What is it
DuckDuckGo is a fairly well-known open source search engine. source code. The servers are located in the USA. In addition to its own robot, the search engine uses the results of other sources: Yahoo, Bing, Wikipedia.
The better
DuckDuckGo positions itself as the ultimate privacy and privacy search. The system does not collect any data about the user, does not store logs (no search history), use cookies maximally limited.
DuckDuckGo does not collect or share personal information from users. This is our privacy policy.
Gabriel Weinberg, founder of DuckDuckGo
Why do you need this
All major search engines try to personalize search results based on data about the person in front of the monitor. This phenomenon is called "filter bubble": the user sees only those results that are consistent with his preferences or that the system considers as such.
Forms an objective picture that does not depend on your past behavior on the Web, and eliminates thematic google ads and "Yandex", based on your requests. With the help of DuckDuckGo, it is easy to search for information in foreign languages, while Google and Yandex prefer Russian-language sites by default, even if the query is entered in another language.

What is it
not Evil is a system that searches the anonymous Tor network. To use it, you need to go to this network, for example, by launching a specialized .
not Evil is not the only search engine of its kind. There is LOOK (default search in the Tor browser, accessible from the regular Internet) or TORCH (one of the oldest search engines on the Tor network) and others. We settled on not Evil because of the unmistakable allusion to Google (just look at the start page).
The better
He is looking for where Google, Yandex and other search engines are denied access in principle.
Why do you need this
There are many resources on the Tor network that cannot be found on the law-abiding Internet. And their number will grow as the control of the authorities over the contents of the Web tightens. Tor is a kind of network within the Web with its social networks, torrent trackers, media, trading platforms, blogs, libraries and so on.
3. YaCy

What is it
YaCy is a decentralized search engine that works on the principle of P2P networks. Each computer that has a primary software module, scans the Internet on its own, that is, it is an analogue of a search robot. The results obtained are collected in a common database, which is used by all YaCy participants.
The better
It is difficult to say here whether this is better or worse, since YaCy is a completely different approach to organizing search. The lack of a single server and owner company makes the results completely independent of anyone's preferences. The autonomy of each node excludes censorship. YaCy is capable of searching the deep web and non-indexed public networks.
Why do you need this
If you are an open source supporter and free internet, not influenced by government agencies and large corporations, then YaCy is your choice. It can also be used to organize searches within a corporate or other autonomous network. And although YaCy is not very useful in everyday life, it is a worthy alternative to Google in terms of the search process.
4. Pipl

What is it
Pipl is a system designed to search for information about a specific person.
The better
The authors of Pipl claim that their specialized algorithms search more efficiently than "regular" search engines. In particular, profiles are prioritized social networks, comments, lists of participants, and various databases where information about people is published, such as databases of court decisions. Pipl's leadership in this area is confirmed by Lifehacker.com, TechCrunch and other publications.
Why do you need this
If you need to find information about a person living in the US, then Pipl will be much more efficient than Google. Databases of Russian courts, apparently, are inaccessible to the search engine. Therefore, he does not cope so well with the citizens of Russia.

What is it
FindSounds is another specialized search engine. Searches open sources for various sounds: house, nature, cars, people, and so on. The service does not support requests in Russian, but there is an impressive list of Russian-language tags that you can search for.
The better
In the issuance of only sounds and nothing more. In the settings you can set the desired format and sound quality. All found sounds are available for download. There is a pattern search.
Why do you need this
If you need to quickly find the sound of a musket shot, the blow of a sucking woodpecker, or the cry of Homer Simpson, then this service is for you. And we chose this only from the available Russian-language queries. On the English language the spectrum is even wider.
Seriously, a specialized service implies a specialized audience. But will it come in handy for you too?

What is it
Wolfram|Alpha is a computational search engine. Instead of links to articles containing keywords, it gives a ready-made answer to the user's request. For example, if you enter “compare the population of New York and San Francisco” in English into the search form, then Wolfram|Alpha will immediately display tables and graphs with a comparison.
The better
This service is better than others for finding facts and calculating data. Wolfram|Alpha accumulates and systematizes the knowledge available on the Web from various areas including science, culture and entertainment. If this database contains a ready answer to a search query, the system shows it, if not, it calculates and displays the result. In this case, the user sees only and nothing more.
Why do you need this
If you are, for example, a student, analyst, journalist, or researcher, you can use Wolfram|Alpha to find and calculate data related to your activities. The service does not understand all requests, but is constantly evolving and becoming smarter.

What is it
Metasearch engine Dogpile displays a combined list of results from search engines. Google SERPs, Yahoo and other popular systems.
The better
First, Dogpile displays fewer ads. Secondly, the service uses a special algorithm to find and display top scores from different search engines. According to the developers of Dogpile, their system generates the most complete issue on the entire Internet.
Why do you need this
If you can't find information on Google or another standard search engine, look it up in several search engines at once using Dogpile.

What is it
BoardReader is a text search system for forums, Q&A services and other communities.
The better
The service allows you to narrow the search field to social sites. Thanks to special filters, you can quickly find posts and comments that match your criteria: language, publication date, and site name.
Why do you need this
BoardReader can be useful for PR specialists and other media professionals who are interested in the opinion of the mass media on certain issues.
Finally
The life of alternative search engines is often fleeting. Lifehacker asked the former CEO of the Ukrainian branch of Yandex Sergey Petrenko about the long-term prospects for such projects.

Sergey Petrenko
Former CEO of Yandex.Ukraine.
As for the fate of alternative search engines, it is simple: to be very niche projects with a small audience, therefore, without clear commercial prospects, or, conversely, with the complete clarity of their absence.
If you look at the examples in the article, you can see that such search engines either specialize in a narrow but in-demand niche, which, perhaps only so far, has not grown enough to be noticeable on the radars of Google or Yandex, or are testing an original hypothesis in ranking, which is not yet applicable in conventional search.
For example, if a Tor search suddenly turns out to be in demand, that is, at least a percentage of the Google audience will need the results from there, then, of course, ordinary search engines will begin to solve the problem of how to find them and show them to the user. If the behavior of the audience shows that a significant proportion of users in a significant number of queries seem to be more relevant results, data without taking into account factors that depend on the user, then Yandex or Google will begin to give such results.
"To be better" in the context of this article does not mean "to be better at everything". Yes, in many aspects our heroes are far from Yandex (even far from Bing). But each of these services gives the user something that the giants of the search industry cannot offer. Surely you also know similar projects. Share with us - let's discuss.
PROFESSIONAL SEARCH FOR INFORMATION ON THE INTERNET
Internet search is an important element of working on the Web. The exact number of web resources of the modern Internet is hardly known to anyone for sure. In any case, the bill goes into the billions. In order to be able to use the information that is needed at this particular moment, whether for business or entertainment purposes, you first need to find it in this constantly replenished ocean of resources.
In order for an Internet search to be successful, two conditions must be met: queries must be well formulated and they must be asked in suitable places. In other words, the user is required, on the one hand, to be able to translate their search interests into the language search query, and on the other hand, a good knowledge of search engines, available search tools, their advantages and disadvantages, which will allow you to choose the most appropriate search tools in each specific case.
Currently, there is no single resource that satisfies all the requirements for Internet search. Therefore, with a serious approach to the search, you inevitably have to use different tools, using each in the most appropriate case.
Main internet search toolscan be divided into the following main groups:
search engines;
Web directories;
Reference resources;
Local programs for searching the Internet.
The most popular search engine issearch engines- the so-called Internet search engines (Search Engines). The top three leaders on a global scale are quite stable - these are Google, Yahoo! and Bing. Many countries add their own local search engines optimized for local content to this list. With their help, theoretically, you can find any specific word on the pages of many millions of sites. From the user's point of view, the main disadvantage of search engines is the inevitable presenceinformation noisein the results. This is how it is customary to call results that, for one reason or another, are included in the list of results that do not match the query.
Despite many differences, all Internet search engines work on similar principles and, from a technical point of view, consist of similar subsystems. The first structural part of the search engine - special programs, used for automatic search and subsequent indexing of web pages. Such programs are usually called spiders or bots. They look at the code of web pages, find links located on them, and thereby discover new web pages. There are also alternative way inclusion of the site in the index. Many search engines offer resource owners the opportunity to add a site to their database on their own. Be that as it may, then the web pages are downloaded, analyzed and indexed. Structural elements are highlighted in them, keywords are found, their links with other sites and web pages are determined. Other operations are also performed, the result of which is the formation of the index base of the search engine. This base is the second main element of any search engine. Currently, there is no one absolutely complete index database that would contain information about all the content of the Internet. Since different search engines use different web page search programs and build their index using different algorithms, search engine index bases can vary significantly. Some sites are indexed by several search engines, but there is always a certain percentage of resources included in the database of only one search engine. The fact that each search engine has such an original and non-overlapping part of the index allows you to make an important practical conclusion: if you use only one search engine, even the largest one, you will definitely lose a certain percentage of useful links.
The next part of the Internet search engine is the actual search and sorting program. These programs solve two main tasks: first, they find pages and files in the database that correspond to the incoming request, and then sort the resulting data array according to various criteria. The success in achieving the goals of the search largely depends on the effectiveness of their work.
The last element of an internet search engine is the user interface. In addition to the requirements for aesthetics and convenience that are usual for any site, there is another important requirement for search engine interfaces: they must offer various tools for compiling and refining queries, as well as sorting and filtering results. The advantages of search engines are excellent coverage of sources, relatively fast updating of the database content and a good choice additional features.
The main tool for working with search engines is a query.
For Internet search, special applications installed on the local computer are also used. These can be both simple programs and rather complex data search and analysis complexes. The most common browser plugins are browser plugins, browser panels designed to work with a specific search service, and metasearch packages with results analysis capabilities.
Web directories - these are resources in which sites are distributed by thematic categories. If the user works with search engines only through queries, then the catalog has the ability to view the entire thematic sections. The second fundamental difference between catalogs and automatic search engines is that, as a rule, people directly participate in their content, who view resources and attribute the site to one or another category. Web directories are usually divided into universal and thematic. Universal try to cover as many topics as possible. You can find anything in them: from sites about poetry to computer resources. In other words, they have the maximum search breadth. Thematic directories, on the other hand, specialize in a certain subject, providing the maximum depth of search by reducing the breadth of coverage of resources.
The advantage of directories is the relatively high quality of resources, since each site in it is viewed and selected by a person. Thematic grouping of sites allows you to conveniently locate sites of similar topics. This mode of operation is good for discovering new sites for you on a topic of interest - it is more accurate than using a search engine. It is recommended to use web directories for the first acquaintance with any subject area, as well as searching for fuzzy queries - you will have the opportunity to “wander” through the sections of the directory and more accurately determine what you need.
The disadvantages of web directories are known. First of all, this is a slow replenishment of the database, since the inclusion of a site in the catalog requires the participation of a person. In terms of efficiency, the web directory is not a rival to search engines. In addition, web directories are significantly inferior to search engines in terms of database size.
When talking about Internet search, one cannot ignore a number of terms that are closely related to this area and are often used to describe and evaluate search engines. For example: breadth and depth internet search. A broad search is a search that captures as many sources of information as possible. At the same time, at least a mention of a particular site that matches the query is considered sufficient. Search depth refers to the details of the indexing and subsequent search of each specific resource. For example, many search engines have different approaches to indexing different sites. Large and popular sites are indexed to the maximum extent, robots try not to miss a single page of such a resource. At the same time, on other sites, only the main page and a couple of pages of content can be indexed. These circumstances, of course, affect the subsequent search. Deep search works on the principle "it is better to include redundant information in the results than to miss out on any data relevant to the search topic."
It is quite common to come across concepts such as global and local internet search. Local Internet search takes into account the geographic location of the user and preference is given to results that are somehow related to a particular country or locality. A global search ignores this information and searches all available resources.
When compiling a query on Internet search engines, various modes search. Typical search modes found on most Internet machines include simple and advanced Search. Simple search allows you to specify only one search feature in one query. Advanced search makes it possible to create a query from several conditions by linking them with logical operators.
Various methods are used to refine search queries. filters . Filters are those or other auxiliary means of compiling a query that do not relate to the content side of the query conditions, but limit the search results to some formal sign. So, for example, when applying a file type filter when searching, the user does not provide the system with information related to the subject of his request, but simply limits the results obtained to a specific file type specified in the condition of his request.
For most users, universal search engines are the main, and often the only means of Internet search. They offer a good coverage of sources, as well as a set of tools sufficient for basic search tasks.
The market for universal search engines is quite large. We tried to analyze the most famous search engines, and the results are presented in the form of Table 1.
When choosing a universal search engine, the quality of the resources found with its help plays an important role. You can determine the preferred search engine for specific tasks using the “marker method”. Its essence lies in the fact that first a certain thematic search query is compiled, after which a group of people - experts in this field is polled to identify the best, in their opinion, Internet resources on the chosen topic. Based on the survey data, a list of marker sites is formed that are guaranteed to be relevant to the query and contain high-quality information. Then the request is sent to the tested search engines. The evaluation logic is simple: the higher the marker sites are located in the search results, the better a particular resource is suitable for finding information on a test topic.
Talk about what's in our time information technologies and the endless growth of the amount of data available both to an individual person and to society, there are many problems with processing information and searching for it - this is already blasphemy. Who only does not raise this topic. And in order not to load you with subjective and, in part, objective judgments gleaned from various information sources regarding the problem, I will proceed directly to its solution. Let's talk about search today. That is, about programs and serious information systems that search for the documents and data we need.
Upgrade "direct search"
Not so long ago, when the trees were large, and information even in local network there were not so many enterprises, any search was carried out by a banal enumeration of a handful of available files and a consistent check of their names and contents. Such a search is called direct, and programs (utilities) using direct search technology are traditionally present in all operating systems and tool packages. But, even the power of modern computers is not enough for a quick and adequate search in gigantic amounts of data during direct search. Searching through a couple of hundred documents on a disk and searching in a huge library and several dozen mailboxes are two different things. Therefore, direct search programs today are clearly fading into the background - if we are talking about universal tools.
Of course, in the corporate sector, this type of search has not been in demand for a long time. Volumes are not the same. And, therefore, for many years, and recently unequivocally, technologies capable of performing a quick and accurate search for documents various formats and from various sources, more than relevant. Not so long ago, Microsoft's "father" Bill Gates, envying, apparently, the phenomenal success of the Google Internet search engine, at one of the press conferences announced the desire of the software (already and not only) in every possible way to promote, develop and deepen the creation of search engines and technologies. But before the creation of any phenomenal working program from Microsoft or a competitive server on the Internet, it is still too early (MSN still falls short of Google). Therefore, we turn to existing developments. Index, query, relevance
At the core modern technologies there are two fundamental processes. Firstly, it is the indexing of the available information and the processing of the request, followed by the output of the results. As for the first, any program (be it a desktop search engine, a corporate information system or an Internet search engine) creates its own search area. That is, it processes documents and forms an index of these documents (an organized structure that contains information about the processed data). In the future, it is the created index that is used for work - quickly obtaining a list of necessary documents according to the request. Further, although by no means simple in terms of technology, but it is quite understandable ordinary user. The program processes the request (by keyword-phrase) and displays a list of documents that contain this keyword phrase. Since the information is contained in a structured index, the query processing is much (tens and hundreds of times!) Faster than in the case of a direct search (document selection is carried out not by enumerating files, but by analyzing textual information in the index).
The program displays the found documents in the resulting list according to relevance - the correspondence of the document to the query text. In various technologies, of course, there are various methods searching and determining the relevance of the document (the number of "occurrences" of the word and its frequency of mention in the document, the ratio of these parameters to the total number of words in the document, the distance between the words of the query phrase in the searched files, and so on). Based on these parameters, the "weight" of the document is determined and, depending on it, one or another file appears in the list of results at a certain position. In the case of Internet search, the situation is even more complicated. Indeed, in this case, many other factors must be taken into account (Page Rank Google is an example of this). But this is a topic for a separate article, so we will not touch the Internet. Overview of search engines
This article discusses the possibilities of several popular programs search, which can boast both decent speeds and good functionality. But showing off in a flyer is one thing, but standing up to an expert's gaze is quite another. And there were neither many nor few experts, a full office of lovers to tinker with software for its usability. On the test computer (Athlon 2.2 MHz, with random access memory 1 GB, 160 GB Seagate 7200 rpm IDE hard drive and Windows system XP) a set of programs was installed: dtSearch Desktop, Snoop Prof Deluxe, Google Desktop Search, SearchInform, Copernic Desktop Search, ISYS Desktop. For tests, a text base of documents was compiled in doc, txt and html formats with a total size of no more, no less, but 20 gigabytes. A group of comrades, under the guidance of your humble servant, tested, compared and shared their subjective impressions on each software. Read below for a summary of the findings. dtSearchDesktop
A program that, according to the developers, claims to be the fastest, most convenient and best search engine. As, in general, and all the rest of this review. The interface of dtSearch is quite simple, but some windows or tabs are somewhat overloaded with elements, which gives the impression of being difficult to use. But in fact, there are no special difficulties. The only really unpleasant moment is the lack of support for the Russian language software (despite the fact that the program can search for documents in several languages, its interface is exclusively English).
But dtSearch is one of the few programs that can index web pages to a "depth" specified by the user (however, taking into account the "additional purchase" in the dtSearch Spider add-on kit). This is in addition to supporting files on the disk of various text formats and emails from mailbox outlook. At the same time, the program does not know how to work with databases, which are such a tasty morsel for search engines due to the large amount of information they contain and the wide distribution in companies, and therefore in corporate networks. The indexing speed of dtSearch documents was up to the mark. Looking ahead, I’ll say that this program coped with indexing a given amount of information on a par with another contestant - iSYS - and shared second place with him in the list of the most fast systems. Test 20 gigabytes of information dtSearch indexed in 6 hours and 13 minutes, creating an index of 7.9 GB for the needs of subsequent search.
As for the search capabilities, they are up to the mark here. First, dtSearch has a morphological search (search for a word in all its morphological forms). Using this opportunity, you free yourself from, say, such thoughts as "in what case was a certain word used in the document I need?". The use of morphological search is almost always justified, so it should be present in any professional search engine.
Sound search is a non-standard feature even for professional searchers. Its essence lies in the fact that the program will look for words that sound the same as the word you entered. And the best part is, this feature works for the Russian language too! For example, typing the word "ear" in a search query will result in not only the words "ear", but also "ear".
Error-correcting search is a very important feature. It is used to search for words containing syntactical errors - these can be either typos or errors in documents obtained using character recognition systems, for example. A simple example is you are looking for the word keyboard. Some document contains the word "keyboard", it is obvious that in fact this word is "keyboard", just a person typing when typing. Now, error-correcting search, this will detect and include the document with the word "keyboard" in the result. Also in dtSearch there is a setting that allows you to determine the degree of possible erroneous characters.
Search using synonyms. This feature uses a list of synonyms for various words. So, for example, by entering the word "fast", the program will also find the words "high-speed" and others that are synonyms for the word "fast", if any, of course, are present in the list of synonyms. A ready-made list of synonyms is not supplied with the dtSearch program, however, it is possible to use the lists on the Internet (accordingly, a connection is required, which is not always convenient), or you can create your own list of synonyms.
In addition to the listed features, dtSearch can search using phrases consisting of words connected by logical operations. Each word in the query can be assigned its own "weight", that is, significance. A useful option is to use a dictionary consisting of unimportant words in order to ignore them when searching, but this dictionary is also empty and you will have to fill it yourself.
Next, consider the possibilities of the program when working on the network. In fact, dtSearch does not offer any specific networking capabilities. However, it is quite possible to use it on the network. Alternatively, you can create some index and put it in a public (shared) folder. The program itself can be installed for each user on a computer, or put it also on a folder open for public access, and create shortcuts in a special way for each user separately, using command line options, the purpose of which is described in the help file supplied with the program. Also, there is a possibility automatic installation programs to the network using an MSI file. This will take into account the settings for each connected user.
In general - a good program from the category of professional search engines. It may qualify for a good rating, however, gaining trust and respect from users may be difficult for dtSearch due to several factors (not everything is smooth with the interface, Russian users are deprived, there are no bright features for working with the network). As for the search for documents directly, the program did not have overlays with Russian text. As there were none with the declared morphology, or with a fuzzy search. The system quite adequately found the necessary documents both by a simple request in one word and by using a couple of paragraphs or any document as a key phrase.
Official site:
Distribution size: 23 MbSnoop Prof Deluxe
Based on the name, you can guess that there is support for the Russian language in this program. It's already nice. As for the interface, in general, it is somewhat unusual, but very attractive in appearance. Another thing is convenience. A very controversial criterion, but still, probably, a multi-window solution is not the best option (the request is entered in one window, the result is displayed in another, etc.).
The Bloodhound still uses the same indexes to perform fast searches, but indexing is much slower than other programs. This is very strange, especially considering that its ability to process search queries is very weak, which means that the index structure is not complicated. Most likely, the point here is in non-optimized algorithms. This program turned out to be a clear outsider of indexing and search speeds: the time spent on creating an index is six times longer than that of the same dtSearch and iSYS. Indexing 20 gigabytes of texts for a bloodhound resulted in 38 hours and 46 minutes of work. And the created "search area" occupied the same size on the hard disk as the original data with a small minus - 19 gigabytes.
Bloodhound can be presented as an alternative standard search on Windows, it can hardly do more. The fact that the primary task of the Seeker - the simplest search for files is indicated not only by a small number of functions for analyzing the text of search queries and an advanced search by file attributes, but even a results window that gives direct links to the found files, as well as to folders containing these files. The results window is not very informative in the sense that you can read the entire found file only by running it, that is, it does not have a built-in file viewer. But an excerpt from the file is given, where the searched word was found, in general, such a display scheme is very reminiscent of Internet search engines.
Speaking about the specific possibilities for processing search queries, it is worth noting that there is no such thing as "search for text", the maximum that can be searched is a phrase, if only because there is no multi-line text input field. However, you can also analyze the entered phrase, and the Bloodhound offers us a standard search set here: logical operations, search by mask and quotation search ... not a lot. There are some rudiments of morphological search in the program, but probably so raw that it rather interferes with correct work (during the tests, a lot of overlays with incorrect use of morphology were noticed).
But the program allows you to specify file attributes (document date, file name, folder name) when searching, and in these queries you can also use the same search set. Also, you can search for messages by specifying the parameters (From, Subject.... etc.).
So, we figured out the search itself, what else is interesting about the program, for which it received so many awards, according to information from the official website? It's hard to say what's so special about it, most likely, the Bloodhound's interface is conducive to itself (just outwardly, not to mention usability).
Operations with indexes are very standard, the nice thing is the ability to update indexes on a schedule. In addition, indexes can also be used online. From now on, we need to be more specific.
Despite the primitiveness of search queries, the program can be used to search for files, so its use can be justified in networks. Though with a big stretch, since in a large network the priority is to quickly search for data using complex search queries due to the huge amount of information - and there are clearly problems with the speed of the search and the program. I must say that the work with the network at the Bloodhound is thought out as it should. A separate application is designed specifically for this - Bloodhound Server. It works in the same way as just the Bloodhound (they have one search engine), only for documents hosted on a central server or on shared resources in corporate network. Bloodhound Server creates new indexes on shared resources or uses previously created ones. Any user on the corporate network can connect to the Bloodhound Server and use it to access any document (located in the current index) using an Internet browser. Agree, such a scheme is extremely convenient: it turns out that files on your own network can be searched in the same way as information on the Internet through, for example, Google.
Evaluating all the advantages and disadvantages of this program, the conclusion suggests itself that for corporate networks its capabilities will most likely not be enough (despite the good organization of networking), but for a home computer or even for a home network, it is, in principle , might fit. Although neither the speed of work, nor the search capabilities inspire optimism ...
Official website in Russian:
Distribution size: 6 MbGoogle Desktop Search + GDS Enterprise 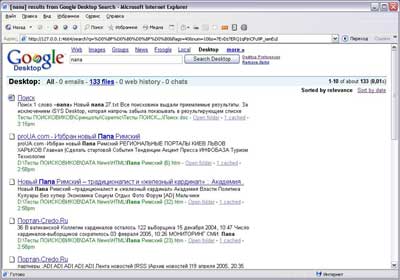
Of course, we could not ignore such an eminent developer. The name Google already speaks volumes. People who have been using the most powerful Internet search engine for years will probably decide to install this particular search engine on their computer without a single doubt. It's like thinking: Google on your home computer! However, without succumbing to provocations with a widely promoted brand, let's try to soberly, and most importantly objectively, consider the possibilities of the "desktop" search engine from Google.
The first thing that catches your eye is the lack of its own shell for the program. Google Desktop Search is still in the browser window, respectively, the entire interface of the desktop version went to the software from the older Internet brother. Whether this is good or bad is a moot point: someone likes the minimalism in the design of this search engine, and someone wants to see a full-fledged application filled with all sorts of buttons and so on.
What catches your eye right after the design? And the fact that this same Google Desktop Search starts indexing everything on the computer, without any demand for it! And what is most interesting, it is impossible to choose indexing paths using Google Desktop Search. You will have to download a separate program (TweakGDS), which will allow you to slightly expand google settings Desktop, including specifying the places necessary for indexing. Although, while you figure it all out, it will already index the standard hard drive, so this setting is needed more when working with large amounts of data, which is very important when used in corporate networks (Enterprise version). However, it is not a fact that after downloading TweakGDS, your problems will be solved. After all, it needs Microsoft . NET Framework and Microsoft Scripting Runtime. Yeah... the installation, as well as access to the settings, could have been made easier, although, probably, the developers can understand: why write something new when there is already a ready-made search engine, ported it to local computer and let the user "enjoy", and let the well-known name make another masterpiece out of "this". C'mon, let's finish this lyrical digression and move on to the search.
As for the analysis of search queries and the issuance of results, everything here is absolutely identical to Google on the Internet: the same system for displaying results, the same standard set of logical operations for search queries. In general, Google Desktop Search, like previous program, is designed exclusively for searching for files - of course, there is no internal viewer for these files. The number of file formats supported by Google Desktop Search is quite sufficient, and it's also nice that it searches the visited Internet pages, taking data from the cache. Search and indexing speeds are quite acceptable. True, for home use. With an impressive 20 gigabytes of texts, Google Desktop Search managed in 8 hours and 17 minutes. Spend a few days processing information from the corporate network of a large enterprise does not smile at any system administrator. On the plus side: the size of the created index turned out to be at the level (4.5 GB) with another search engine tested in this review - SearchInform.
A big advantage (or omission - you decide) of Google Desktop Search is that it supports plugins that can change a lot for the better. Another thing is that connecting plug-ins and configuring them complicates the task of installing a search engine so much that you start to wonder if all this is necessary when you can install a normal, full-fledged program in which everything will already be present. After all, to use each feature, you will have to install a new plugin. Even in order for the program to fully work with archives, a separate lotion is needed. It fascinates and seduces the free of charge of all these additional modules. However, if you do not take into account the desktop version of the search engine, then competently setting up GDS Enterprise may not be within your power - it's not in vain that Google specialists offer their services to set up their own software for your network for only $10,000.
If you nevertheless master the setup and installation procedure (or pay $ 10,000 to the Google quick response team), you will understand that the complexity of the installation is more than offset by very flexible settings when used in corporate networks. An important aspect of the work of Google Desktop in a corporate network is the use group policies, which makes it possible to set preferences for each user.
Summing up, it should be said that the most reasonable use for this program is a home or work computer. Indeed, for a regular computer, it is enough just to install the program - it will do the rest itself (it will not even ask you about anything).
However, Google Desktop Search Enterprise will be acceptable in cases where there is an urgent need for flexible network policy settings for using the search engine, while the ability to process search queries will be in second place in importance, and the time (or money) spent on setting up the program will come first. place.
Official site:
Distribution size with TweakGDS: 1.2 MbCopernic Desktop Search 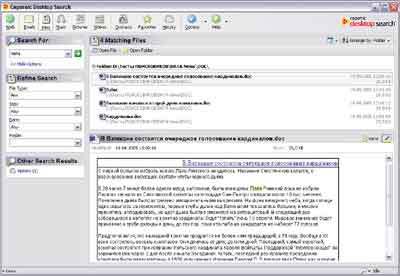
Click on the picture to enlarge
The interface of the program evokes extremely positive emotions - everything is done in accordance with generally accepted standards, nothing more, in a word, a pleasant design. It will be very easy for a beginner to understand the interface of Copernic Desktop Search. Although, it is somewhat embarrassing that the designers explicitly created the program's interface, taking into account the fact that the program will work in the standard Windows XP theme. When using the same classic theme, the program does not look so pretty. But this is more a matter of taste.
At the first start, the program offers to create indexes for searching. It seemed somewhat unusual that after selecting folders for indexing, the program does not offer to press any button, like "Start indexing", while indexing does not start automatically, only then it was noticed that Copernic tries to start indexing when the computer is idle. You will have to dig a little in the program options to set everything up properly. It should be noted that there are fairly wide options for customization. automatic creation index: built-in scheduler, the ability to index while the computer is idle, in the background, with low priority. Indexing was not too fast - 10 hours 51 minutes - this is slower than in other search engines (except for the Bloodhound, yet Copernic is an order of magnitude faster than the development of iSleuthHound Technologies.
Now about the structure of the index. In general, there is nothing special about it. It is possible to select file types, both in a generalized form and in a detailed one. That is, initially you can choose what you want to index - Documents, Images, Videos, Music. On the other tab of the options window, it will be possible to select specific file types by extension. Additionally, you can configure the index in such a way that, for example, pictures less than 16x16 in size are not indexed or sound files less than 10 seconds long are not indexed. In addition to indexing files from folders, Copernic can work with emails and contacts from the address book of Microsoft Outlook and Microsoft Outlook Express, it is possible to index Favorites and History from Internet Explorer.
As for the search capabilities, they are very weak here. During the tests, it was even revealed that the program does not search for documents in txt and html formats in Russian, allowing you to find them only by headings, and by no means by content. The only thing that the program provides to improve search efficiency is the use of standard set logical operations, and even then, this possibility was discovered experimentally, since it was not documented. By the way, the program's help is also not all right - it is available only via the Internet, which, you see, is very inconvenient, and there is not too much help information on the network. Apparently, the developers decided that the simple interface of the program does not imply the presence of normal help. Continuing the conversation about the search capabilities, it should be noted that, despite the poor analysis of queries, the program provides an interesting search system - the user can select the type of files (images, videos, music, etc.), enter a search query and select attributes that are specific to selected file type. For example, for sound files, these can be values from mp3 tags (artist, album, date, etc.), for images, for example, you can choose their size (by resolution), in general, each type has its own settings. After searching for a certain type of files, the program will display a very informative list in the results window, and if your request includes files of other types, you can open them by clicking on a specific link.
Separately, it is worth mentioning the result display window. The contents of these files are displayed below the list of found files (a similar scheme is often used in mail clients). True, text can be viewed only in its native format, and there is no plain text display mode, which is not always convenient, since opening a document in this case takes more time. But, given that Copernic can search for images and music, there is the possibility of viewing these multimedia files.
The basic principles of this program have been described, now let's see what Copernic Desktop Search can offer us for working with the network ... In principle, you can watch for a very long time, but you are unlikely to see anything. In other words, this program was not conceived as a network one. Copernic Desktop Search is exclusively a home search engine.
Obviously, the only (most logical) use of this program is home computer. Here, it will quite cope with all the simple search queries of users consisting of one or two words, find the necessary information, and the separation of the search by file type and support for multimedia files, along with background indexing in low priority mode, coupled with a pleasant interface, only give the program strength to gain trust among inexperienced users.
Official site
Distribution size: 2.6 MbISYS Desktop 
Click on the picture to enlarge
A very powerful program. In terms of the level of equipment with all sorts of functions, it is somewhere near the next SearchInform search engine in the list. At the same time, the size of the installation file is more than 40Mb! It's hard to say what could be stuffed into such sizes, because the same SearchInform, with similar functionality, takes 15Mb.
The installation process here is also not very pleasant, or rather not even the installation process. Even before downloading the program, you will be asked to register, otherwise - nothing. Next, the interface. It is made very nicely, nothing superfluous catches the eye, however, these are the impressions of a person who is already somewhat accustomed to him. It will not be easy for a beginner to figure out where and what is, where to click and where to finally search. It is highly recommended to read the help before starting work - save a lot of nerves and time. In addition to everything else, it is also complete absence Russian language support in the program. Not good. In addition, the windows here are not overloaded with controls, but this came at the cost of multi-module and the use of additional windows. For example, search queries are entered by running one program, and indexes are managed using another program. Search queries are also entered here in separate, appearing boxes. It's hard to say which is better - overloaded interface or ubiquitous multi-window, rather, it's a matter of taste.
As for creating indexes, the program provides options to simplify the process of setting options for a new index. These features include several ready-made templates to create indexes on My Documents, Mail, Mail and Documents, Specific Folder, Folder with Select File Types, etc. These templates make it easy to create indexes at the first stage. The utility for working with indexes has a not very good interface that scares off some complexity (this is a very subjective assessment, to be honest), but if you look at it, it provides many useful options and, in general, its use does not cause much difficulty. ISYS Desktop is able to index data from various data sources, and also provides many flexible settings for such indexing. Among additional features for indexing: support for SQL, FTP, TRIM Context, WORLDOX 2002, scripts. When creating an index, if you selected the "Folder with a choice of file types" option, you have the opportunity to select the types of files to be indexed manually (by extension). It must be said that there are simply a huge number of supported file types, but it will not be possible to add your own type (extension) to the existing list. You can also note the presence of an indexing scheduler. ISYS Desktop took 6 hours and 13 minutes to create an index and process 20 gigabytes of information, eventually showing a good time and the size of the created file - 7.9 GB.
The search capabilities of this program are not bad. What is used in ISYS is much more powerful than the usual support for logical operations. Of the advanced search features, the program offers the use of synonyms, sorting filter (by path, name and date of creation of the file). The set of logical operators is somewhat wider than the standard set. In addition to logical operations, the program allows you to work with many other operators that, in principle, can replace some types of search, for example, search with parsing can be completely replaced by using special operators. I was very surprised that the program does not have a search using morphology. This is a serious omission, since search efficiency is greatly improved when using morphological analysis. In addition, there is no list of significant words, but there is an extensive list of non-significant words. Also declared such functions in the search as "approximate search" and "heuristic analysis".
ISYS provides a choice of several types of search queries, namely visual ones. This is done using different types of windows for entering search queries, however, in fact, no window allows you to use technologies other than those listed above.
The search results are very informative, displayed as a list of documents sorted by relevance. Below is a preview of the selected document. Unlike Copernic Desktop Search, the preview here is available only in the form of plain text, it was not possible to achieve the display of documents in the native format, be it Word, Html or PDF, although in principle this is not too critical. The program allows you to divide the found documents into groups according to certain criteria (by default, they are divided by relevance). You can also view already found documents by selecting individual folders (this is useful when the result produces a very large number of documents).
Using the program in a corporate network is also quite justified, as it provides good opportunities for organizing network searches. The search system is based on the creation of a public index, which contains indexed data from public network resources.
In fact, the program from ISYS is worthy of attention, at least getting acquainted with it. This program is a mature project with huge amount functions (not always and not for everyone, of course, they are needed, but still). The chances that the program will have some improvements in terms of processing search queries are not known, but this moment it can be recommended for almost universal use. And given that it is still too heavy for home systems, the main places for its installation are corporate networks.
Official site:
Distribution size: 40 MbSearchInform 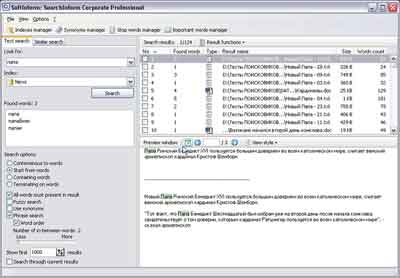
Click on the picture to enlarge
It's probably not worth starting right away with a description of the SearchInform interface. We should first describe the installation process, or rather one of its details: you will not be able to install the program without an Internet connection. The fact is that before the first launch, the program requires user registration (free of charge) and sends all the entered data to the server. Apparently, the developers had to take such measures in the fight against piracy, but this did not positively affect the ease of installation.
The program interface is made in compliance with all generally accepted rules, however, at first glance, it is somewhat cumbersome. Using the program for the first time, it seems that it is too complicated, sometimes it is not easy to remember which menu or tab the desired option is on, however, with longer use, the interface no longer seems so terribly complicated. The main thing is to read the help first.
Having dealt with the interface a little, you can start creating an index. The process itself is very simple and the indexing speed, even by eye, is much higher than all other search engines from the review. Clear test numbers show that SearchInform is twice as fast as dtSearch and iSYS in terms of indexing speed! The program indexed the provided data in the amount of 20 gigabytes in record time - 3 hours 17 minutes. And the size of the created index turned out to be the smallest 4.4 GB - 100 megabytes less than that of Google Desktop Search.
The program supports, in addition to regular files and folders, also indexing emails, connecting and indexing databases (!) And other external sources (DMS, CRM), immediately when indexing, you can specify a dictionary for morphological search, and all attributes can be indexed files. After creating an index, when trying to conduct the first test search for documents, you can come to some confusion: "there are two types of search, but which one do I need?". As mentioned earlier, the main thing is to read the help, then everything will become clear. The program is really able to perform two types of search - a phrase search and search for documents that are similar in content to the query text.
The description of all the main functions for analyzing a search query was given above, so now we will only list the search capabilities provided by this program. Let's start with phrase search: of course, morphological search, quotation search, logical operations, word parsing search (search by the beginning of the word, by the end, by the middle part, or a complete match), mixed quotation search (when all words from the query must be present in the document, but not necessarily in the order entered), error-correction search, use of synonyms, "almost quotation search" (search for the entered phrase as a quotation, but there may be other words between the entered words), etc. Some of the listed options have their own specific settings. In addition, it is possible to use a dictionary of insignificant words, and the program already has a ready-made list of these words, you can also use a dictionary of priority words for searching (of course, you will have to fill it out yourself).
Here, in principle, we briefly ran through all the main features of phrase search.
Let's move on to the consideration of the features of this program - the search for similar documents. The developers claim that this is by no means a simple text search, this is exactly a "search for similar" - that's how they describe it everywhere, but okay, you can call it whatever you like - the main thing is. A short Internet search can quickly reveal that the so-called "similar search" is a new development in the field of text analysis. This system allows you to find texts that are similar in terms of semantic content. The most pleasant thing was that after conducting test search queries, it turned out that the theory is quite consistent with practice! The program really searches for documents similar in content and displays them in a list, sorted by similarity percentage.
Next, let's look at what SearchInform offers (in particular, its corporate version SearchInform Corporate) for working in a corporate network. There are two types of applications: server side and user side. The server part independently processes the specified indexes, and users can use them for searching, depending on the access rights assigned to them. Users can be configured automatically using logins. Windows entries(saying professional language, SearchInform uses Windows NTFS authentication) or manually (users will have to be added separately). Each user can be allowed or denied access to certain indexes, you can also combine users into groups. In general, SearchInform's network settings are ahead of Google in terms of flexibility, and Snoop Server in terms of convenience and simplicity.
Official site:
Distribution size: 14.7 MbIndexing speed comparison
| Search system | Indexing time | Index size |
| Bloodhound Pro Deluxe 4.5 | 38 hours 46 minutes | 19 GB |
| Isys Desktop 7.0 | 6 hours 13 minutes | 7.9 GB |
| DtSearch 7.0 | 6 hours 3 minutes | 8.6 GB |
| Google Desktop Search Enterprise | 8 hours 17 minutes | 4.5 GB |
| Copernic Desktop Search* | 10 hours 51 minutes | 7 GB |
| SearchInform 1.5.02 | 3 hours 17 minutes | 4.4 GB |
* Most of the .html and .txt documents containing Russian text, although they were indexed, could not be found except by their names. Summary
All programs are worthy of attention.
Based on the tests and careful examination of each program presented in the review, certain conclusions can be drawn. So, Google Desktop Search Copernic Desktop Search is quite suitable for an inexperienced user as a home information search system. They do a good job with simple requests, do not load the user much with settings, and, moreover, are completely free. Google's attempt to enter the market of corporate search engines has not yet been strongly justified: for full-fledged work, the program needs to be hung with additional modules, and it is far from easy to set up. Therefore, speaking the names of Desktop Search, that Copernic, that Google leave behind them a niche of "desktop" search engines.
True, more powerful solutions - dtSearch, iSYS and SearchInform are also not out of the blue and offer users their "desktop" versions. But at a reasonable price, unlike free software from Google and Copernic. Of course, you have to pay for power, speed and functionality. But the developers of dtSearch, iSYS and SearchInform make their main focus, of course, on the corporate sector. Networking, functionality, indexing and search speed - that's what distinguishes these products from their "competitors". According to the results of the test, the favorite was determined - SearchInform. The program provides the ability to search for similar documents, has the highest indexing and search speed, and has a good set of functions.
Finding the right and up-to-date information on the Internet is sometimes very difficult. The amount of informational garbage on the Web is growing like a snowball, and sometimes it is simply impossible to get to the data that you really need using traditional Yandex and Google. The book that you hold in your hands will increase the efficiency of your search for information on the Internet many times over. It describes techniques, search sites and programs for specialized information retrieval. Modern varieties of Internet search are considered: universal search, vertical search, metasearch systems, building personal search engines, search for audiovisual content, search on the hidden Internet. For all the considered systems, their characteristics and tips for the most efficient use are given.
Introduction
Internet search is an important element of working on the Web. The exact number of web resources of the modern Internet is hardly known to anyone for sure. In any case, the bill goes into the billions. In order to be able to use the information that is needed at this particular moment, whether for business or entertainment purposes, you first need to find it in this constantly replenished ocean of resources. This is not an easy task at all, since the information on the modern Web is not structured, which creates problems in finding it. It is no coincidence that Internet search engines have become a kind of “windows” into this information space.
It is unlikely that among Internet users there will be people who have never used large universal search engines. The names Google, Yandex and a couple of other big machines are on everyone's lips. They do great with daily tasks Internet search, and often users do not even try to look for a replacement. At the same time, the number of Internet search engines in our time is in the thousands. The reasons for such a variety of alternative machines have various roots. Some projects are trying to compete directly with the leaders of the global market through careful work with national Internet resources. Others offer querying features not found in established search engines. A significant number of alternative machines specialize in searching for a particular subject area or a particular type of content, achieving impressive results in solving these problems. Be that as it may, the inclusion of such search engines in the user's own arsenal of Internet search tools can significantly improve its quality. Here, however, there is one nuance: you need to know about such machines and be able to use their capabilities.
We assume that the readers of this book are already quite familiar with the technique of searching using universal search engines. So good that they felt the limitations associated with their use. Most likely, such people have already tried to look for and apply certain additional tools. The printed word does not bypass the topic of Internet search: both articles periodically appear and books come out. But the heroes they have, as a rule, are the same - several leading universal search engines. Our book is different in that it attempts to cover the full range of modern search solutions. Here you will find descriptions and recommendations for using the best modern services focused on solving the most common search tasks. This book is for people who work a lot on the Internet and use the Web to find the information they need - whether it's business, study or a hobby.
In order for an Internet search to be successful, two conditions must be met: queries must be well formulated and they must be asked in suitable places. In other words, the user is required, on the one hand, to be able to translate their search interests into the language of the search query, and on the other hand, a good knowledge of search engines, available search tools, their advantages and disadvantages, which will allow choosing the most appropriate search tools in each specific case. .
Currently, there is no single resource that satisfies all the requirements for Internet search. Therefore, with a serious approach to the search, you inevitably have to use different tools, using each in the most appropriate case.
Chapter 1
Universal Internet search engines
Universal Internet search engines are the main and most well-known means of Internet search. Such search engines provide maximum coverage of various resources. It is the universal type that includes the largest and most popular search engines. These are really powerful solutions with a lot of features and tools that many users often do not know about. Understanding the features and capabilities of universal search allows you to find out the strengths and weak sides such systems and consciously choose the most effective search tools.
The market for universal search engines is quite large. In this chapter, we will consider only the most powerful machines that can adequately work with queries in Russian. The chapter opens with stories about the leaders of Russian search - Google.ru and Yandex systems. Books and a lot of articles have been written about each of these search engines. We will focus on the main characteristics that matter to the end user and also try to identify their strengths.
They are accompanied by a new search engine developed by Microsoft Corporation - the Bing system, which has so far been noticeably deprived of attention, as well as a useful and fairly powerful search engine Exalead, the advantage of which is good support search in European Internet resources. This system- is still a rare guest in the search arsenal of our users, so it is considered in more detail than the others.
In this chapter, when reviewing Google systems and Yandex, we will focus only on web search capabilities, and search in specialized databases of these projects is discussed in the following chapters on image and video search. For other universal search engines, information about multimedia search is given immediately upon acquaintance with them.
Since three of the four heroes of this chapter are of foreign origin, we note right away that we are only analyzing the possibilities of their Russian versions. The fact is that some functions of foreign systems, especially experimental ones, are often available only in the original, as a rule, English-language versions of services.
The Google search engine is deservedly considered the world leader in modern Internet search. Founded in 1998 Google to this day remains among the leading trendsetters in the field of Internet search and web services.
Google developers have always been distinguished by increased attention to improving the algorithms of their search engine, as well as reasonable conservatism in the field user interface. The possibilities of compiling a query on Google can be called classic, and the ways of displaying search results have also become a kind of standard. Recently Google Developers made major changes in these areas - the largest search engine began to look too old-fashioned against the background of young competitors.
Google has one of the largest index bases in the world, which provides a wide coverage of information sources. Google index information is summarized in several vertical bases. In addition to the most famous Web database, there are several multimedia databases (Pictures, Videos) that work with sources of relevant information and messages on RSS feeds, the News database, as well as the Blogs database that indexes network diaries. In addition, Google offers a wide range of additional resources, among which it is worth noting a map service, a directory of sites, and a question and answer service. These resources can also be thought of as search tools.
In the Web database, Google offers simple and advanced search modes for compiling a query. In the simple search mode, of the additional tools, only virtual keyboard. Advanced search offers more options. Since the advanced search form is available in almost all Google search products, let's dwell on it in more detail (Fig. 1.1).
Yandex
Officially presented to the general public in 1997, the Yandex search engine developed successfully and ten years later, for the first time, was among the ten largest search engines in the world. In the Russian segment of the Internet, he has achieved a leading position, which he is not going to give up, despite the growing competition. Distinctive features of Yandex since the beginning of its existence have been its own original algorithms for determining the relevance of search results, flexible tools for working with query text and taking into account the peculiarities of the morphology of the Russian language when processing them.
Yandex relies on its own index databases. In addition to searching through web documents, the system offers a good selection of specialized resources and additional services. Yandex currently works with images, videos, news, blogs and dictionaries. Powerful search capabilities are also embedded in our own cartographic service and in the product search system. In addition, Yandex maintains its own catalog of websites. Strong point Yandex is a developed local search program, which is especially important for our users. Yandex provides access to its databases to third-party developers. As a result, many Russian alternative Internet search projects use Yandex resources in one way or another. In addition to the usual search system, a shortened version of Yandex is also offered, available at ya.ru. The interface of this version consists only of a query input field and a search start button.
Web document search offers both simple and advanced search modes. Simple search does not provide any filters, which is compensated by the ability to automatically parse natural language queries, confident processing of relatively long queries, and an automatic query completion system. The maximum query length is forty words.
The advanced search form for composing a query offers only one field. Logical operators linking query words are suggested to be entered manually, good. Yandex has a fairly detailed query language. The rest of the advanced search form tools are various filters (1.4).
bing
Internet search history from Microsoft is not easy to call. The services consistently offered to the public have repeatedly changed the algorithms, databases used and, of course, the names. Until the early 2000s, the search engine did not have its own databases and worked with external indexes from AltaVista, Inktomi and Looksmart. The original name MSN Search was used until 2006, and then for several years changing the names of the search engine became a tradition for Microsoft.
Along with the final transition to search in its own indexes, MSN Search was renamed first to Windows LiveLive Search. Finally, in the early summer of 2009, Live Search was replaced by the new Bing search project.
"Bing will provide a different way of looking at information on the Internet and will help users make important decisions," Microsoft's press release on the launch of Bing began with such a statement. The aspirations of the developers were understandable: search engines from Microsoft, despite all efforts, in the West were consistently inferior in popularity to the leaders - Google and Yahoo!. If we talk about the Russian-language versions of previous Microsoft search projects, then in terms of the number and quality of the links found, they were much inferior to the large Russian search engines. In an attempt to catch up with competitors, Bing developers have relied on improving the quality of search and the introduction of new technologies, many of which were acquired along with the firms that created them.
It should be noted that Russian version Bing, like most other localized versions, lacks a number of additional features, such as store search. Since they, in fact, work only in the North. America, it makes no sense to dwell on them in detail.
Exalead
One of the features of Europe, including in the field of Internet search, is a large number of national languages. A search engine that claims to be the leader in Europe is simply obliged to index the national segments of the Internet well and to process queries in numerous European languages, both the largest and the less common ones, with high quality. It is in this area that European development can receive serious competitive advantage compared to powerful overseas competitors. The Exalead system is currently seriously claiming the role of such a European search engine. This project was developed as part of the Quaere research program funded by the European Union.
Exalead has its own index databases. The main search resources of the system are databases of web documents, images, videos and news. start page Exalead offers the opportunity personalization. On this page, you can place links to your favorite sites - they will be displayed as graphic thumbnails-screenshots. True, for this you will have to register an account for free, as well as allow the browser to store Exalead cookies.
Exalead Web Search offers simple and advanced search modes. The advanced search form, like in Bing, opens directly on the issuance page Note that Exalead offers not just a familiar form with a set of additional fields, but a complex drop-down menu that acts as a wizard to refine the query (Fig. 1.7). When you select one or another item in the wizard menu, new elements are added to the query string, and, if necessary, operators and special characters.
Introduction
Currently, the Internet unites hundreds of millions of servers that host billions of different sites and individual files containing various kinds of information. It's a giant repository of information. There are various methods of searching for information on the Internet.
Search by known address. The required addresses are taken from directories. Knowing the address, just enter it in address bar Browser.
Example 1. www.gov.ru - the server of the state authorities of Russia.
Address construction by the user. Knowing the Internet address generation system, you can construct addresses when searching for Web sites.
It is necessary to add a thematic or geographical domain to a keyword (the name of a company, enterprise, organization or a simple English noun), and intuition must be connected.
Example 2 Commercial Web Page Addresses:
www.samsung.com SAMSUNG),
www.mtv.com (MTV music news).
Example 3. Addresses of educational institutions:
www.ntu.edu (US National University).
Search engines Internet
To search for information on the Internet, special information retrieval systems have been developed. Search engines have a regular address and are displayed as a Web page containing special tools for organizing search (search string, subject catalog, links). To call a search engine, just enter its address in the address bar of the Browser.
According to the statistics service LiveInternet.ru, the distribution of search engines in Russia is approximately the following:
2) Google - 35.0%
3) Mail.ru search - 8.3%
4) Rambler - 0.9%
According to the method of organizing information, information retrieval systems are divided into two types: classification (rubricators) and dictionary.
Rubricators (classifiers)- search engines that use a hierarchical (tree-like) organization of information. When searching for information, the user looks through thematic headings, gradually narrowing the search field (for example, if you need to find the meaning of a word, then first you need to find a dictionary in the classifier, and then find the right word in it).
Dictionary search engines are powerful automatic software and hardware systems. With their help, information on the Internet is viewed (scanned). Data on the location of this or that information is entered into special reference books-indexes. In response to the request, a search is performed in accordance with the query string. As a result, the user is offered those addresses (URLs) where the searched word or group of words was found at the time of scanning. By selecting any of the proposed links, you can go to the found document. Most modern search engines are mixed.
The most famous and popular search engines:
There are systems that specialize in searching information resources in various directions.
https://my.mail.ru
https://ru-ru.facebook.com
https://twitter.com
https://www.tumblr.com
https://www.instagram.com etc.
Subject search engines:
Software search:
Catalogs (thematic collections of links with annotations):
http://www.atrus.ru
Query Execution Rules
In each search engine, in the Help section, you can get information on how to search, how to compose a query string. Below is information about a typical, "average" query language.
Simple Request
Enter one word that defines the search topic. For example, in the Rambler.ru search engine, it is enough to enter: automation.
Documents are found that contain the words specified in the request. All forms of Russian words are recognized, as a rule, the case of letters is ignored.
You can use the character "*" or "?" in the query. Sign "?" in the keyword, one character is replaced, which can be replaced by any letter, and the character "*" is a sequence of characters.
For example, a query automaton* will find documents that include the words automatic, automatic, and so on.
Complex query
Often there is a need to combine keywords for more specific information. In this case, additional linking words, functions, operators, symbols, combinations of operators separated by brackets are used.
For example, the query music & (beatles beatles) means that the user is looking for documents containing the words music and beatles or music and beatles.
List of search servers and directories
| Address | Description | |
| www.excite.com | Search engine with node reviews and guides | |
| www.alta-vista.com | Search server, advanced search capabilities available | |
| www.hotbot.com | search server | |
| www.ifoseek.com | Search Server (easy to use) | |
| www.ipl.org | Internet Publik library, a public library operating as part of the World Village project | |
| www.wisewire.com | WiseWire - organization of search using artificial intelligence | |
| www.webcrawler.com | WebCrawler - search server, easy to use | |
| www.yahoo.com | Web catalog and interface for accessing full-text search on the AltaVista server | |
| www.aport.ru | Aport - Russian language search server | |
| www.yandex.ru | Yandex - Russian-language search server | |
| www.rambler.ru | Rambler - Russian-language search server | |
| Internet Help Resources | ||
| www.yellow.com | Internet Yellow Pages | |
| monk.newmail.ru | Search engines of various profiles | |
| www.top200.ru | Top 200 Websites | |
| www.allru.net | ||
| www.ru | Catalog of Russian Internet resources | |
| www.allru.net/z09.htm | Educational Resources | |
| www.students.ru | Russian student server | |
| www.cdo.ru/index_new.asp | Distance Learning Center | |
| www.open.ac.uk | Open University UK | |
| www.ntu.edu | US National University | |
| www.translate.ru | Electronic text translator | |
| www.pomorsu.ru/guide.library.html | List of links to net libraries | |
| www.elibrary.ru | Scientific electronic library | |
| www.citforum.ru | E-library | |
| www.infamed.com/psy | Psychological tests | |
| www.pokoleniye.ru | Internet Education Federation website | |
| www.metod.narod.ru | Educational Resources | |
| www.spb.osi.ru/ic/distant | Distance learning on the Internet | |
| www.examen.ru | Exams and tests | |
| www.kbsu.ru/~book/ | Computer science textbook | |
| Mega.km.ru | Encyclopedias and dictionaries | |
Professional search for information on the Internet
Information search is one of the most common and at the same time the most challenging tasks that any user has to deal with on the Web. However, if for an ordinary member of the network community, knowledge of effective information retrieval methods is a desirable, but far from obligatory quality, then for information professionals, the ability to quickly navigate the Internet resources and find the required sources is one of the basic qualification skills.
The reason for the difficulties that arise in information retrieval on the Internet is determined by two main factors. First, the number of sources on the Web is extremely large. At the end of 2001, the most rough estimates indicated an approximate figure of 7.5 billion documents located on servers around the world. Secondly, the amount of information on the Web is not only colossal in volume, but also extremely dynamic. In the half minute that you spent reading the first lines of this section, about a hundred new or changed documents appeared in the virtual universe, dozens were moved to new addresses, and units ceased to exist forever. The Internet never "sleeps", just as our planet never "sleeps", along which a wave of human business activity rolls continuously in exact accordance with the change of time zones.
Unlike a stable and controlled collection of documents in a library, on the Web we are dealing with a gigantic and constantly changing information array, the search for data in which is a very, very complex process. The situation is often very reminiscent of the well-known task of finding a needle in a haystack, and sometimes information of great value remains unclaimed solely because of the difficulty of finding it.
Most of the users of global computer networks. Both amateurs and professionals often use the same tools. However, the results of the searches and the time spent on them differ to a very large extent.
The purpose of this section is to get acquainted in detail with the tools and methods of information retrieval and develop sustainable skills for professional search on the Web of all types of data: from texts in any format to video and animation.