium. Along with the safety of your data, you must take steps to replace the hard drive. The hard drive where the S.M.A.R.T. errors should not be exploited - even if it does not completely fail, it can partially damage your data.
Of course, a hard drive can fail without S.M.A.R.T. But this technology gives you the advantage of warning you that a drive is about to fail.
Step 2: Recover deleted disk data
In the event of a SMART error, data recovery from the disk is not always required. In the event of an error, it is recommended to immediately create a copy of important data, as the disk may fail at any time. But there are errors in which it is no longer possible to copy data. In this case, you can use the recovery program data hard disk - Hetman Partition Recovery.

For this:
- Download the program, install and run it.
- By default, the user will be prompted to use File recovery wizard. Pushing a button "Further", the program will prompt you to select the drive from which you want to recover files.
- Double click on the failed drive and select the type of analysis you want. Choose "Full Analysis" and wait for the disk scanning process to complete.
- After the scanning process is completed, you will be provided with files to restore. Select the desired files and click the button "Reestablish".
- Choose one of the suggested ways to save files. Do not save recovered files to a disk with an error.
Step 3: Scan the disk for bad sectors
Run a scan of all hard disk partitions and try to fix any errors found.

To do this, open the folder "This computer" and click right click mouse on disk with SMART error. Select Properties / Service / Verify In chapter Checking the disk for errors.
As a result of scanning, errors found on the disk can be corrected.
Step 4: Reduce disk temperature
Sometimes, the cause of the “S M A R T” error may be the exceeding of the maximum allowable operating temperature of the disk. This error can be fixed by improving the ventilation of the computer. First, check if your computer is equipped with sufficient ventilation and if all fans are working properly.
If you find and fix a ventilation problem, after which the drive temperature drops to a normal level, then the SMART error may no longer occur.
Step 5:
Open folder "This computer" and right-click on the disk with the error. Select Properties / Service / Optimize In chapter Disk optimization and defragmentation.

Select the drive you want to optimize and click Optimize.
Note. In Windows 10, disk defragmentation and optimization can be configured to run automatically.
Step 6: Buy a new hard drive
If you encounter a SMART hard drive error, then purchasing a new drive is only a matter of time. Which hard drive you need depends on your computer style and the purpose for which it is being used.
What to look for when purchasing a new drive:
- Disk type: HDD, SSD or SSHD. Each type has its pros and cons, which are not critical for some users and are very important for others. The main ones are the speed of reading and writing information, volume and resistance to repeated rewriting.
- The size. There are two main drive form factors: 3.5" and 2.5". The disk size is determined in accordance with the installation location of a particular computer or laptop.
- Interface. Main hard drive interfaces:
- SATA
- IDE, ATAPI, ATA;
- SCSI
- External drive (USB, FireWire, etc.).
- Specifications and performance:
- Capacity;
- Read and write speed;
- The size of the memory buffer or cache;
- Response time;
- Fault tolerance.
- S.M.A.R.T.. The presence of this technology in the disk will help to identify possible errors in its operation and prevent data loss in time.
- Equipment. This item includes the possible presence of interface or power cables, as well as warranty and service.
How to reset SMART error?
SMART errors can be easily reset in the BIOS (or UEFI). But the developers of all operating systems categorically do not recommend doing this. If the data on the hard disk is of no value to you, then the output of SMART errors can be disabled.
To do this, do the following:
- Restart your computer, and by pressing the key combination indicated on the boot screen (they are different for different manufacturers, usually "F2" or Del) go to BIOS (or UEFI).
- Go to: advanced > SMART settings > SMART self test. Set value Disabled.
Note: the location for disabling the function is approximate, since depending on the BIOS or UEFI version, the location of this setting may vary slightly.
Is HDD repair worth it?
It is important to understand that any of the ways to eliminate SMART errors is self-deception. It is impossible to completely eliminate the cause of the error, since the main cause of its occurrence is often the physical wear of the hard drive mechanism.
To eliminate or replace malfunctioning hard drive components, you can contact the service center of a special laboratory for working with hard drives.
But the cost of work in this case will be higher than the cost of a new device. Therefore, it makes sense to do repairs only if it is necessary to restore data from an already inoperable disk.
SMART error for SSD drive
Even if you have no complaints about SSD operation disk, its performance gradually decreases. The reason for this is the fact that the memory cells SSD drive have limited quantity rewrite cycles. The wear resistance function minimizes this effect, but does not completely eliminate it.
SSD drives have their own specific SMART attributes that signal the state of the disk's memory cells. For example, “209 Remaining Drive Life”, “231 SSD life left”, etc. These errors can occur when cells are degraded, which means that the information stored in them can be corrupted or lost.
The cells of an SSD disk in the event of a failure are not restored and cannot be replaced.
Is the SMART error fixed? Leave feedback and ask your questions in the comments.
All modern hard drives magnetic disks support the technology of self-testing, condition analysis, and the accumulation of statistical data on the deterioration of their own characteristics S.M.A.R.T. (Self-Monitoring Analysis and Reporting Technology). Basics of S.M.A.R.T. were developed in 1995 by the joint efforts of leading manufacturers of hard drives. In the process of improving the equipment of drives, the capabilities of the technology were also refined, and after the SMART standard, SMART II appeared, then SMART III, which, obviously, will not be the last either.
The hard disk in the course of its operation constantly monitors certain parameters of its state and reflects them in special characteristics - attributes(Attribute), which are stored, as a rule, in a specially allocated part of the disk surface, accessible only to the internal firmware of the drive - service area. Attribute data can be read by special software.
Attributes are identified by their numeric number, most of which are interpreted in the same way by accumulators different models. Some attributes may be specific to the hardware manufacturer and may only be supported by certain drive models.
Attributes consist of several fields, each of which has a specific meaning. Typically, S.M.A.R.T. give a decoding of the attributes in the form:
- attribute- attribute name
- ID- attribute identifier
- value- the current value of the attribute
- Threshold- minimum threshold value of the attribute
- Worst- most low value attributes for the entire time of the drive
- Raw- the absolute value of the attribute
- type(optional) - attribute type - characterizes performance (PR - Performance-related), characterizes failures (ER - Error rate), event counter (EC - Events count), defined by the manufacturer or not used (SP - Self-preserve);
To analyze the state of the drive, perhaps the most important attribute value is value- conditional number (usually from 0 to 100 or up to 253) set by the manufacturer. The Value value is initially set to the maximum when the drive is manufactured and decreases as the drive degrades.
For each attribute, there is a threshold value, until which the manufacturer guarantees its performance - the field Threshold. If the Value value approaches or becomes less than the Threshold value, it is time to change the drive. The list of attributes and their values are not strictly standardized and are determined by the drive manufacturer, but the most important of them are interpreted in the same way.
For example, an attribute with ID 5 ( reallocated sector count) will characterize the number of disk sectors rejected and reassigned from the spare area, both for devices manufactured by Seagate, and for Western Digital, Samsung, Maxtor.
The hard drive does not have the ability, on its own initiative, to transmit SMART data to the consumer. Their reading is performed by special software.
In the settings of most modern motherboard BIOS boards, there is an item that allows you to disable or enable the reading and analysis of SMART attributes in the process of performing hardware tests before performing the system boot. Enabling this option allows the BIOS hardware test subroutine to read the values of critical attributes and, if the threshold is exceeded, warn the user about it. As a rule, without much detail:
Primary Master Hard Disk: S.M.A.R.T status BAD!, Backup and Replace.
The execution of the BIOS routine is paused to attract attention:
Thus, without installing or running additional software, it is possible to timely determine the critical state of the drive (when this option is enabled) using the Basic Input/Output System (BIOS).
S.M.A.R.T data analysis. hard drive
To obtain SMART data in the operating system environment, special programs can be used, in particular, almost all utilities for testing hard drive hardware.
One of the most popular programs for testing hard drives is Victoria Sergei Kazansky. On the author's website you will find latest version programs, as well as useful information, including a detailed description of working with Victoria.
The Victoria program has two varieties - for working in a DOS environment and for working in a Windows environment. The DOS version can work directly with the hard disk controller and is much more powerful than the Windows version. The purpose, main features and procedure for using the program could previously be found on the author's website, but for some time now the site has been abandoned and there is no information there.
The program is easy to use and allows you to evaluate the technical condition of the drive, perform its testing and some settings - noise level, performance, physical volume. Drive surface testing modes allow you to forcibly get rid of bad sectors using the Remap several types. The test menu is called by pressing the key F4 (SCAN). The user has the ability to set testing area:
- Start LBA:0- area start (default - 0)
- End LBA:14680064- end of area (by default - number of the last disk block)
Test mode:
- Linear reading- sequential reading from the initial block to the final one;
- Random reading- the number of the read block is generated randomly;
- BUTTERFLY reading- blocks are read starting from the boundary numbers (beginning and end) to the center of the testing area. Changing the mode is performed by pressing the spacebar.
Error Handling Mode. This item allows you to hide defective blocks using remapping from the spare area. The choice of the mode is carried out by the "space" key. The selected method of working with defects is displayed in the right upper corner screen, under the clock, as well as in bottom line at the time the test is run. You can change the mode at and during a scan.
- Ignore Bad Blocks- the program will not perform any actions when an error is detected.
- BB = RESTORE DATA- the program will try to recover data from bad sectors.
- BB = Classic REMAP- write to the bad sector to call the remapping procedure.
- BB = Advanced REMAP- improved algorithm for hiding bad blocks. It is used when the classic remap does not help. The program performs a special sequence of operations in order to form a remap candidate sign (attribute 197) for a bad block. Then a 10-fold write is performed, processed by the drive firmware as normal remap candidate processing - if there is an error, a remap is performed, if there is no error, the block is considered normal and removed from the remap candidates. This mode allows you to hide bad blocks without losing user data. Of course, only in cases where the drive is technically sound and has free place in the spare area for reassignment.
- BB = Fujitsu Remap- execution of specific algorithms based on undocumented features of some Fujitsu drive models
- BB = Erase 256 sect- when a bad sector is detected, a block of 256 sectors is overwritten. User data is not saved.
In the process of working with the program, you can call the context help by pressing F1
Version Victoria Windows it has more modest options for setting up the drive and selecting test modes, and currently does not have support for the Russian language, however, it is easier to use and the available capabilities are quite enough to read the SMART table and assess the technical condition of the drive.
The program does not require installation, just download the latest version from the link Victoria v4.47 from our website.
The program must be run under an account with administrator rights. In the Windows 7 / 8 environment, you must use the “Run as administrator” context menu.
To analyze the state of SMART attributes, select the operating mode through the software Windows interface- enable button API at the top right of the main window. Then select the drive to check - click on the button standard in the main menu of the program and highlight the desired disk in the list box with the mouse.
The information window will display the drive passport - model, firmware version, serial number, size, etc. To receive SMART data, select the menu item SMART and click the "Get SMART" button. The result will be displayed in the information window of the program.
Brief description of the attributes (hexadecimal value of the number is given in brackets):
- 001(1) Raw Read Error Rate- absolute value of reading errors. There are some differences in the formation of the value of this attribute by different manufacturers. From practice, I can say that Seagate drives can have a giant RAW value of this attribute, being really in good condition, and Western Digital drives can have it zero, having critical indicators for other characteristics. Some models may not support this attribute at all.
- 003 (3) Spin Up Time- The average spin-up time of the disc spindle from 0 RPM to operating speed.
- 004 (4) Start/Stop Count- Number of spindle start/stop cycles.
- 005 (5) Reallocated Sector Count- Number of reassigned sectors. Modern drives have a fairly large (thousands of sectors) reserve surface area of the drive to use it in case of deteriorating performance of sectors from the main zone. If the drive detects problems with writing/reading of any sector, it automatically moves its data to the spare area, and this sector is marked as "reassigned". Often this process is called "remapping", or "automatic defect reassignment", it is performed by the firmware of the drive and is invisible to the user (operating system). Field raw value contains the total number of remapped sectors. Even a non-critical, but high value of this field can lead to a decrease in the data exchange speed, since the drive performs an additional operation of installing heads on the tracks of the spare area, usually located at the end of the disk.
- 007 (7) Seek Error Rate- The frequency of occurrence of errors in the positioning of the block of magnetic heads (BMG) . The drive controls the correct installation of the heads on the required track of the surface. In the case when the installation was performed incorrectly, an error is fixed and the operation is repeated. For this drive, the cause of a large number of errors was overheating.
- 008(8) Seek Time Performance- average positioning speed of magnetic heads. If the attribute value decreases (positioning slowdown), then there is a high probability of problems with the mechanical part of the actuator.
- 009 (9) Power On Hours- Number of hours on. Reaching the limit value of this attribute means that the drive has reached the manufacturer-specified time between failures (MTBF - Mean Time Between Failures).
- 010 (0A) Spin Retry Count- Number of retries to start the spindle. After turning on the power, the drive spins up the disks and controls the achievement of the operating speed of rotation for this device (for example, 5400 , 7200, 10000 rpm) for a certain time. In case of failure - the counter of repetitions is increased and the start attempt is repeated.
- 011(0B) Recalibration Retries- the number of recalibration attempts, in case the first attempt was unsuccessful. If the attribute value increases, then there is a high probability of problems with the mechanical part of the drive. In addition, an increase in the absolute value of this attribute may be caused by the fact that the recalibration procedure is used by the drive's internal firmware to correct other types of errors.
- 012 (0C) Device Power Cycle Count- Number of disk on/off cycles.
- 184 (B8) End-to-End error- This attribute - part of the HP SMART IV technology - means that after data transfer through the buffer memory, the parity of the data between the computer controller and the hard disk does not match.
- 187 (BB) Reported Uncorrectable Error- Specifies the number of errors that were not corrected by the drive firmware.
- 188 (BC) Command Timeout Number of aborted operations due to HDD timeout. Usually this attribute value should be zero, and if the value is much higher than zero, then most likely there will be some serious problems with the power supply or oxidation of the interface cable pins.
- 189 (BD) High Fly Writes- If the flight height of the head above the magnetic surface, even for a short time, exceeds the optimum, then the data recorded by it, in the future, may not be read. Modern drives use a specially developed technology for controlling the height of the flight heads, which makes it possible not to write data at a non-optimal height. One is added to the counter of this attribute, and the entry is made after the normal flight altitude is set. An increased value of this attribute can be caused by external shocks or vibrations, abnormal temperatures, deterioration of the magnetic surface or head.
- 190 (BE) Airflow Temperature- temperature environment block of magnetic heads. For most models, this attribute is absent and attribute 194 is used.
- 191 (BF) G-sense error rate- the number of errors resulting from impact loads. The attribute stores the readings of the built-in accelerometer, which captures all shocks, shocks, falls, and even inaccurate installation of the disk into the computer case. Usually it quite accurately characterizes the operating conditions of laptops - a large value of the attribute indicates sharp shocks and falls during the operation of the device.
- 192 (C0) Power-off retract count- the number of cycles of shutdowns or emergency failures (switching on/off the power supply of the drive).
- 193 (C1) Load/Unload Cycle- the number of cycles of moving the block of magnetic heads to the parking area.
- 194 (C2) HDA Temperature- the temperature of the drive itself (HDA - Hard Disk Assembly). This attribute stores the readings of the built-in temperature sensor, which is usually one of the magnetic heads (usually the lower one). The data recorded in the attribute fields displays the current, minimum and maximum temperatures. The Worst field shows the worst temperature reached during the operation of the drive (you can set the fact of overheating and its degree), raw value - the current temperature. Some drive models may support attribute 205 (CD) Thermal asperity rate (TAR), which fixes the number of dangerous temperature drops.
- 195 (C3) Hardware ECC recovered- characterizes the number of read errors corrected by the drive hardware using an error correction code. Such errors do not require re-reading of the sector and do not lead to a loss of data exchange rate, but a large number of them indicates a deterioration in the read path parameters.
- 196 (C4) Reallocation Event Count- Number of bad sector remapping events. In field raw value This attribute stores the total number of attempts to transfer data from unstable sectors to the spare area. Both successful and unsuccessful attempts are counted.
- 197 (C5) Current Pending Sector Count- The current number of unstable sectors. raw value field This attribute shows the total number of sectors that the drive currently considers candidates for remapping. If in the future any of these sectors is read successfully, then it is excluded from the list of candidates. If reading the sector is accompanied by errors, the drive will try to recover the data and transfer it to the backup area, and mark the sector as remapped.
- 198 (C6) Uncorrectable Sector Count- Counter of uncorrectable errors. These are errors that were not corrected by the drive's internal hardware corrections. It can be caused by a malfunction of individual elements or the lack of free sectors in the spare area of \u200b\u200bthe disk when it became necessary to remap.
- 199 (C7) UltraDMA CRC Error Count- Counter of errors that occurred during data transfer in UltraDMA mode. The drive-to-RAM transfer control hardware has detected a checksum error. Often this type of error is associated not so much with the hardware of the drive, but with a faulty interface cable, unstable power supply, overclocking of the PCI bus frequency, overheating of the chipset chipset of the motherboard, etc.
- 200 (C8) Write Error Rate (Multi-Zone Error Rate)- Characterizes the presence of errors when recording data. May be caused by deterioration of the surface, heads, or characteristics of the data path. The lower the Value, the more dangerous it is to use such a drive.
- 220 (DC) Disk Shift- displacement of the block of disks relative to the vertical axis of the spindle. It mainly occurs due to a strong impact or fall of the drive and, as a rule, is a signal for its replacement.
- 228 (E4) Power Off Retract Cycle- The number of automatic parking of magnetic heads when the power is turned off.
Modern drives support not only the formation of S.M.A.R.T attributes, but also keep additional statistics logs, and also support the protocol SCT(SMART Command Transport) that reads log data. The device statistics log is a read-only SMART log sent by the drive when it receives READ LOG EXT, READ LOG DMA EXT, or SMART READ LOG commands. The logs display information about the execution of built-in S.M.A.R.T (self-test) tests, error statistics, LBA bad block numbers, etc.